
Mohsen Hayati
Department of Electrical Engineering, Razi University, Kermanshah-67149, Iran
Behnam Karami
Department of Electrical Engineering, Razi University, Kermanshah-67149, Iran
Journal of Applied Sciences
Year: 2007 | Volume: 7 | Issue: 19 | Page No.: 2812-2817







ABSTRACT
In this study a new method based on neural network has been developed for solution of differential equations. A modified neural network is used to solve the Burger’s equation in one-dimensional quasilinear partial differential equation. This method is generally applicable to nth order partial differential equations on a finite domain with boundary conditions. The results obtained by this method, have been compared with the exact solution and found to be in good agreement with each other and because of superior properties of neural network i.e., parallel processing thereby less computational cost, this method has advantages over conventional methods.
PDF Abstract XML References Citation
How to cite this article
Mohsen Hayati and Behnam Karami, 2007. Feedforward Neural Network for Solving Partial Differential Equations. Journal of Applied Sciences, 7: 2812-2817.
DOI: 10.3923/jas.2007.2812.2817
URL: https://scialert.net/abstract/?doi=jas.2007.2812.2817
DOI: 10.3923/jas.2007.2812.2817
URL: https://scialert.net/abstract/?doi=jas.2007.2812.2817
INTRODUCTION
The dynamic of a physical system is usually determined by solving a diffrential equation. It normally proceeds by reducing the Differential Equation (DE) to a familiar from with known (compact) solutions using suitable coordinate transformations (Joes and Freeman, 1986; Atfken and Weber, 1995). In notrivial cases however, finding the appropriate transformations is difficult and numerical methods are used. A number of algorithm (e.g., Runge-Kutta, finite difference, etc.) are available for calculating the solution accurately and efficiently (Press et al., 1986; Kunz and Lubbers, 1993). However, these methods are sequential and required much memory space and time as a result have great computatinal cost. Hemmessy and petterson (Saif et al., 2006) have estimate that most computational complex application spent 90% of their execution time in only 10% of their code, hence a parallel approach to run an algorithm can be montrivial . Here, we demonstrate a new method of find solutions of differential equation. Clearly we use an unsupervise feedforword Neural Network to solve Burger’s equation that is the one-dimentional quasilinear parabolic partial differential equation. The Neural Network methods have been applied successfully to linear (Monterda and Saloma, 1998) and coupled DE’s (Cruito et al., 2001) but not yet been tested with this class of differential equations. An intresting theorem that sheds some light on the capabilities of multilayer networks was proven by kolmogorov and is described in (Lorentz, 1976). This theorem states that only continously increasing function of only one veriable. Solving a DE implies the training of an Neural Network that calculates the solution values at any point in the solution space, including those not considered during the Neural Network training. In this sense, the unsupervised Neural Network learns to solve the differential equation analytically. Because the correct form of the differential equation solution is unknown beforehand, the convenient supervised algorithm for training the neural network can not be applied here, so we propose a new modified algorithm to train the neural network. The Neural Network is trained in an unsupervised manner using an energy (error) function that is derived from the differential equation itself and the governing boundary conditions. The proper choice of the energy function is crucial in training the neural network to learn the analytical properties of the solution. The solution of the differential equations in terms of neural network possesses several interesting features as neural networks learns to solve the differential equation analytically, its computational complexity does not increase quickly with number of sampling points, its rapid calculation of the solution values, its superior interpolation properties as compared to well-established methods such as finite elements (Joes and Freeman, 1986; Arfken and Weber, 1995) and finally implementation ability on existing specialized hardware (neuroprocessor), a fact that will result in a significant computational speedup.
MATERIALS AND METHODS
Mathematical definition: As a prelude to our method, some mathematical definitions and results are given. For a detailed exposition, the reader can refer to the books of Cichocki and Unbehauen (1993).
