
N. Badrinath
Department of Computer Science and Engineering, Bharathidasan University, Khajamalai Campus, Tiruchirapalli, 620014, Tamil Nadu, India
G. Gopinath
Department of Computer Science and Engineering, Bharathidasan University, Khajamalai Campus, Tiruchirapalli, 620014, Tamil Nadu, India
K.S. Ravichandran
School of Computing, SASTRA University, Thanjavur, 613 401, Tamil Nadu, India
Journal of Artificial Intelligence
Year: 2013 | Volume: 6 | Issue: 4 | Page No.: 245-256







ABSTRACT
This study proposes hybrid techniques which are based on Artificial Bee Colony (ABC) algorithm for data preprocessing and Fuzzy Extreme Learning Machine (FELM) classifier for an automatic detection of the Erythemato-Squamous Diseases (ESD). This ESDs require huge computational efforts to predict the diseases because almost all the six ESD diseases namely, psoriasis, lichen planus, seboreic dermatitis, pityriasis rubra pilaris, chronic dermatitis and pityriasis rosea have common features for more than 90%. In the recent survey it has been highlighted that, there are many machine learning algorithms performing better than the conventional techniques. In this study, we propose threshold based ABC-FELM algorithm which is used for both future extraction as well as the classifier to enhance the accuracy of the prediction of ESDs and computational time. Moreover, this hybrid mechanism is implemented and tested with 366 original patients’ datasets. The threshold based data preprocessing reduces the dimensionality of the datasets considerably and hence it improves the time complexity. Finally, the proposed methodologies proved to be a potential solution for the diagnosis of ESD with significant improvement in computational time, namely less than 1 second and the accuracy (99.57%) compared to other models discussed in the recent literature.
PDF Abstract XML References Citation
Received: October 15, 2013;
Accepted: January 15, 2014;
Published: March 28, 2014
How to cite this article
N. Badrinath, G. Gopinath and K.S. Ravichandran, 2013. Design of Automatic Detection of Erythemato-squamous Diseases Through Threshold-based ABC-FELM Algorithm. Journal of Artificial Intelligence, 6: 245-256.
DOI: 10.3923/jai.2013.245.256
URL: https://scialert.net/abstract/?doi=jai.2013.245.256
DOI: 10.3923/jai.2013.245.256
URL: https://scialert.net/abstract/?doi=jai.2013.245.256
INTRODUCTION
Recent studies prove that the machine learning is one of the most powerful mechanisms that are used for diagnoses of diverse diseases and other areas of research. The Detection of Erythemato-Squamous Diseases (DESD) is a difficult problem in dermatology as these diseases display more than 90% common features for both clinical and histopathological features (Guvenir et al., 1998; Ubeyli and Guler, 2005). In this study, we propose a new hybrid mechanism to inbuilt two powerful mechanisms called the ABC algorithm and FELM classifier for the DESD. In this work, ABC algorithm is used for a feature selection and FELM is used for a classification.
Several researchers have been contributing many machine learning algorithms in medical diagnoses especially, in the field of DESD which are based on the techniques like fuzzy logic, Artificial Neural Networks (ANN), Support Vector Machine (SVM), among others. The interface design of the automatic DESD is required for the dermatologist to access the diseases accurately with less computational time. All the machine learning algorithms discussed so far in the recent literature are all time consuming and are less accurate. This study proposes a hybrid mechanism to address both the issues, namely accuracy and time.
Identifying and extracting information through the pattern analysis of any task through feature selection and extraction which requires the large amount of datasets. Feature extraction normally reduces the dimensionality of the datasets and it eliminates the irrelevant, ambiguous and redundant data. In turn it extracts the most relevant data towards the features selection and it is formulated into an n-dimensional feature vector.
Feature selection is a crucial preprocessing technique for effective data analysis and it reduces the time complexity as well as it improves the accuracy of the data analysis process. This study focuses a feature selection method for data analysis based on ABC algorithm and that can be used in different knowledge domains through wrapper and forward strategies. This algorithm is mainly used for solving optimization problems and now-a-days it can also be used for feature selection and extractions.
