
P. Prakasam
Centre for Advanced Research, Department of Electronics and Communication Engineering, Muthayammal Engineering College, Rasipuram 637 408, Tamilnadu, India
M. Madheswaran
Centre for Advanced Research, Department of Electronics and Communication Engineering, Muthayammal Engineering College, Rasipuram 637 408, Tamilnadu, India
Journal of Applied Sciences
Year: 2008 | Volume: 8 | Issue: 1 | Page No.: 112-119







ABSTRACT
In this study, a modulation identification algorithm for identifying M-ary Shift Keying is developed and described using wavelet Transform to examine histogram peak and 8th order statistical moment. The simulated results show that the exact modulation scheme can be identified for lower SNR. The performance was examined for Additive White Gaussian Noise (AWGN) channel based on the confusion matrix, throughput of the algorithm and the Receiver Operating Characteristics (ROC). When SNR is above 3 dB, the probability of detection is proved to be more than 0.984. The parameters of the developed algorithm has been compared with existing algorithms and found that the proposed algorithm can be considered to be the suitable identification method for M-ary Shift Keying with lower SNR (signal-to-noise ratio).
PDF Abstract XML References Citation
How to cite this article
P. Prakasam and M. Madheswaran, 2008. M-ary Shift Keying Modulation Scheme Identification Algorithm Using Wavelet Transform and Higher Order Statistical Moment. Journal of Applied Sciences, 8: 112-119.
DOI: 10.3923/jas.2008.112.119
URL: https://scialert.net/abstract/?doi=jas.2008.112.119
DOI: 10.3923/jas.2008.112.119
URL: https://scialert.net/abstract/?doi=jas.2008.112.119
INTRODUCTION
The identification of digital modulated signals is one of the important tasks in the field of mobile communication in general, Software Defined Radio (SDR) in particular. This has motivated the researchers to develop various digital modulation identification algorithms in the recent past (Enrico Buracchini, 2000). As the adaptive receiver can communicate with different communication standards like TDMA, CDMA and GSM, the identification of digital modulation type of a signal has to be optimized for their effective usage. The signal identification process is an intermediate step between signal reception and demodulation for characterizing signals in various communications applications including spectrum management, surveillance, electronic warfare, military threat analysis. Several identification algorithms have been reported so far (Azzouz and Nandi, 1996; Beran, 1997; Druckmann et al., 1998; Yu et al., 2003). Generally, two basic approaches in the identification problem as decision-theoretical and statistical pattern recognition (Nolan et al., 2002). The decision-theoretical approach is based on hypothesis testing for sourced hypotheses conditioned to a finite set of known candidate signals. The pattern recognition approach usually consists feature extraction, reduction of the feature space and classification based on the lower dimension feature space.
One of the basic feature extraction methods for identifying the non-stationary signals is time-frequency analysis, particularly the Wavelet Transform (WT). Lin and Jay Kuo (2002) have reported that the phase changes can be examined using Morlet wavelet and the likelihood function based on the total number of detected phase changes can be used to classify M-ary PSK signal. One of the most complex and important identifier was introduced by Hong and Ho (1999). They applied the Haar WT and statistical decision theory to identify the M-ary Phase Shift Keying (MPSK), M-ary Frequency Shift Keying (MFSK) and QAM signals containing Additive White Gaussian Noise (AWGN) without base-band filtering. Binary PSK/CPFSK and MSK identification was investigated by Radomir Pavlik (2005) and complex Shannon wavelet was applied to identify the modulation schemes. The investigation was focused primarily on the identification of binary modulation signals under constant envelope class and it fails to identify the non-constant envelop modulation schemes. Automatic Modulation Identification (AMI) algorithm was developed to classify QPSK and GMSK signals with simulated Additive White Gaussian Noise (AWGN) channel by Prakasam and Madheswaran (2007). The extracted transient characteristics and histogram peaks were used to identify the modulation scheme.
This study proposes the modulation classification algorithm considering the AWGN channel to identify most of the M-ary Shift Keying modulation schemes. The wavelet transform, normalized histogram peak were applied for identification. Also, the various higher order statistical moments based decision was considered to compare. The performance analysis of the proposed algorithm was carried out and compared with reported algorithms. The confusion matrix, throughput analysis and Receiver Operating Characteristics (ROC) were carried out to measure the correct identification capability of the proposed algorithm.