1-Let f (x) = f (x1, x2, ..., xn) be a real scalar function of a real vector x ε![]()
The derivative of function f (x) with respect to the vector x is an 1 x n vector,
Its gradient is an n x 1 vector,![]()
2-For a real vector function
where, xε![]() its gradient is defined as
its gradient is defined as
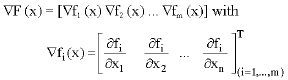 |
The Jacobian matrix is.![]()
3-Let f (x) = h (g (x), where x ε ![]() and f:
and f: ![]() . The chain rule of differentiation is Jf (x) = Jh (g (x) Jg (x) and
. The chain rule of differentiation is Jf (x) = Jh (g (x) Jg (x) and
![]()
4-Let F = h (f (w) and f (w) = [f1 (w) f2 (w) ... fm (w)]T Where w ε ![]() and h:
and h: ![]() The chain rule for the differentiation of the scalar function F with respect to the matrix w yields
The chain rule for the differentiation of the scalar function F with respect to the matrix w yields
Illustration of the method: A general structure of feedforward neural network is shown in Fig. 1. The feedforward neural networks are the most popular architectures due to their structural flexibility, good representational capabilities and availability of a large number of training algorithm (Haykin, 1999). This network consists of neurons arranged in layers which every neuron in a layer is connected to all neurons of next layer (a fully connected network). The neurons in the input layer simply store the input values. The hidden layers and output layer neurons each carry out two calculations. First they multiply all inputs and a bias (equal to a constant value of 1) by a weight and then they sum the result representing input net of a neuron ‘O’ and second the output of neurons ‘a’ calculated as a function (named activation function ) of ‘O’. The choice of activation function depends on application of the network but the sigmoid function is normally being used. The mathematical formulas for a neuron are:
| (1) |
Where, a0 = x is an n0-dimensional input vector, ak and fk are the nk -dimensional output and the activation function vector in the kth layer, respectively. The ωk and bk for k = 1, 2,..., n are:
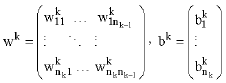 |
We feed the network with input data that propagating through layers from input layer to output layer. This state of the network is called relax state. In the train state of the network the adjustable parameters of the networks (weights and biases) are tuned by a proper learning algorithm to minimize the energy function of the network.
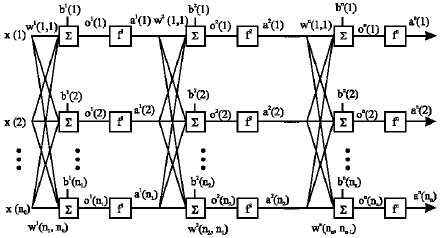 | |
| Fig. 1: | An N-layer Feedforward Neural Network |
We train the network via the Gradient-descend backpropagation method (Haykin, 1999) with the nonnegative energy function.
The Gradient-descend has a number of advantages over other optimization techniques such as Conjugate Gradient Method (CGM) and Limited-Memory quasi-Newton Algorithm (LMNA) which consider the Jacobin (JM) and the Hessian (HM) Matrix, respectively. HM contains second-order partial derivatives of the error surface with respect to the weights, while JM (or Gradient vector) contains the first-order partial derivatives. Empirical studies have shown that both HM and JM are almost rank-deficient when used in multilayer perceptron Neural Network due to the intrinsically ill-conditioned nature of the Neural Network training problem (Saarineen et al., 1991). Higher-order methods may not converge faster and the computations of HM and JM and their corresponding inverse are also computationally expensive. Both LMNA and CGM also involves calculation of the inverse of HM and JM, respectively. HM and JM are not always guaranteed to be non-singular and therefore their inverse may be uncomputable. According to the Gradient descend algorithm the changes of the weights and bias, Δwk Δbk through the minimization of the energy function with respect to the weights wk and bias, bk, are:
| (2) |
where, η is learning rate. The value of the learning rate is adaptively varied from 0 to 1 according to the following rule (Haykin, 1999):
| • | Increases when the gradient of E with respect to a particular weight does not change algebraic sign after several (in our case, four) consecutive iterations that enhances the search for the minimum error surface |
