
Chang Yun Fah
Faculty of Engineering, Multimedia University, 63100 Cyberjaya, Selangor, Malaysia
Abdul Ghapor Hussin
Centre for Foundation Studies in Science, University of Malaya, 50603 Kuala Lumpur, Malaysia
Omar Mohd Rijal
Institute of Mathematical Sciences,
University of Malaya, 50603 Kuala Lumpur, Malaysia
Journal of Applied Sciences
Year: 2007 | Volume: 7 | Issue: 1 | Page No.: 20-26







ABSTRACT
This study investigates the Unreplicated Linear Functional Relationship (ULFR) model where the measurement error term, δ, is introduced. The coefficient of determination (COD) of ULFR, denoted by
PDF Abstract XML References Citation
How to cite this article
Chang Yun Fah, Abdul Ghapor Hussin and Omar Mohd Rijal, 2007. An Investigation of Causation: The Unreplicated Linear Functional Relationship Model. Journal of Applied Sciences, 7: 20-26.
DOI: 10.3923/jas.2007.20.26
URL: https://scialert.net/abstract/?doi=jas.2007.20.26
DOI: 10.3923/jas.2007.20.26
URL: https://scialert.net/abstract/?doi=jas.2007.20.26
INTRODUCTION
The seriousness of the road accident problem warrants a deeper investigation into the possible causes. In particular the ULFR model is investigated. The studies of functional and structural relationships have been focused on estimating the parameters and the measurement error models since it was first introduced by Adcock in year 1877 (Sprent, 1990). Several methods were proposed, but the widely used estimator is the maximum likelihood method (Dolby, 1976; Fuller, 1987; Kendall and Stuart, 1979). An early study to check the adequacy of the ULFR model is given by Fuller (1987) who suggests using the residual plot as an indication of nonlinearity, lack of homogeneity of the error variances, nonnormality of the errors and outlier observations. In this study we propose the COD as a measure to check the model adequacy and the assumption of independent variable. Without loss of generality, the properties of this measurement for case λ = 1 is investigated. A large value of COD of the ULFR relative to the COD of ordinary Simple Linear (SL) regression model is indicative of causation.
As pointed out by Fuller (1987), the assumption that the independent variable can be measured exactly may not be realistic in many situations. The estimates of independent variable may contain measurement error arising from trying to quantify a variable that has no physical dimension. For example in the road accident problem, it has been shown that the male motorist is more prone to be involved in accident. One possible explanation is the performance of male drivers may vary with state of mind. Since this factor, the state of mind cannot be measured directly, it is more reasonable to consider them as a measurement error rather than introduce a new independent variable into the model.
UNREPLICATED LINEAR FUNCTIONAL RELATIONSHIP MODEL
Suppose that X and Y are two linearly related unobservable variables
| (1) |
and the two corresponding random variables x and y are observed with error δ and ε, respectively as
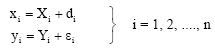 | (2) |
The following conditions are assumed
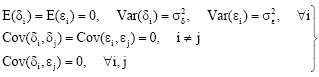 | (3) |
where, δi and εi are mutually independent and normally distributed random variables. Equation 1 and 2 are known as ULFR model when there is only one relationship between the two variables X and Y. When the ratio of the error variances is known, that is ![]() , then the maximum likelihood estimators of parameters α, β, and
, then the maximum likelihood estimators of parameters α, β, and ![]() Xi are:
Xi are:
| (4) |
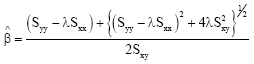 | (5) |
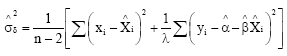 | (6) |
and
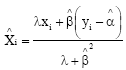 | (7) |
where,
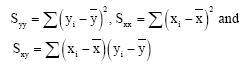 |
DERIVATION OF THE COEFFICIENT OF DETERMINATION (COD)
In an ordinary SL regression analysis, we look at the COD as a measure of the variability in y explained by the regression model. The construction of the COD is a good practice when fitting the ULFR model.
