
Norris Sookoo
College of Science, Technology and Applied Arts of Trinidad and Tobago
Shanaz Ansari Wahid
Department of Mathematics and Computer Sciences, The University of the West Indies
Ashok Sahai
Department of Mathematics and Computer Sciences, The University of the West Indies
Journal of Applied Sciences
Year: 2007 | Volume: 7 | Issue: 6 | Page No.: 926-929







ABSTRACT
In coding theory, a string of ones and zeros is called a word. When these digits are transmitted and received electronically, errors may occur and any digit may be misidentified, thus giving rise to a string of errors, one for each digit. For the case where m binary words of length n are transmitted and received, we obtain the probability distribution of the error tuple, which shows the number of words having i errors, as i varies from 1 to n. Related probabilities are obtained and also the probability and moment generating functions are derived.
PDF Abstract XML References Citation
How to cite this article
Norris Sookoo, Shanaz Ansari Wahid and Ashok Sahai, 2007. Probability Distribution of m Binary n-tuples. Journal of Applied Sciences, 7: 926-929.
DOI: 10.3923/jas.2007.926.929
URL: https://scialert.net/abstract/?doi=jas.2007.926.929
DOI: 10.3923/jas.2007.926.929
URL: https://scialert.net/abstract/?doi=jas.2007.926.929
INTRODUCTION
Discrete distributions have been widely studied, often in connection with models that arise in reliability experiments. Samaniego and Jones (1981) studied maximum likelihood estimation for a class of multinomial distributions that arise in reliability experiments in which components have different probabilities of failure. Binomial signals in noise are encountered in diverse areas. Woodward (1953) discussed a communication system for which the observed output is the sum of independent Bernoulli variables. Study of discrete signal detection includes the work of Greenstein (1974) on block coding of binary signals.
Studies of almost binomial distributions abound. Shah (1966) obtained moment estimates for truncated binomial distributions and Thompson (2002) considered a variation of the binomial distribution in which the parameter n can be any positive number. This new distribution is useful in approximation situations.
Balakrishnan (1997) has reviewed many recent applications of combinatorial methods in Probability and Statistics. The multinomial distribution (Johnson et al., 1997) is a well known distribution which generalizes the binomial distribution. We use Combinatorial methods to study another generalization of the binomial distribution. We consider an n-tuple of zeros and ones to be a sequence of indicators of n Bernoulli trials. That is, suppose that a sequence of n zeros and ones, called a word in coding theory, is transmitted electronically such that the probability of getting a non-zero error in a received digit is a constant, p. The sequence of n zeros and ones representing the errors is called an error vector in coding theory.
The distributions we study can also be utilized in investigating the reliability of systems. If a system is made up of n identical components connected in parallel and the probability that a component will fail in a given time period is a constant p, then the number x of components that will fail in that period has binomial distribution. For m systems of this type, the first result is equal to the probability that xi systems will experience i failures. Thus if a system is made up of m subsystems like the above and this larger system functions properly only if k of the m substems function properly, we can calculate the relevant probability using the distribution obtained in this study. For the subsystems, the probability that each component will function may vary from subsystem to subsystem and result covers this case.
DEFINITIONS AND NOTATIONS
The following concepts are taken from Coding Theory.
Definition 1: Let c be and n-tuple of zeros and ones. c is called a word of length n.
Definition 2: The weight of c, denoted by w(c), is the number of ones in c.
We assume that when words are transmitted and received, the probability that an error in a digit occurs is p, the probability that no error occurs is q and p+q = 1. An error occurs if 1 is transmitted and identified as 0, or 0 is transmitted and identified as 1.
Definition 3: Suppose that m consecutive words of length n are transmitted. The m words will be called an mn-block of words. The associated m error vectors of length n will be called an mn-block of error vectors.
Definition 4: The weight-tuple associated with an mn block of error vectors is Y = (Y0, Y1,....,Yn), where Yi is the number of error vectors of weight i in the mn block, (i = 0,1,...,n).
Definition 5: The joint probability mass function of Y is
PY (y) = P (Y = y) = P (Y0 = y0, Y1 = Y1,....,Yn = yn)
where y = (y0 y1, y1,...., yn)
Definition 6: The probability generating function (Johnson et al., 1997) of Y is
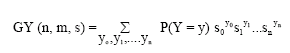 |
subject to the condition ![]()
Definition 7: The moment generating function (Johnson et al., 1997) of Y is
Distribution of Y
Theorem 1: If an mn-block is received, then
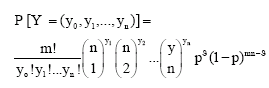 | (1) |
where ![]() .
