
Jahariah Sampe
Department of Electrical and Electronics System, Faculty of Engmeenng,
National University of Malaysia, 43600, Malaysia
Masuri Othman
Institute of Microengineermg and Nanoelectronic (IMEN),
National University of Malaysia, 43600, Malaysia
Journal of Applied Sciences
Year: 2008 | Volume: 8 | Issue: 7 | Page No.: 1315-1319







ABSTRACT
This study presents a proposed Fast Detection Anti-Collision Algorithm (FDACA) for Radio Frequency Identification (RFID) system. Our proposed FDACA is implemented on-chip using Application Specific Integrated Circuit (ASIC) technology and the algorithm is based on the deterministic anti-collision technique. The FDACA is novel in terms of a faster identification by reducing the number of iterations during the identification process. The primary FDACA also reads the identification (ID) bits at once regardless of its length. It also does not require the tags to remember the instructions from the reader during the communication process in which the tags are treated as address carrying devices only. As a result simple, small, low cost and memoryless tags can be produced. The proposed system is designed using Verilog HDL. The system is simulated using Modelsim XE II and synthesized using Xilinx Synthesis Technology (XST). The system is implemented in hardware using Field Programmable Grid Array (FPGA) board for real time verification. From the verification results it can be shown that the FDACA system enables to identify the tags without error until the operating frequency of 180 MHZ. Finally the FDACA system is implemented on chip using 0.18 μm Library, Synopsys Compiler and tools. From the resynthesis results it shows that the identification rate of the proposed FDACA system is 333 Mega tags per second with the power requirement of 3.451 mW.
PDF Abstract XML References Citation
How to cite this article
Jahariah Sampe and Masuri Othman, 2008. Fast Detection Anti-Collision Algorithm for RFID System Implemented On-Chip. Journal of Applied Sciences, 8: 1315-1319.
DOI: 10.3923/jas.2008.1315.1319
URL: https://scialert.net/abstract/?doi=jas.2008.1315.1319
DOI: 10.3923/jas.2008.1315.1319
URL: https://scialert.net/abstract/?doi=jas.2008.1315.1319
INTRODUCTION
The Radio Frequency Identification (RFID) system consists of three main components reader, tag and data management software is shown in Fig. 1. The reader is to write instructions to and to read data from the tags. The tags are to store data or unique identification (ID) numbers and are basically attached to the objects to be identified.
A collision occurs when multiple tags in the reading zone (magnetic/electromagnetic field) of the reader simultaneously respond to the reader’s commands. The reader will receive mixture of signals and this would lead to wrongly identify the tags. In order for reader to communicate with these multiple tags, anti-collision technique is required to coordinate the communication between the reader and the tags. These anti-collision techniques are classified into two; the stochastic/ probability and the deterministic techniques. The common stochastic techniques are based on the Aloha algorithm such as the Aloha, the slotted Aloha and the frame slotted Aloha (Law et al., 2000; Myung and Lee, 2006; Zhai and Wang, 2005; Singh, 2006). In this technique, the tags avoid collisions by responding to reader command at random intervals. If collision occurs, the affected tags will wait for another random interval before responding again. This will cause tag starvation or longer waiting before the tag can be responded again. In this technique also the tags will control the communication with the reader. The common deterministic technique is based on the Tree algorithm such as the Binary Tree and the Query Tree algorithms (Finkenzeller and Waddington, 2003; Auto-IDCenter, 2003; Zhou et al., 2003, 2004).
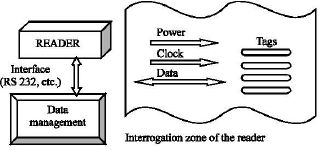 | |
| Fig. 1: | RFID system |
In the Binary Tree algorithm, the identification process will first search the smallest tag’s ID until the largest tag’s ID follows the Binary Tree sequence. Since this algorithm is a deterministic anti-collision technique, the reader will control the communication between tags. As a result enable production of tag with simple, small, low cost and low power features. Meanwhile from the Matlab simulation results, it shows that there are two limitations of the Binary Tree algorithm. Its identification time is dependent on two parameters; the number of tags simultaneously exists in the interrogation zone and the length of tag’s ID. If either one of these parameters is increased the identification time will increase. This algorithm also requires the tags to remember the previous instructions from the reader during the communication process. Application Specific Integrated Circuit (ASIC) approach is used to achieve the high performance demands in which software fails to deliver. Hence, the development of the FDACA system on chip is to achieve higher identification rate with low power requirement. In addition, the Field Programmable Grid Array (FPGA) is used as hardware platform for functional verification in real time.
