
Md. Abdus Salam Akanda
Not Available
Maksuda Khanam
Not Available
M. Ataharul Islam
Not Available
Journal of Applied Sciences
Year: 2005 | Volume: 5 | Issue: 7 | Page No.: 1214-1218







ABSTRACT
Analysis of data with repeated measures is often accomplished through the use of Generalized Estimating Equations (GEE) methodology. Although methods exist for assessing the adequacy of the fitted models for uncorrelated data with likelihood methods, it is not appropriate to use these methods for models fitted with GEE methodology. Barnhart and Williamson[1] proposed model-based and robust (empirically corrected) goodness-of-fit tests for GEE modeling with binary responses based on partitioning the space of covariates into distinct regions and forming score statistics that are asymptotically distributed as chi-square random variables with the appropriate degrees of freedom. In their suggested GEE approach the correlation between two responses was not considered. We here proposed an alternative procedure based on GEE where the correlation between two responses was considered. We extended their work using different correlation structures exchangeable, autoregressive and pairwise correlation along with their suggested identity correlation structure.
PDF Abstract XML References Citation
How to cite this article
Md. Abdus Salam Akanda, Maksuda Khanam and M. Ataharul Islam, 2005. Comparison of Goodness-of-Fit Tests for GEE Modeling with Binary Responses to Diabetes Mellitus. Journal of Applied Sciences, 5: 1214-1218.
DOI: 10.3923/jas.2005.1214.1218
URL: https://scialert.net/abstract/?doi=jas.2005.1214.1218
DOI: 10.3923/jas.2005.1214.1218
URL: https://scialert.net/abstract/?doi=jas.2005.1214.1218
INTRODUCTION
The use of Generalized Estimating Equations (GEE) to analyze repeated binary data has become increasingly common in the health sciences. The analysis of correlated binary responses is often accomplished through the use of GEE methodology for parameter estimation. Assessment of the adequacy of the fitted GEE model is problematic since no likelihood exists and the residuals are correlated within a cluster. Tsiatis[2] proposed a goodness-of-fit test for the logistic regression model which is asymptotically chi-squared and is computed as a quadratic form of observed counts minus the expected counts. Stuart[3] proposed a goodness-of-fit test statistic for regression with heterogeneous variance, which is asymptotically chi-square if the given model is correct. The test statistic is computed as a quadratic form of observed minus predicted responses. Cessie[4] discussed a new global test statistic for models with continuous covariates and binary response is introduced. The test statistic is based on nonparametric kernel methods. Explicit expressions are given the mean and variance of the test statistic. Asymptotic properties are considered and approximate corrections due to parameter estimation are presented. Also Cessie[5] considered testing the goodness-of-fit of regression models. Emphasis is on a goodness-of-fit test for generalized linear models with canonical link function and known dispersion parameter. The test based on the score test for extra variation in a random effect model. By choosing a suitable form for the dispersion matrix, a goodness-of-fit test statistic is obtained which is quite similar to test statistics based on non-parametric kernel methods. The aim of present study was to utilize the BIRDEM data to parameter estimate in the main effect model and another model which includes the same main effects, the regions, time effects and interaction effects and then to test the goodness-of-fit by using various correlation structures.
Generalized Estimating Equation (GEE): The GEE approach provides consistent estimators of the regression parameters which needs only the correct specification of the form of the mean function μi, of the vector of responses for each individual.
Let us consider that each individual is observed for T occasions. Thus we have a Y x 1 random vector of responses for the ith individual where the response variable is binary. Notationally,
Where, the binary random variable Yit = 1 if at time t, the subject i has response 1, i.e., success and 0 otherwise. Here the response variable is dichotomous. We took k independent variables, so for ith individual we have a T x k matrix of covariates.
Notationally,
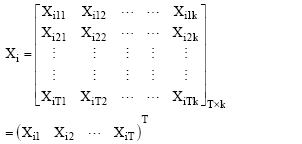 |
The usual GEE modeling for binary outcomes have the following setting:
| (1) |
The mean vector is
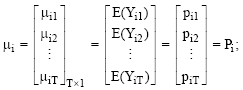 |
Where:
So the variance of yij is ![]()
And the variance covariance matrix of yi is given by:
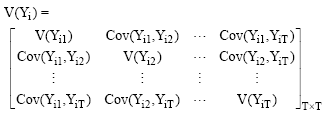 |
Estimation of β is obtained by solving the generalized estimating equations[6,7],
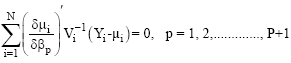 | (2) |
where, Ri is the working correlation matrix for Yi.