The Eq. 1 and 2 can be rewritten as
| (8) |
If we substitute Xi by (xi-δi) in (8), then we have the expression
Where, the errors of the model , Vi = (εi - βδi) = yi - (α + βxi) for = 1, 2, …, n is a normally distributed random variable with zero mean and variance ![]() . If are the estimates of α and β respectively, then
. If are the estimates of α and β respectively, then
| (9) |
will be the residual of the model. From Kendall and Stuart (1979) and Andrson (1984), that the sum of squared distances of the observed points from the fitted line or the residual sum of squares (SSE) is given as:
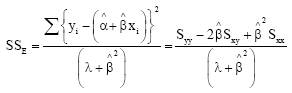 | (10) |
We shall consider here that the ratio of the error variances is equal to one (λ = 1). For those cases when λ ≠ 1, we can always reduce this to the case of λ = 1 by dividing the observed values of y by λ1/2 (Kendall and Stuart, 1979). Hence, we have:
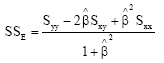 | (11) |
In the same way as ordinary linear regression, we can now define the COD of the ULFR (![]() ) as the proportion of variation explained by the variable x, that is:
) as the proportion of variation explained by the variable x, that is:
| (12) |
where, SSR is the regression sum of squares which can be derived as:
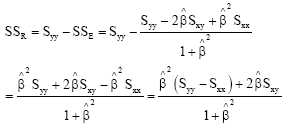 | (13) |
We can summarise our proposed COD with the following results.
Result 1: Let the ratio of the error variances be known and is equal to one, ![]() = λ = 1, then the COD for the ULFR model is
= λ = 1, then the COD for the ULFR model is
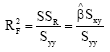 | (14) |
Proof: When λ = 1, then ![]() in Eq. 5 becomes
in Eq. 5 becomes
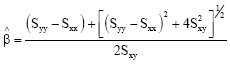 |
and
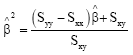 |
Notice that ![]() From Eq. 13,
From Eq. 13,
we have,
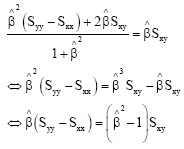 |
From the R.H.S.
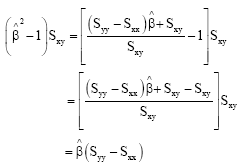 |
Result 2: Let ![]() and
and ![]() be the slope estimator for the simple linear regression and the ULFR, respectively. The corresponding COD are:
be the slope estimator for the simple linear regression and the ULFR, respectively. The corresponding COD are:
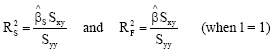 |
Then ![]() .
.
Proof: From the regression sum of squares, we obtain
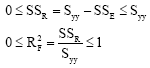 |
we also know that simple linear regression has ![]() .
.
We now proof ![]() by contradiction. Assuming that
by contradiction. Assuming that
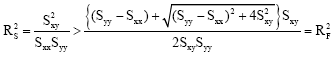 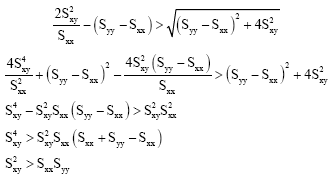 |
Also from ![]() , this is a contradiction. Hence, we have
, this is a contradiction. Hence, we have ![]() ..
..
PROPERTIES OF ![]()
Since ![]() is computed following the same method as
is computed following the same method as ![]() , some of the properties of
, some of the properties of ![]() may also remain for
may also remain for ![]() . It is known that
. It is known that ![]() does not measure the appropriateness of the linear model (Montgomery and Peck, 1992). This holds for
does not measure the appropriateness of the linear model (Montgomery and Peck, 1992). This holds for ![]() too. As an example, when a nonlinear model has a large
too. As an example, when a nonlinear model has a large ![]() value, it is obvious that
value, it is obvious that ![]() will also be large (Result 2).
will also be large (Result 2).