FDACA ARCHITECTURE
Based on the Binary Tree anti-collision algorithm, the primary Fast Detection Anti-Collision Algorithm (FDACA) is proposed. The proposed primary FDACA is novel in terms of faster identification time by reducing the number of iterations needed to identify one tag. The powered tags are divided into a group of four for every read cycle in order to reduce the number of iterations during the identification process. In addition, the identification time of the proposed primary FDACA does not depend on the length of the tag’s ID. Instead of sending and receiving the ID bit by bit, the FDACA will read all the ID bits at once regardless of its length. This is performed by using the word-by-word multiplexing or byte interleaving. Meanwhile, this algorithm also does not require the tags to remember the previous instructions from the reader during the identification process. The reader transmits the read command to the tags and the tags will simultaneously backscatter its’ ID bits. As a result the tag is treated as an address carrying device i.e., the tag only carries its identification bits. Therefore, the memoryless tag which exhibits very low power consumption can be produced. During the identification process, the primary FDACA system will identify four tag’s IDs simultaneously in one read cycle. The primary FDACA will firstly identify the smallest ID bits and finally the largest one follows the two levels Binary Tree with a maximum number of four leaves. This on chip implementation of FDACA system is designed using top-down approach.
The FDACA system is based on a Time Division Multiplexing (TDM) operation. Therefore three parameters are used to measure the performance of the FDACA system; the maximum data rate (N), the length of ID bits (n) and the number of supported input/output lines (L). The identification time for FDACA system is same regardless of the length of the tag’s ID and equal to one System clock cycle (T). Therefore, the relationship between the maximum data rate (N), the length of ID bits (n), the access time (tacc) and the number of input/output lines (L) is given by Zahedi (2002).
| (1) |
In order to increase the throughput of the primary FDACA system, the number of input/output lines (channels) should be increased. But from Eq. 1, it shows that if the data rate increases, the number of supported lines will be decreased and vice versa. Therefore, to increase the number of lines supported by the FDACA system per read cycle without decreasing the maximum data rate, a few primary FDACA modules should be multiplexed.
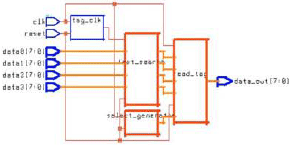
FDACA modules: The FDACA system consists of one Top module and five submodules as shown in Fig. 2. This Top module consists of the Data-generator module, the two Clock-divider modules, the two Fast-search modules, the Select-generator module and the Read-tag module. All these modules are synchronized to a system clock. The FDACA system has been designed using Verilog HDL. The system has also simulated using Modelsim XE II and synthesized using Xilinx Synthesis Technology (XST).
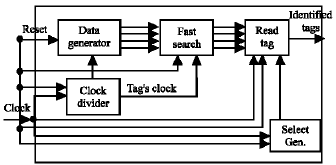 | |
| Fig. 2: | Modules of FDACA sysem |
Data-generator module is to generate random tag’s ID bits with any lengths for examples eight bits ID and sixteen bits ID. For every cycle of tag clock, four tag’s IDs will be simultaneously generated for identification. This module is only required for implementing the system into FPGA. Clock-divider module is to provide clock for Data-generator and Fast-search modules. This clock is called the Tag clock and its period is equal to four times the system clock period. One cycle (a period) of the Tag clock is used to identify four tags simultaneously and is called Read cycle.
The Fast-search module is the heart of FDACA system. It is based on the TDM operation. In this module the tags’ ID will be manipulated in such a way that there is no collision between them. For every cycle of tag clock, the search process will start by loading the four tag’s IDs into four arrays of register. Then the comparators will compare these tag’s IDs. The search process is performed by two ICs which use the conditional statements (if-else) for the left and the right branches of the tree respectively. The four identified tag’s IDs are loaded simultaneously into the output registers at the negative edge of the tag clock. All these loading processes are through the high speed multiplexing line. The maximum data rate N can be supported on each input/output line of this module is determined using Eq. 1.
The Read-tag module is partially based on the TDM operation. Each input data stream is connected to the input registers which store the incoming data from the Fast-search module. When this module is connected to the output of an input register, the contents of this register are rapidly downloaded through the high speed multiplexing line at every cycle of the system clock. Then the Read-tag module will display the four identified tags serially; one tag for every system clock cycle starts from the smallest tag’s ID until the largest one. The select signals of this module are generated by the select-generator module. The top module is used to implement the FDACA system in hardware using FPGA. Function of this module is very similar to the Read-tag Module but is modified to suit the hardware requirements.
SIMULATION RESULTS
Verilog HDL codes for the FDACA system have been successfully simulated and verified using the ModelSim XE II/Starter 5.7 g tool. Every FDACA module has been tested on its individual testbench. The FDACA modules have also been simulated and verified at each level of the simulation categories. The following will discuss the output waveforms of the Behavioral simulation for the selected modules of the FDACA system.
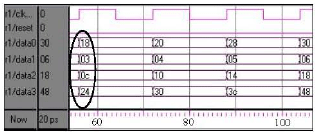 | |
| Fig. 3: | Output waveform from data-generator module |
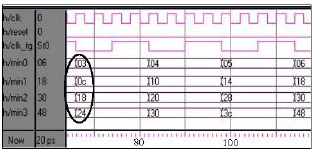 | |
| Fig. 4: | Output waveform from fast-search module |
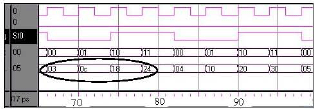 | |
| Fig. 5: | Output waveform from top module |
In Data-generator module, four tag’s IDs will be simultaneously generated at every positive edge of tag clock. For example from Fig. 3, tag’s IDs 1816, 0316, 0C16 and 2416 are simultaneously generated for identification. These tag’s IDs will be identified in the Fast-search Module. This module will search the tag’s IDs from the smallest value to the largest one. At every negative edge of the tag clock, four tag’s IDs will be identified and stored into four registers. For example the input tag’s IDs 1816, 0316, 0C16 and 2416 at Fig. 3 are identified as 0316, 0C16, 1816 and 2416 accordingly as shown in Fig. 4.