MATHEMATICAL MODEL
Let the received waveform r(t), 0≤t≤T be described (Haykin, 2005) as:
| (1) |
Where, s(t) is transmitted signal and n(t) is the additive white Gaussian channel noise. The signal s(t) can be represented in complex form as:
| (2) |
Where, ωc is the carrier frequency and θc is the carrier phase. The analysis technique is required for non-stationary signal, which will analyze the signal frequency with time instants of occurring. The Fourier transform approach gives either the frequency components or time components. The wavelet transform has the special feature of Multi-Resolution Analysis (MRA), which provides the information in both frequency and time instants. The Continuous Wavelet Transform of a signal s(t) is defined (Chan, 1995) as:
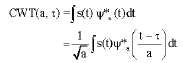 | (3) |
Where, a is the scaling factor and τ is the translation factor. The function ψ*a(t) is the complex conjugate of mother wavelet.
Generally, the complex envelope of s(t) in Eq. 1 may be expressed for all modulation types as:
| (4) |
Where, φ(t;a) represents the time-varying phase of the carrier, a represents all possible values of the information sequence {ak}. In the case of binary symbols ak = ±1. From Eq. 2, 3 and 4, the resulting integral of C(a, τ) is obtained as:
| (5) |
Where:
![]()
is the exponential integral and y = -jt(2πf-2πfc). |
Classification of GMSK and M-ary FSK with M-ary PSK and M-ary QAM: The normalized histogram peak of Wavelet transformed coefficient is used to classify the Class I (GMSK and M-ary FSK) with Class II (M-ary PSK and M-ary QAM) signals. If nk is the number of occurrence in a particular value then the normalized histogram (probability of occurrence) of a process is given by:
| (6) |
Where, n is total number in the particular process. This factor is applied to measure the probability of occurrence of the frequency components present in the incoming signal. Class I has multi-frequency component and multiple peaks in its normalized histogram. But the Class II signal has constant transient characteristics and a single peak in its normalized histogram. Based on the histogram peak, the either Class I or Class II modulation scheme has been identified.
Sub classification of class I: The classification of various modulation schemes may be formulated using the statistical parameters such as moments and median. The higher order statistical moment plays the major contribution in non-stationary signal. Thus it has been considered for the classification of non-stationary signals. The nth order moment for p(xi), where i = 0,1,2,…N-1 is given by
| (7) |
Where:
is the mean of the statistical process. The second order moment (variance) of Wavelet Transform can be computed using:
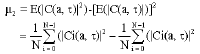 | (8) |
Where, N is the length of analyzed signal. Similarly, the higher order moments can be formulated in the same way and then the classification problem as a binary tree hypothesis-testing problem.
Let Hi be the ith modulation format assigned to the received signal, where i is associated with {GMSK, j} and j is with M-ary FSK. The statistical decision needs the probability density function (pdf) of the test statistics conditioned on the assigned digitally modulated signal. The random variables generated from linear combinations of both sinusoidal signal and Gaussian noise is considered as Gaussian probability density function. The two conditional Gaussian pdfs allow a threshold setting to decide the GMSK and M-ary FSK, when a certain probability of false identification of both signals is given. The conditional pdf is:
| (9) |
Under the hypothesis HGMSK is true, the probability of GMSK misclassification is simply the probability that μ2, GMSK - x < μ2, GMSK-T1, ie, μ2>T1. The probability of misclassification error for GMSK is given by:
| (10) |
which is reduced to
| (11) |
Where, erc(f) is defined as
Similarly, if it is assumed that the hypothesis HM-ary FSK is true, the probability of M-ary FSK signal misclassification is simply the probability that x - μ2, GMSK < T1-μ2, GMSK ie, μ2 < T1. The Probability of misclassification error for M-ary FSK is given by:
| (12) |
which is reduced to:
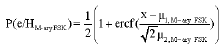 | (13) |
Where, erc (f) is in the same form. It is obvious that when the Gaussian noise increases, the variance of GMSK and M-ary FSK decreases until the point when both the probabilities of misclassification are equal. Thus, P(e/HGMSK) = P(e/HM-ary FSK) = 0.01 and the condition for setting the optimal threshold value T1 can be obtained by equating Gaussian distribution to zero. Then the related threshold value is obtained as:
| (14) |
Based on the variance the classification of GMSK with M-ary FSK can be done.