Secondly, the magnitude of ![]() depends on the range of variability in the variables X and Y. From Eq. 14, we have
depends on the range of variability in the variables X and Y. From Eq. 14, we have
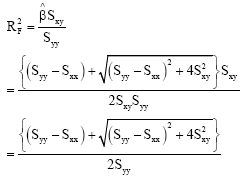 |
Let var(X) and var(Y) be variances of X and Y, respectively then and var(Y) = Syy/ n-1. We consider three possible cases of relationship between var(X) and var(Y) when Sxx > 0 and Syy > 0.
Case 1: If var(X) = var(Y) ⇔ Sxx = Syy, then
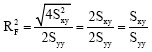 |
when compared with Eq. 14, this holds when ![]() = 1.
= 1.
Case 2: If var(X) < var(Y) ⇔ Syy/k = Sxx < Syy for k > 1, then
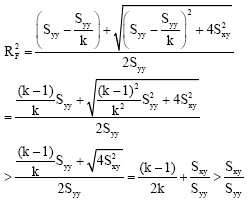 |
when compared with Eq. 14, this holds when ![]() >1.
>1.
Case 3: If var(X) > var(Y) ⇔ kSyy = Syy for k>1, then
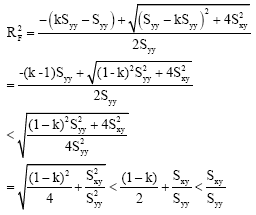 |
when compared with Eq. 14, this holds when ![]() <1.
<1.
We can summarize the above properties with the following result.
Result 3: Let Sxx > 0, Syy > 0 and Sxx = kSyy or var(x) = k var(y), then
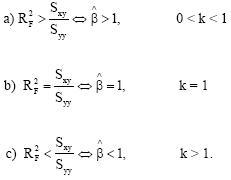 |
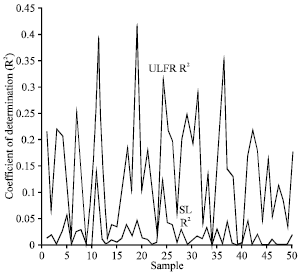
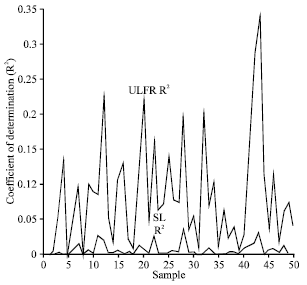
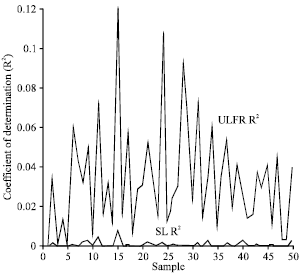
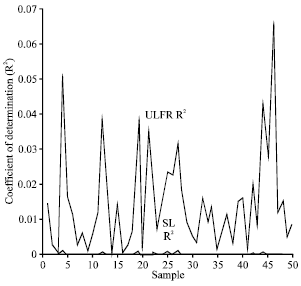
The numerical example of the above results is given in Fig. 1a-1f. To explain the relationship between ![]() and
and ![]() , the value of CODs are compared for different sample sizes (n = 10, 50, 100, 1000, 5000 and 10000). For a given sample size, fifty samples were generated from a uniform distribution, each contains two random data sets (yi, xi). As an example, Fig. 1a shows fifty values of COD derived from SL and ULFR methods with sample size n = 10. Figure 1b-1f show the same plot with sample sizes n = 50, 100, 1000, 5000 and 10000, respectively. It is clearly shown that
, the value of CODs are compared for different sample sizes (n = 10, 50, 100, 1000, 5000 and 10000). For a given sample size, fifty samples were generated from a uniform distribution, each contains two random data sets (yi, xi). As an example, Fig. 1a shows fifty values of COD derived from SL and ULFR methods with sample size n = 10. Figure 1b-1f show the same plot with sample sizes n = 50, 100, 1000, 5000 and 10000, respectively. It is clearly shown that ![]() is always greater or equal to
is always greater or equal to ![]() . One interesting feature shown in Fig. 1 is that both
. One interesting feature shown in Fig. 1 is that both ![]() and
and ![]() decreased when the sample size increased.
decreased when the sample size increased.