| • | Increases when the gradient of E change algebraic sign after four consecutive iteration in the search space and that prevents unnecessary oscillations |
| • | Otherwise, the η value remains the same. The rate is adaptively varied to account for the change of the error surface along different regions of single-weight dimension (Yam Chow, 2000; Lou, 1991). When the gradient of the error (energy), E, with respect to the linear output Ok in the kth Layer is defined as (Hagan and Menhaj, 1994). |
| (3) |
then
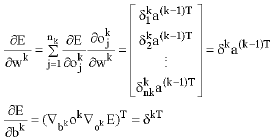 | (4) |
where,![]() and
and ![]()
The recurrence relation of the gradient can be obtained by:
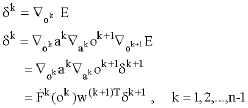 | (5) |
Where
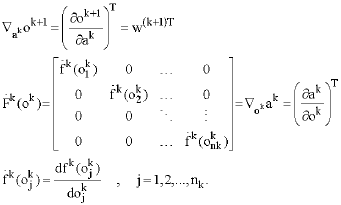 |
This recurrence relation is initialized at the final layer
| (6) |
The error back propagated into the network must be reformulated as the parameters of the neural network. The exact form of the equations depends on the differential equation that is considered. In brief, we follow these steps to train the network :
| Step 1: | Discretizing the Domain and generate training data set. |
| Step 2: | Initializing weights and bias. |
| Step 3: | Presenting randomly sampled data. |
| Step 4: | Calculating energy function with respect to present values of parameters. |
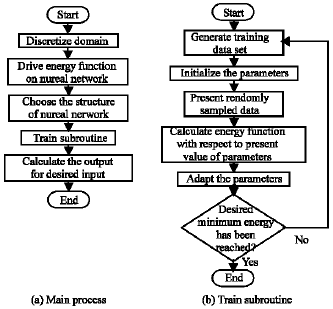 | |
| Fig. 2: | The flowchart for main process and its train subroutine |
| Step 5: | Adapting parameters. |
| Step 6: | Repeating by going to step 3 until the desired minimum energy has been reached. |
| Step 7: | Calculating the outputs of the network for a given point from input domain as an approximation of the solution. |
The flowchart for main process and its train subroutine is shown in Fig. 2. Once the network is trained for a specific equation with its boundary and initial conditions, the solution of the equation for a desired input is obtained at just one cycle of relax state of the network.
A case study: To show the procedure, we will examine Burger’s equation of the form
| (7) |
which is the one-dimensional quasilinear parabolic partial differential equation and v>0 is the coefficient of the Kinematics Viscosity of the fluid. This equation was intended as an approach to the study of turbulence, shock wave and gas dynamics. The equation is considered with the following initial and boundary conditions:
We rewrite Eq. 7 as the form
| (8) |
For this PDE, a three-layer feedforward neural network is chosen, consisting of 2 inputs xm where m = 1,2, H hidden units and one output (u). The 2 input consist of 2 independent variables x1 = x and x2 = n. We use sigmoid functions for hidden layer neurons and linear function for output neuron. The accuracy of neural network solutions, depends on how close the energy function is reduces to zero during training. We choose an energy function of the form
| (9) |
Where:
|
The energy function is chosen such that E is zero if and only if the terms in the right-hand side of the equation are all identically equal to zero. To achieve an accurate solution for u (x, t), training must reduce to a value that is as close as possible to zero.
The vanishing of E1 ensures that u (x, t) exactly satisfies equation while the reduction of each E2, E3 and E4 terms to zero guarantees a unique solution for u (x, t). To reformulate this PDE with neural network, we derive equations as below:
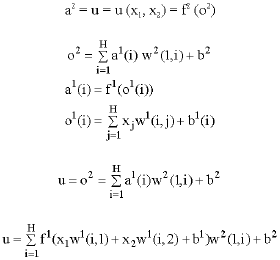 |
where ![]()
| (10) |
| (11) |
| (12) |
Where the w (i, j) is the weight between jth neuron of a layer and ith neuron of next layer. Our training set consists of 30x105 unique combination of x and t in the following range:
The trained network generalizes solution values including points those not considered during training state to the solution curves with accuracy of 10-12 for energy function. The accuracy can be controlled efficiently by varying the number of hidden layer neurons. By trial and error we found that the most trainable three-layer architecture is one with 40 hidden nodes (H = 40).