Goodness-of-fit test: By first partitioning the covariate space ![]() into M distinct region in P-dimensional space. Let be an
into M distinct region in P-dimensional space. Let be an ![]() be an M x 1 vector, where, Iitm is the indicator variable that equals one if the ith subject is in the mth region at the tth occasion and zero otherwise. They define the T x M matrix Ii as:
be an M x 1 vector, where, Iitm is the indicator variable that equals one if the ith subject is in the mth region at the tth occasion and zero otherwise. They define the T x M matrix Ii as:
| (3) |
Let ZT be the T x (T-1) matrix where the first row has entries zero and the remaining (T-1) rows form a (T-1) x (T-1) identity matrix. Consider the model :
| (4) |
Where, ![]() is a T x (T-1) M matrix and 0 is a (T-1) M x 1 vector of zeros. Note that τ is the (T-1) x 1 vector of time effects (the first occasion is the reference time point), γ is the M x 1 vector of region effects and ρ is the (T-1) M x 1 vector of time and region interaction effects because each column of Si results from component wise multiplication of two column vectors, one column vector from ZT and the other from Ii. A goodness-of-fit statistic consists of testing H0: θ = 0, where, θ = [τ’, γ’, ρ’]’ is a J x 1 vector with J = (T-1)+M+(T-1)M.
is a T x (T-1) M matrix and 0 is a (T-1) M x 1 vector of zeros. Note that τ is the (T-1) x 1 vector of time effects (the first occasion is the reference time point), γ is the M x 1 vector of region effects and ρ is the (T-1) M x 1 vector of time and region interaction effects because each column of Si results from component wise multiplication of two column vectors, one column vector from ZT and the other from Ii. A goodness-of-fit statistic consists of testing H0: θ = 0, where, θ = [τ’, γ’, ρ’]’ is a J x 1 vector with J = (T-1)+M+(T-1)M.
Let L = P+1+J be the number of parameters in the model presented in (4). Denote U be the L x 1 vector with lth component:
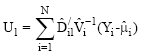 | (5) |
for ![]()
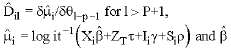 |
is obtained as the solution to (2). Then under H0: θ = 0, the asymptotic distribution of U is multivariate normal with mean zero and covariance matrix[6]:
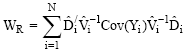 | (6) |
Where, ![]() is a T x T matrix. Note that cov (Yi) can be consistently estimated by
is a T x T matrix. Note that cov (Yi) can be consistently estimated by ![]() If the correlation matrix Ri is correctly specified, then the asymptotic covariance matrix U reduces to
If the correlation matrix Ri is correctly specified, then the asymptotic covariance matrix U reduces to 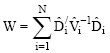
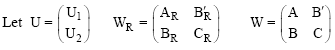 |
be the partitioning for U, WR and W, where, U2 is the J x 1 vector and CR and C are J x J matrices. Under H0: θ=0, both the proposed robust (empirically corrected) goodness-of-fit test statistic:
And the proposed model-based goodness-of-fit test statistic:
Are asymptotically distributed as chi-square random variables with:
Where, G¯ is any generalized inverse of the matrix G. The degree-of-freedom for chi-square random variables do not equal the number of parameters in θ because of linear dependencies between the covariates in the model and the covariates from the region partitioning, i.e., ![]() are singular matrices. Let H1 and H2 be the design matrices in models (1) and (4), respectively.
are singular matrices. Let H1 and H2 be the design matrices in models (1) and (4), respectively.
Then intuitively, the degrees-of-freedom of the above chi-square random variables is equal to rank (H2)-(H1). Let ![]() design matrix for the ith subject in model (4). It is easily shown that the tj th element of
design matrix for the ith subject in model (4). It is easily shown that the tj th element of ![]() is equal to
is equal to ![]() Therefore, the goodness-of-fit test statistics Q and QR can be readily calculated once
Therefore, the goodness-of-fit test statistics Q and QR can be readily calculated once![]() is obtained from the estimating Eq. 2.
is obtained from the estimating Eq. 2.
Data set and covariates: In our study we have used the repeated measures data diabetes mellitus to carry out the analysis. Here the follow up data on 995 patients registered at BIRDEM (Bangladesh Institute of Research and Rehabilitation in Diabetes, Endocrine and Metabolic disorders) in 1984-94 is used to identify the risk factors responsible for the transitions from controlled diabetic to confirmed diabetic state as well as confirm diabetic to controlled stage of diabetes. The response variable is defined in terms of the observed glucose level two hours of 75 g-glucose load follow-up visit. The cut-off point for the blood glucose level is 11.1 mmol L-1. If the observed response is less than 11.1, then the patient is define as non diabetic (categorized as 0) if the response is greater than or equal to 11.1 then the patient is said to be diabetic (categorized as 1). We included two independent variables in the study. They are age and sex. Out of these variables, age represents the age responds at each visit. The variable is a continuous variable and used directly in the analysis. Sex is categorical variables. Here sex is a dichotomous variable with two categories 0 and 1, 0 stands for female and 1 stands for male. In order to assess the performance of the proposed goodness-of-fit tests, we used data simulated with known distributions from models in the alternative hypothesis to test the goodness-of-fit. To conduct the proposed goodness-of-fit tests, the following regions were partitioned as region1 if age greater than or equal to 50 and male, region 2 if age greater than or equal to 50 and female, region 3 if age less than 50 and male and region 4 if age less than 50 and female. If any individual occurs any of the four regions then indicate 1 otherwise 0. Time effect represents the two consecutive visits. Time effect is a dichotomous variable with two categories 0 and 1, 0 stands for first visit and 1 stands for second visit. Interaction 1, interaction 2, interaction 3, interaction 4 are component wise multiplication of region 1, region 2, region 3, region 4 and time effect.