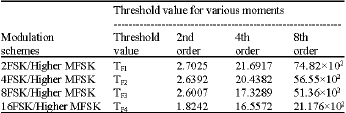
Classification of M-ary FSK signals: Similarly the threshold TFr (where r = 1,2,3,4 ... to represent 2-ary, 4-ary, 8-ary, 16-ary…, respectively) and the further classification of subclass I can be classified based on second or higher order statistical moment. Decision making between 2FSK, 4FSK, 8FSK, 16FSK and so on can be carried out based on the comparison of higher order statistical moment with computed threshold value and for 2r FSK and 2r+1 FSK is given by:
| (15) |
Where, n is ≥ 2.
Sub classification of class II: Similarly, the threshold value for identifying M-ary PSK and M-ary QAM can be obtained by:
| (16) |
Based on the mean and variance (or higher order moment) the classification of QPSK with QAM can be performed.
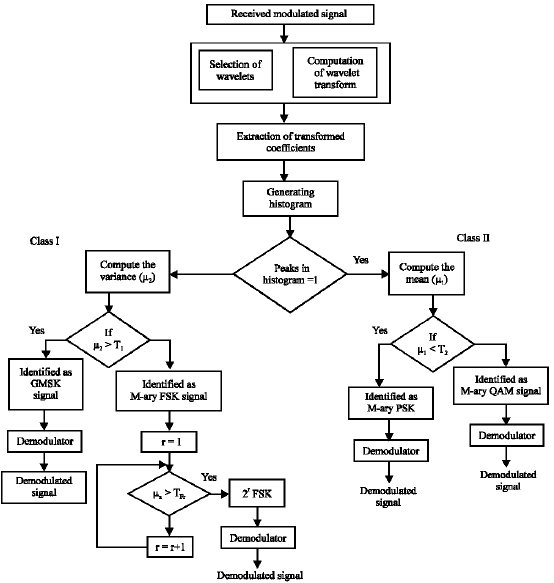 | |
| Fig. 1: | Flow graph for proposed modulation identification algorithm |
PROPOSED ALGORITHM
The identification of M-ary modulation schemes has been done using a common feature. As the transmission of any signal mainly concentrates in the high frequency components, these components can be obtained by extracting the coefficients using wavelet transformation. Wavelets are to be selected such a way that it looks similar to the patterns to be localized in the signal. A good approach to find a solution to this problem can be done by searching a function suitable for approximating both the analyzed signal envelope and frequency content. The wavelet Transform has been computed and the coefficients are recorded. These extracted coefficients are used to generate the histogram peaks. Based on the number of peaks, the identifier identifies that the received signal is either Class I or Class II (Fig. 1).
| Table 1: | Subsystem classification-decision rule |
 | |
After the major classification the Subclass I and II is classified based on the following decision rules as shown in Table 1.
RESULTS AND DISCUSSION
The algorithm including test signal generation, noise addition, reception, feature extraction and modulation identification was developed and tested using MATLAB. The developed algorithm is verified for 2FSK, 4FSK, 8FSK, 16FSK, GMSK, MPSK and MQAM modulation schemes. The above specified modulation schemes were simulated MATLAB with 200 symbols input message and AWGN noise is simulated and added with a transmitting signal as a channel noise. The Wavelet Transform has been applied to extract the transient characteristics of the received signal. The magnitude of Haar wavelet transform for Class II is a constant, but Class I has a multi-step function since the frequency is variable. This common feature made to consider the Haar wavelet as mother wavelet which is given (Chan, 1995) hereafter:
| (17) |
After extracting the transient characteristics, the coefficients were used to generate the histogram peak.
The Fig. 2 and 3 show that the Class I signal has more than single peak because these signals have multiple frequency components. But the Class II signal has constant transient characteristics and single peak in its histogram.
Then each subsystem is further classified based on decision rules shown in Table 1. The threshold value for Class I and II classification is provided in Table 2.
After identification as Class I, the subclassification is done based on the threshold values for 2nd, 4th and 8th order statistical moments tabulated in Table 3. After identification of the scheme, the demodulation is performed by conventional methods.
Performance analysis: The performance of the proposed algorithm was examined based on the confusion matrix, throughput and Receiver Operating Characteristics (ROC). These parameters are used to analyze the identification capability of the proposed algorithm.