APPLICATION IN ROAD ACCIDENT PROBLEM
So far, various road accident models have been proposed to explain Malaysian road accident phenomena (Radin et al., 1995; Radin, 1996; Razali and Dahalan, 1992). However, PDRM road statistics show that the number of road accidents still remains high. One reason the Malaysian road accident problem has not been solved effectively is that the existing models are constructed for prediction purpose rather than causal inference. The crucial factor ignored in the existing models is the driver ’s state of mind that cannot be measured directly. The driver state of mind includes driver ’s attitude, ability to concentrate and tendency to take risks. It has been suggested that the driver ’s state of mind is an essential factor that causes road accident (Leeming, 1969; Forbes, 1972) .
In this example, we introduce the state of mind as a factor that causes variations in other physically measurable factors such as driver ’s sex, age and race. This is formally expressed using the ULFR model where the measurement error, δ is representing the state of mind. Difference between ![]() and
and ![]() is used to measure the effect of the state of mind to the road accident model. Since
is used to measure the effect of the state of mind to the road accident model. Since ![]() and
and ![]() have similar interpretations by construction, when
have similar interpretations by construction, when ![]() is significantly larger than
is significantly larger than ![]() we say that the state of mind has been incorporated into the independent variable and the model now explains the causal relationship of road accident.
we say that the state of mind has been incorporated into the independent variable and the model now explains the causal relationship of road accident.
Table 1 shows the socio-biological variables of the Malaysian road accident data for 1996 obtained form Malaysian Royal Police (PDRM) headquarters. The Box-Cox power transformation (Box and Cox, 1964) is presented to access normality with ![]() = [0.25 0.69 1.25 0.14 0.23 0.47]. Without loss of generality, we assume that the ratio of variances, λ, equals one by dividing the number of state accidents by the total number of accidents in Malaysia.
= [0.25 0.69 1.25 0.14 0.23 0.47]. Without loss of generality, we assume that the ratio of variances, λ, equals one by dividing the number of state accidents by the total number of accidents in Malaysia.
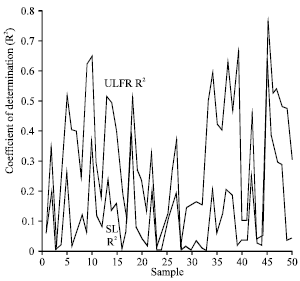 | |
| Fig. 1a: | COD plots for SL and ULFR models with n = 10 |
 | |
| Fig. 1b: | COD plot for SL and ULFR models with with n = 50 |
 | |
| Fig. 1c: | COD plots for SL and ULFR models with n = 100 |
 | |
| Fig. 1d: | COD plot for SL and ULFR models with n = 1000 |
 | |
| Fig. 1e: | COD plots for SL and ULFR models with n = 5000 |
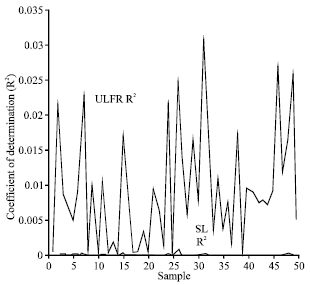 | |
| Fig. 1f: | COD plot for SL and ULFR models with with n = 10000 |
| Table 1: | Socio-biological explanatory variables |
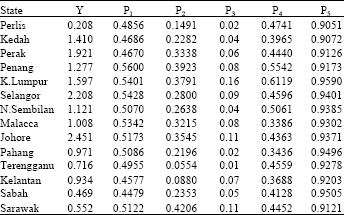 | |
Source: PDRM (Malaysian Royal Police, 1995-1998)
Note:
| • | The number of vehicles involved in 1996 does not include accident of type ‘slightly injured ’ and property damaged only |
| • | Y = number of road accidents ( ‘000) P1 = Age (ratio of drivers aged 16-30 years to total number of drivers involved in accidents) P2 = Race (ratio of Chinese drivers to total number of drivers involved in accidents) P3 = Number of serious and fatal accidents due to influence of alcohol ( ’00) P4 = Experience (ratio of vehicles with drivers of less than 5 years ’ experience to total number of vehicles involved in accidents) P5 = Sex (ratio of male drivers to total number of drivers involved in accidents) |
| • | The numbers given are ratios explained in (2). For example, 0.28 in column two row six means that for every 100 cases of road accident in Selangor during 1996 about 28 cases involved Chinese drivers. |