RESULTS AND DISCUSSION
The logistic regression model is considered as one of the most important and widely applicable techniques in analyzing repeated outcome variables. To assess the fit of a model, it is necessary to identify the influential elements. In the logistic regression analysis for repeated binary measures we adjust for setting and the covariates. We assumed independence, exchangeable, autoregressive and pairwise working correlation structures and we obtained standard errors. Table 1 lists the parameter estimates and standard errors for the initial model having only main effects.
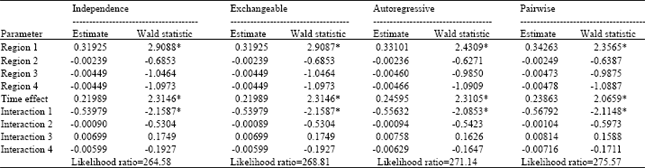
According to likelihood test the null hypothesis is rejected under all correlation structures in GEE. In this case has an interpretation that at least one of the coefficients is different from zero. According to Wald test sex is significant at 5% level of significance under independence, exchangeable, autoregressive and pairwise correlation structures. There exits positive association between the response variable and sex. The estimated coefficient of the variable age is found to be insignificant in all cases. Hence it may be conclude that these variables has no significant effect on the transition from confirmed diabetes state to controlled diabetes state. In terms of odds ratio, we may comment that, male patients are 1.240775 times likely to develop diabetes as compared to their counterparts. We considered additions to this main effects model to provide a better fit to the data. Table 2 displays the results from a model that includes regions, time effects and interactions.
In this case we see that several of the effects are significant, indicating their importance in modeling. Reject the null hypothesis by likelihood test under independence, exchangeable autoregressive and pairwise correlation structures. So rejection of null hypotheses in this case has an interpretation that at least one of the coefficients is different from zero. We also found that under all assumptions region 1 and time effect show positive association and interaction1 shows negative association.
| Table 1: | Estimates obtained by GEE assuming various correlation structures within repeated outcomes with associated Wald test |
 | |
| *Significant at p<0.05 | |
| Table 2: | Estimates obtained Barnhart and Williamson’s model by GEE assuming various correlation structures within repeated outcomes with associated Wald test |
 | |
| Table 3: | Goodness-of-fit by using various correlation structures |
 | |
Among these variation region1, time effect and interaction1 are significant at 5% level of significance in all cases. The other coefficients of the variables are found to be insignificant in all cases. Hence it may be conclude that these variables has no significant effect on the transition from confirmed diabetes state to controlled diabetes state.
From the Table 3, the model suggested by Barnhart and Williamson[1] is highly significant by model based test. In this case has an interpretation that at least one of the coefficients is different from zero. Also we see that the null hypothesis is rejected by the empirically corrected test and the model (4) is highly significant. In this case has an interpretation that the covariates have significant effect. The both goodness-of-fit test provided no evidence for lack of fit by adding regions, time effect and interaction effects.
CONCLUSIONS
We fit two models to the data. The first model only includes the main effects of age and sex and the second model includes the same main effects and the treatment and time interaction. Because all the covariates are discrete, the covariate categories were used to form four regions with frequencies. Both the goodness-of-fit tests suggest that the model with only main effects did not fit the data well. There is a significant time and treatment interaction effect indicating that patients with new treatment improved significantly faster than the patients with the standard treatment. The model with this interaction term included has a good fit to the data. The parameter estimates and the goodness-of-fit tests obtained here are very similar to the results obtained by using a weighted least squares approach. Thus, the goodness-of-fit tests successfully detected the interpretation departure and the efficiencies of the estimates of the Barnhart and Williamson’s suggested model for identity correlation is higher than that of our suggested exchangeable correlation, autoregressive correlation and pairwise correlation.
ACKNOWLEDGMENTS
We would like to express our gratitude to the Director of BIRDEM for giving us kind permission to use their data. We are indebted to the Chairman, Department of Statistics, University of Dhaka, Bangladesh for his kind cooperation through this research.
REFERENCES
- Liang, K.Y. and S.L. Zeger, 1986. Longitudinal data analysis using generalized linear models. Biometrika, 73: 13-22.
Direct Link
Dr. Kalipada Sen Reply
This is excellent pice of emperical research work.
William Robert Reply
This paper is interesting for the application of GEE model.
Trung Hung Vo Reply
Authors nicely presented the alternative procedure based on GEE where the correlation structures between two responses are considered. Thanks a lot to authors for this manuscript.