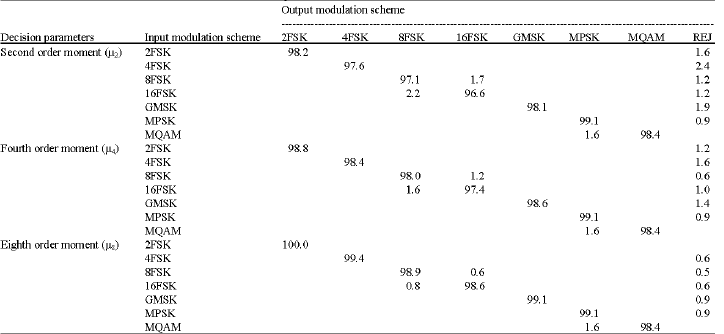
Confusion matrix analysis: For the analysis purpose, the identifier has been tested for 1000 experiments with 250 symbols per experiments. The testing was carried out for different SNR starting from 20 dB and the confusion matrix were tabulated at 3 dB for the proposed identifier as shown in Table 4.
The spread of identification results is caused by the similarity of the waveforms and could not really assess as false identification. Most of the non-successfully identified signals were assigned to the reject class REJ.
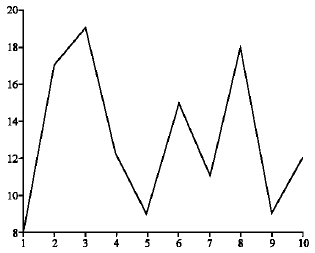 | |
| Fig. 2: | Histogram peak of class 1 signal |
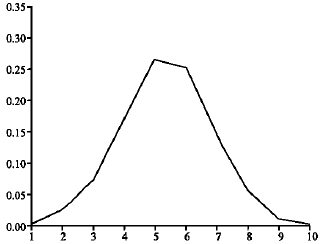 | |
| Fig. 3: | Histogram peak of class 2 signal |
| Table 2: | Threshold value for classification of class 1 and 2 |
| Table 3: | Threshold value for subclassification of class 1 for various statistical moments |
 | |
This is a desired result because a rejection is preferred to a false identification. The identification of 1.7% of 8FSK as 16FSK based on 8th order moment is caused by comparatively low SNR. Both the waveforms are similar in some aspects. The false identification of 1.6% of MPSK as MQAM is also not surprising because for the lower SNR these waveforms are similar in some nature.
| Table 4: | Confusion matrix at SNR = 3dB for various decision parameters |
 | |
| Table 5: | Throughput of the proposed algorithm (%) |
 | |
| Table 6: | Receiver operating characteristics (ROC) |
 | |
The false identification of 0.9% of GMSK as MFSK and vice versa is acceptable because both have some similar nature in frequency component. The above analysis show that the number of false identification is 1.6% for worst case and it is 0.16 for 1000 experiments testing.
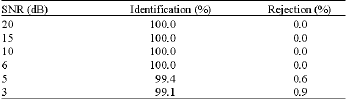
Throughput analysis: The throughput of the proposed algorithm was computed for various SNR starting from 20 to 3 dB and is tabulated in Table 5.
When SNR is greater than or equal to 6 dB, the percentage of identification is 100% and the identifier identifies the correct modulation schemes when SNR is greater than 3 dB with 99.1%.
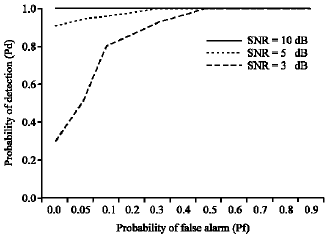 | |
| Fig. 4: | Receiver Operating Characteristics (ROC) for the Proposed Algorithm |
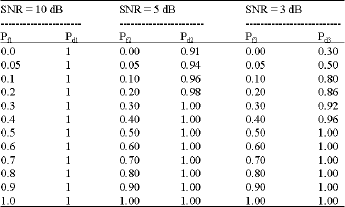
Receiver Operating Characteristics (ROC): ROC is a plot of probability of detection (Pd) as a function of the probability of false alarm (Pf). The probabilities of 200 symbols with 1000 experiments are calculated and tabulated in Table 6.
Figure 4 shows the ROC curves for the identifier when SNR is equal to 10, 5 and 3dB. The performance of the identifier is better if the curve rise faster.