The learning speed of the feed-forward neural networks depends on (1) Best gradient based learning algorithms are used and (2) All the parameters of the problem are tuned iteratively with the help of the gradient algorithm. But, in many times it is difficult to concentrate the above reasons, because it is largely varying from problem to problem. In (Huang, 2006) developed a new and powerful algorithm, called ELM which is a feed-forward, single-layered, neural networks (SLFNs) which randomly selects the hidden nodes and analytically computes the outputs of SLFNs. Furthermore, (Huang et al., 2006) proved that, the speed of the ELM is very fast than it is compared to other multi-layered feed-forward neural networks.
In this work, the fuzzy component is incorporated with the existing ELM algorithm and the result mechanism is called Fuzzy based ELM (FELM). A typical two-stage dimensionality reduction of ABC-FELM structure is given in Fig. 1.
The main aim of this work is to design a Graphical User Interface (GUI) and it will be useful for the dermatologist to detect the ESDs accurately with high accuracy and very less computational time.
DIFFERENTIAL DIAGNOSIS OF ESD AND ITS BACKGROUND WORK
The differential diagnoses of ESD, namely psoriasis, seboreic dermatitis, lichen planus, pityriasis rosea, chronic dermatitis and pityriasis rubra pilaris are difficult problems in dermatology. The problems in predicting the diseases shall share for almost 90% common clinical features of erythema and scaling. These diseases frequently appeared in white skin people especially in USA and UK and it rarely appears in Asian countries.
 | |
| Fig. 1: | A typical structure of FELM |
| Table 1: | Data set used- 34 features and 6 diseases |
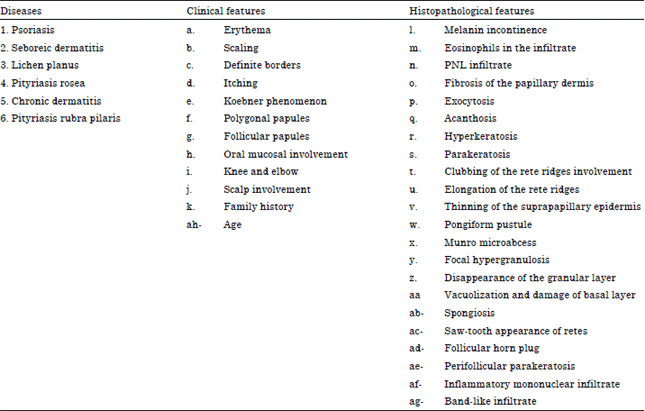 | |
At raw hand, all the diseases look closer alike erythema and scaling but when inspected more rigorously, some patients have the typical clinical features of the disease at the predilection sites while another group has typical localizations. Initially, the intensity of the erythma and scaling was calculated for every patient with the help of 12 clinical features and then it is further analyzed with the help of other 24 histopathological features. The clinical and histopathological features are given in Table 1.
Most of the time, the patients can be diagnosed only with the help of the clinical features and some exceptional cases biopsy is also required for further confirmation. Dermatologist can also use histopathological features for final confirmation of the diseases through skin samples. This also helps the dermatologist to identify the patients who have some other diseases at the beginning stage. For example, when we test lichen planus disease it may lead to the patient having melanin at the beginning stage.
Background work: In recent days, machine learning is one of the most important methodologies of diagnosis of diverse diseases and other areas of research. The DESD is a tough problem in dermatology as these diseases display common features with some minor differences and it consists of six diseases which are psoriasis, lichen planus, seboreic dermatitis, pityriasis rubra pilaris, chronic dermatitis and pityriasis rosea. These diseases share all clinical features with iota of difference and also many histopathological features (Guvenir et al., 1998; Ubeyli and Guler, 2005). Fuzzy set theory is used as decision making process in many areas of uncertainty/ambiguity involved in medical diagnosis problems. These fuzzy sets have gained increasing interest and attention in this modern world of information and technology, pattern recognition, data analysis, production technique, diagnostics, decision making, etc. (Ubeyli and Guler, 2005). Though neural networks and SVM plays an important role in machine learning and data analysis, some challenging issues exits which are intensive human intervene, slow learning speed, poor learning, scalability and so on.
Few researchers have been concentrating the differential diagnosis of ESD and some of the important results are listed here. The major contribution is given by Guvenir at the initial stages and Ubeyli in the later stages. The period considered here is 1998 to till date. The following table explains all the works related to the prediction of ESDs with the help of the machine learning algorithms.