The output of the Top Module is shown in Fig. 5 which displays the output from the Fast-search module serially, four IDs for every Read cycle. For example during the first Read cycle, the tags with IDs 0316, 0C16, 1816 and 2416 will be displayed serially as marked by the first circle. Then for the next Read cycle, the tags with ID 0416, 1016, 2016 and 3016 will be displayed serially etc.
IMPLEMENTATION AND VERIFICATION
The FDACA system was implemented in hardware using FPGA model Virtex II Xc2v250 for real time verification. This verification is important in order to verify the functionality of the FDACA system in real application. In this process the output waveforms from the FPGA were displayed using Tektronix Logic Analyzer model TLA 5201 as shown in Fig. 6.
Figure 7 shows the tag’s IDs were identified at the operating frequency of 90 MHz. The output shows the identified tags for two tag clock cycles as marked by two circles. For each cycle of tag clock the tag was identified from the smallest ID to the largest ID value. For examples the identified tags of the first Tag clock cycle are 2016, 4016, 6016 and 8816 as marked by the first circle. Then, the identified tags of the second Tag clock cycle are 2416, 4816, 6C16 and 8916 as marked by the second circle etc. These results were verified the Behavioral simulation results at the previous section. The verification results also show that the FDACA system enable to identify the tags up to the operating frequency of 180 MHz without error. This is the maximum frequency of the Virtex II model which currently use.
Therefore, the FDACA system has been successfully implemented in hardware with the desired performances. Finally, the system was implemented on chip using the ASIC approach.
 | |
| Fig. 6: | FPGA implementation and verification platform |
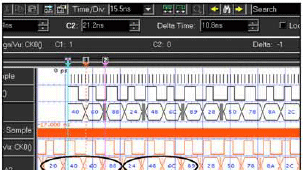 | |
| Fig. 7: | 90 MHz output waveform of the logic analyzer |
 | |
| Fig. 8: | Synthesized block diagram of FDACA system |
| Table 1: | Input and output parameters of the synthesis |
 | |
In this approach the system was resynthesized using synopsys compiler, design vision tools and 0.18 μm library. The most critical step in this approach is to determine the design constraint parameters of the FDACA system. These constraint parameters should ensure that there are no constraints will be violated. The timing parameters should also ensure that the obtained slack is the minimum value. The synthesized block diagram of the system is shown in Fig. 8.
Table 1 shows the design constraint parameters using the worst operating conditionsss and high effort mapping. These input parameters were met the design constraints. The other synthesis results are shown on the table. The system clock period is 3 ns which gives the best slack value of 0.27 ns. The identification time of the FDACA system is equal to one period of the system clock. As a result, the identification rate of the FDACA system implemented on chip is 333 Mega tags per second. The total required power by the system is 3.45 mW for the capacitive load of 2 pF.
CONCLUSION
The proposed Fast Detection Anti-Collision Algorithm (FDACA) is presented to minimize the identification time for the deterministic anti-collision technique. Also the proposed FDACA architecture enables the production of tag with small, simple, low cost and low power features. The proposed FDACA system has been simulated using Modelsim XE II and synthesized using XST. The system has also been implemented in hardware using FPGA Virtex II Xc2v250 for real time verification. The system is implemented on chip using Synopsys tools and 0.18 μm Library. The synthesis results show that the identification rate is 333 Megatags per second with power requirement of 3.45 mW.
REFERENCES
- Myung, J. and W. Lee, 2006. Adaptive binary splitting for efficient RFID tag anti-collision. IEEE Commun. Lett., 10: 144-146.
Direct Link - Zhai, J. and G. Wang, 2005. An anti-collision algorithm using two-functioned estimation for RFID tags. Proceedings of the International Conference on Computational Science and its Applications, Singapore, LNCS 3483, May 9-12, 2005, Springer, Berlin/Heidelberg, pp: 702-711.
Direct Link - Zhou, F., D. Jing, C. Huang and H. Min, 2003. Optimizing the power consumption of passive electronic tags for anti-collision schemes. Proceedings of the 5th International Conference on ASIC, October 21-24, 2003, IEEE Xplore London, pp: 1213-1217.
Direct Link - Zhou, F., D. Jing, C. Huang and H. Min, 2004. Evaluating and optimizing power consumption of anti-collision protocols for applications in RFID systems. Proceedings of the 2004 International Symposium on Low Power Electronics and Design, August 9-11, 2004, ACM., New York, USA., pp: 357-362.
CrossRefDirect Link
ARJUNA MARZUKI Reply
I cannot see the 'on chip' work. Maybe the authors could relate the info to me?