First, we look at the estimation of parameters for the ULFR model containing the state of mind measurement error for drivers age (P1) is given as
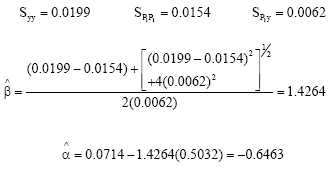 |
therefore, the ULFR model is
| Table 2: | Estimated parameters, coefficient of determination for the ULFR and SL models and the effect of measurement error |
 | |
with the coefficient of determination, ![]() = 0.4408
= 0.4408 ![]() (see Result 3). Comparing with the SL model
(see Result 3). Comparing with the SL model
the result shows that the ULFR model explains the variability of Y better than the SL model (![]() >R2). The SL model explains 12.31% of the variance of the number of road accidents but it increases to 44.08% when conditioned to ‘state of mind ’ factor. This suggests that the state of mind explains 31.77% (Ee =
>R2). The SL model explains 12.31% of the variance of the number of road accidents but it increases to 44.08% when conditioned to ‘state of mind ’ factor. This suggests that the state of mind explains 31.77% (Ee = ![]() -
-![]() ) of the variance of road accident number.
) of the variance of road accident number.
It is clearly show (Table 2) that the ULFR model gives a better fit than the SL model with higher COD. The SL model indicates that variables P1, P3 and P5 are not significantly contribute to the road accident rates. The first interpretation opposes other studies (Arthur and Little, 1970; IATSS, 1988; OECD Road Research Group, 1978; OECD Scientific Export Group, 1986) that age, gentle and alcoholic are important factors. However, when the state of mind is introduced, the three variables, especially P5 become important and it may use to explain causal relationship of the road accident. For example, we say the younger driver may be the cause of higher accident rates because of their driving attitude or tendency to take risks.
The introduction of state of mind does not increase the COD of variables P2 and P4 significantly. This suggests that the driver ’s race and experience are two exact predictor of road accident. On the other hand, both ![]() and
and ![]() indicate race and driving experience are not significantly explained the road accident model. Henceforth, only variables P1, P3 and P5 are recommended for further analysis such as multiple regression.
indicate race and driving experience are not significantly explained the road accident model. Henceforth, only variables P1, P3 and P5 are recommended for further analysis such as multiple regression.
CONCLUSION AND FURTHER WORK
In this study, the COD of ULFR is proposed and it properties are investigated. The proposed COD and the COD of ordinary linear regression model are used to investigate the effect of measurement error and hence try to explain the causal relationship of the model. It is a useful way to check whether a variable is reasonably assumed to be independent. This study on the Malaysian road accident problem demonstrates that the effect of the state of mind, indicated by the measurement error is clear but different in all factors.
However, confirmation of the causal properties in the ULFR model may be further strengthening by studying further the distribution of ![]() . The multivariate version of ULFR may also be considered in further studies.
. The multivariate version of ULFR may also be considered in further studies.
REFERENCES
- Box, G.E.P. and D.R. Cox, 1964. An analysis of transformation. J. Roy. Stat. Soci., 26: 211-252.
Direct Link - Dolby, G.R., 1976. The ultrastructural relation: A synthesis of the functional and structural relations. Biometrika, 63: 39-50.
CrossRefDirect Link - Umar, R.S.R., M.G, Mackay and B.L, Hill, 1995. Preliminary analysis of exclusive motorcycle lanes along the federal highway FO2, Shah Alam, Malaysia. J. IATSS Res., 19: 93-98.
Direct Link