RESULTS AND DISCUSSION
Let consider the Burger’s equation with following problem:
Problem 1: The first problem is Burger’s equation with initial condition
| (13) |
and homogeneous boundary conditions
| (14) |
The exact solution of the Burger’s equation with initial condition, Eq. 13 and boundary conditions, Eq. 14, is obtained as:
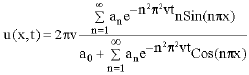 | (15) |
where a0 and an for n = 1, 2,… are Fourier Coefficients and they are defined by the following equations, respectively.
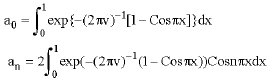 |
where n ≥ 1
Problem 2: The second problem is the Burger’s equation with the initial condition
and homogeneous boundary conditions, Eq. 14 and the exact solution, Eq. 15, with
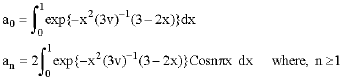 |
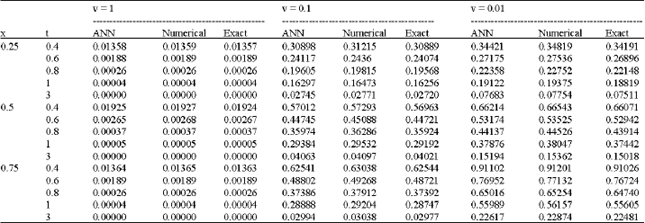
Numerical results: Table 1 and Table 2 shows the ANN solutions of problem-1 and problem-2, respectively for different values of viscosity coefficient.
| Table 1: | Comparison of results at different times for v =1, v = 0.1 and v = 0.01 |
 | |
| Table 2: | Comparision of results at different times for v = 1, v = 0.1, v = 0.01 |
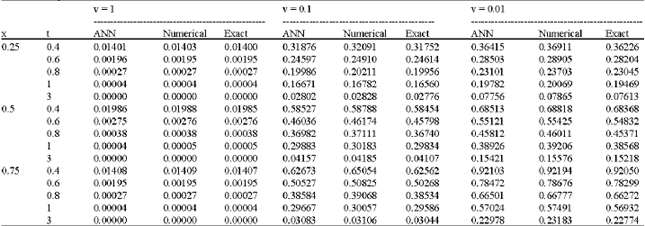 | |
It is observed that ANN solutions are seen to be satisfactory in agreement with the exact solutions. The ANN solutions are more accurate as compared to solution obtained with numerical method by Kutluay et al. (2004).
CONCLUSIONS
In this study a new method based on ANN has been applied to find solutions for Burger’s equation, but this method is straightforwardly applicable to nth order partial differential equations. It is observed that ANN solutions are seen to be satisfactory in agreement with the exact solutions. The ANN solutions are more accurate as compare to solution obtained with numerical method. The neural network here allows us to obtain fast solutions of differential equations starting from randomly sampled data sets. The algorithm allows us to achieve good approximation results without wasting memory space and computational time and therefore reducing the complexity of the problem, due to parallel structure of the network. A comparison to the exact solutions shows that proposed method is able to achieve good results both in accuracy and computational complexity.
REFERENCES
- Cruito, M., C. Monterola and C. Saloma, 2001. Solving N-body problems with neural networks. Phys. Rev. Lett., 86: 4741-4744.
Direct Link - Hagan, M.T. and M.B. Menhaj, 1994. Training feedforward neural network with the marquardt algorithm. IEEE Trans. Neural Networks, 5: 989-993.
Direct Link - Kutluay, S., A. Esen and I. Dag, 2004. Numerical solution of the Burger=s equation by the least-squares quadratic B-spline finite element method. J. Comput. Applied Math., 167: 21-33.
Direct Link - Luo, Z., 1991. On the Convergence of the LMS algorithm with adaptive learning rate for linear feedforward neural networks. Neural Comput., 3: 226-245.
Direct Link - Monterda, C. and C. Saloma, 1998. Charactering the dynamic of constrained physical systems with unsupervised neural network. Phys. Rev., 57: 1247-1250.
Direct Link - Saif, S., H.M. Abbas, S.M. Nassar and A.A. Wahdan, 2007. An FPGA implementation of neural optimization of block truncation coding for image/video compression. Microprocessor Microsyst., 31: 477-486.
Direct Link - Yam, J. and T. Chow, 2000. A weight initialization method for improving training speed in feedforward neural network. Neurocomputing, 30: 219-232.
Direct Link