.
Proof: Suppose that an mn-block is received. The block of associated error vectors can be represented by an mxn matrix of zeroes and ones. Consider such a matrix of which each of the first y1 rows is of the form 1 0 0 … 0, each of the next y2 rows is of the form 1 1 1 0 0 …0, each of the next y3 rows is of the form 1 1 1 0 0 … 0 and so on, with the last yn rows having the form 1 1 1 … 1.
The probability that the received mn-block of error vectors has the above form
where ![]()
The number of different mn-blocks with the first y0 error vectors having weight 0, the next y1 error vectors having weight 1, the next y2 error vectors having weight 2, etc. ![]() Also, the number of different mn-blocks with the yi error vectors of weight i, (i = 1. 2, … , n) in fixed positions is the same. The number of different ways that the m error vectors in an mn-block can be arranged so that the yi error vectors words of weight i (i = 1, 2, …, n) occupy the same position is .
Also, the number of different mn-blocks with the yi error vectors of weight i, (i = 1. 2, … , n) in fixed positions is the same. The number of different ways that the m error vectors in an mn-block can be arranged so that the yi error vectors words of weight i (i = 1, 2, …, n) occupy the same position is . ![]()
Theorem 2: The probability generating function of Y is
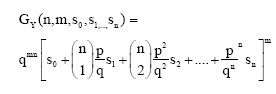 | (2) |
Proof: The probability generating function is
subject to the condition ![]()
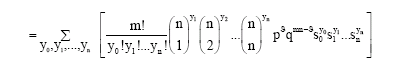 |
subject to the condition Σyi = m,
where ![]()
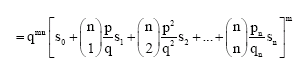 |
Theorem 3: The moment generating function of Y is
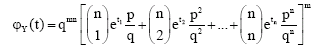 | (3) |
Proof: ![]()
(where ' is the same as in the previous theorem.)
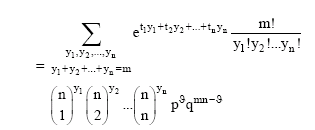 |
Distribution of Yi
Theorem 4:
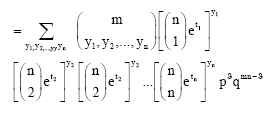 |
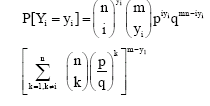 | (4) |
Proof: P[Yi = yi] =
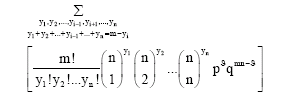 |
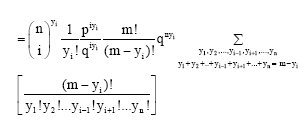 |
 |
DIFFERENT ERROR PROBABILITIES FOR DIFFERENT WORDS
Suppose that m words, each of length n, are transmitted such that when the ith word is being transmitted and received, P [a digit is incorrectly identified] = pi and P [a digit is correctly identified] = qi, where qi, I = 1, 2, …, m. We define Y as before and set
Theorem 5:
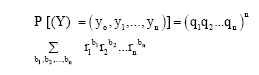 | (6) |
where the summation is taken over all permutations zeros, y1 ones,y2 twos, …, yn n’s.
Proof: Let us consider an outcome in which the first y0 error vectors are of weight zero, the next y1 error vectors are of weight one, the next y2 error vectors are weight two, …, the last yn error vectors are of weight n.
Probability of such an outcome
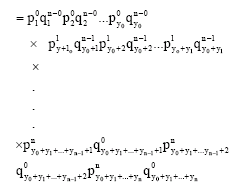 |
Every possible outcome with the desired weight distribution will have a probability equal to the above with some rearrangement of the powers. Hence
where the condition on the b’s are as stated in the theorem.
Theorem 6: The probability generating function of Y is
| (7) |
Proof: GY (n, m, s, p) =
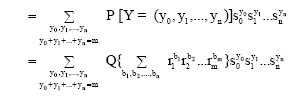 |
where the inner summation is taken over all permutations (b1 b2...bm) of y0 zeros, y1 ones, y2 twos, ... , yn n’s.
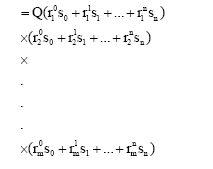 |
because in multiplying out the above product, each time we choose si, the power of the corresponding r will be i. Hence the coefficient of ![]() will be
will be![]() where
where![]() is as described above.
is as described above.