When SNR is 10dB, Pd1 is 100% independent of Pf1. When SNR is 5dB and the Pf2 is 0.1, the Pd2 between GMSK and QPSK is 0.96. When SNR is 3dB and the Pf3 is smaller than 0.3 the Pd3 drops rapidly. This is because the hypothesis of moderate SNR used to obtain the optimum threshold in the decision device will no longer be valid.
| Table 7: | Comparison of various algorithms |
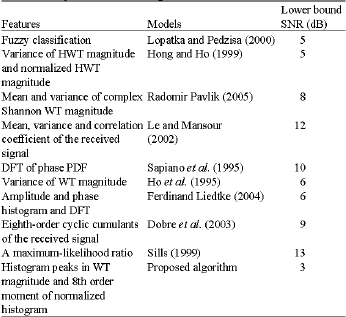 | |
Comparison of various classifiers: Comparison of the proposed algorithm with several existing algorithms for classifying various M-ary digital modulation schemes is shown in Table 7. The ideal scenario, i.e., no unknown parameters, as well as the scenarios with unknown carrier phase and unknown carrier phase/timing offset, respectively has been considered. Of course, when higher order modulations are included in the modulation pool, higher SNRs and/or a larger number of symbols are needed to achieve the same performance. From the comparison it is clear that the proposed algorithm is capable of identifying the various modulation schemes with low SNR values.
CONCLUSION
An automatic Modulation Identification algorithm is presented and is found to be well suited for M-ary digital modulation schemes used in SDR. The proposed algorithm was tested for 2FSK, 4FSK, 8FSK, 16FSK, GMSK, MPSK and MQAM modulation schemes with different SNR. The simulated results obtained using Wavelet transform technique, normalized histogram peak and 8th order statistical moment measurement show that the correct modulation scheme identification is possible even at low channel SNR of 3 dB. The ROC analysis shows that the percentage of correct modulation identification is higher than 98.4% for 1000 experiments with 200 symbols when SNR is not lower than 3 dB. The comparison with existing reported methods shows that the proposed algorithm is capable of identifying the M-ary Shift Keying modulation scheme with low SNR.
REFERENCES
- Beran, R., 1977. Minimum hellinger distance estimates for parametric models. Ann. Stat., 5: 445-463.
Direct Link - Buracchini, E. and T. Cselt, 2000. The software radio concept. IEEE Commun. Maga., 38: 138-143.
CrossRef - Liedtke, F., 2004. Adaptive procedure for automatic modulation recognition. J. Telecommun. Inform. Technol., 4: 91-97.
Direct Link - Le, D.G. and A. Mansour, 2002. Automatic recognition algorithm for digitally modulated signals. Procedings of the IASTED International Conference on Signal Processing, Pattern Recognition and Applications, June 25-28, 2002, Crete, Greece, pp: 32-37.
Direct Link - Lin, Y.C. and C.C. Jay Kuo, 2002. Modulation classification using wavelet transform. Proc. SPIE., 2303: 260-271.
CrossRef - Lopatka, J. and M. Pedzisa, 2000. Automatic modulation classification using statistical moments and a fuzzy classifier. Proceedings of 5th International WCCC-ICSP Conference on Signal Processing, Volume 3, August 21-25, 2000, Beijing, China, pp: 1500-1506.
Direct Link - Prakasam, P. and M. Madheswaran, 2007. Automatic modulation identification of QPSK and GMSK using wavelet transform for adaptive demodulator in SDR. Proceedings of the International Conference on Signal Processing, Communications and Networking (IEEE-ICSCN), February 22-24, 2007, MIT, Anna University, Chennai, pp: 507-511.
- Pavlik, R., 2005. Binary PSK/CPFSK and MSK bandpass modulation identifier based on the complex shannon wavelet transform. J. Elect. Eng., 56: 71-77.
Direct Link - Sapiano, P.C., J.D. Martin and R.J. Holbeche, 1995. Classification of PSK signals using the DFT of phase histogram. Proceedings of the Conference on ICASSP, May 9-12, 1995, Detroit, MI., USA., pp: 1868-1871.
CrossRefDirect Link - Sills, J.A., 1999. Maximum-likelihood modulation classification for PSK/QAM. Proceedings of the Conference on Military Communications, Volume October 31-November 3, 1999, Atlantic City, New Jersey, pp: 217-220.
CrossRefDirect Link - Yu, Z., Y.Q. Shi and W. Su, 2003. M-ary frequency shift keying signal classification based on discrete fourier transform. Proceedings of the Conference on Military Communications, Volume 2, October 13-16, 2003, IEEE Computer Society Press, pp: 1167-1172.
CrossRefDirect Link - Nolan, K.E., L., Doyle, P. Mackenzie and D. O’Mahony, 2002. Modulation scheme classification for 4G software radio wireless networks. Proceedings of the IASTED International Conference on Signal Processing, Pattern Recognition and Applications, June 25-28, 2002, Crete, Greece, pp: 25-31.
Direct Link