In 1998, the voting algorithm was proposed by Guvenir and Cakir (2010) and they used for diagnosing the ESDs in a better way. Furthermore, the prediction of ESDs has done by Guvenir and Emeksiz (2000) with the help of three classifiers namely, nearest neighborhood classifier, bayesian classifier and voting feature intervals. Castellano et al. (2003) presented an application of a particular neuro-fuzzy system, called KERNEL which has the ability to extract and refine knowledge starting directly from observational data making use of neural learning. Nanni (2006) presented an ensemble of Support Vector Machines (SVM) based on random subspace and feature selection is developed. Each class has a ’favorite’ class and the best feature is calculated to discriminate the class. Ubeyli (2008) presented a method based on the implementation of multiclass SVM with error correcting output codes. An approach based on combined neural networks, where the second level of the network uses output of the first level as input, to improve accuracy in detection of the diseases was presented by Ubeyli (2009). In the same year, Parthiban and Subramanian (2009) described the determination of the intelligent agent for detection of erythemato-squamous diseases by CANFIS and genetic algorithm. Again, Guvenir and Cakir (2010) discussed k-means algorithm for the prediction of ESDs. Davar et al. (2011) described the diagnosis model based on catfish binary particle swarm optimization, kernelized support vector machines and association rules as feature selection method to diagnose ESD. An approach based on ensemble of data mining methods. However, these methods have drawbacks like slow learning speed, more time consumption and need more number of iterations as presented by Elsayad (2010) and Xie et al. (2012) designed a new feature selection procedure to find the data preprocessing and hence it leads to the good diagnose of erythemato-squamous diseases. Again, Xie et al. (2013) developed two-stage hybrid feature selection algorithm for predicting ESDs . Aruna et al. (2012) developed a hybrid feature selection method IGSBFS and it reduces the computational time and gives high percentage of accuracy in terms of diagnose of diseases. Ravichandran et al. (2013) discussed various machine learning algorithms including ELM algorithm to diagnose ESD its performance which is high and the computational time is reduced to less than 1 min. In this study no data preprocessing has been discussed. The performance of accuracy is high whereas the time complexity is very less when compared to all other machine learning algorithms.
Badrinath et al. (2013) proposed adaboost and its hybrid algorithms for the detection of erythemato-squamous diseases. The following steps have been used to design a GUI for automatic detection of ESDs: (1) To find the feature selection for all the 34 parameters involved in the ESD, (2) Association rules are then be used to find α% of transactions (diseases) to meet β% of the features of the diseases, (3) To find the support value of all the subset of α transaction from α% of transactions and find the dominant subset through “Apriori Algorithm” and (4) Adaboost and its hybrid classifiers are used to classify the diseases. In this case, the percentage of accuracy is increased to 99.57% and the time complexity is very high when compared to ELM.
This study aims to increase the percentage of accuracy and at the same time the computational time will reduce to less than 1 min. The proposed algorithm will address both the issues and its performance analysis with other machine learning algorithms as given in Table 4.
The fuzzy set theory in generalization of Boolean algebra can be further explained as process involving gradual transition that are used to classify classes, in place of conventional crisp boundaries, the fuzzy values give accurate results when given as input compared to normal input values. By combining fuzzy logic and ELM, even some minor deviations, specified in the linguistic rules can be smoothened during its input/output data training. When these proposed models were evaluated and its performances were reported, significant improvement in speed and accuracy compared to the previous models were achieved.
In this study, dermatology database consists of 366 patients’ reports of ESD and was compiled by N. Ilter and H.A. Guvenir of Turkey (Ubeyli and Guler, 2005; Ubeyli and Dogdu, 2010; Ubeyli, 2008, 2009). In this database 34 features of the patients were recorded and this has been used for testing with the proposed methods.
ABC algorithm: ABC algorithm was initially developed by Karaboga (2005) and it is used for optimizing numeric related problems. This algorithm is simple, robust and genetic based stochastic optimization algorithms. It simulates the elegant and intelligent foraging behavior of honey bee swarms. The performance of ABC was tested with some popular machine learning algorithms like genetic algorithm, particle swarm optimization and differential evolution; and it is proved that the performance of ABC algorithm is superior to other recent machine learning algorithms (Basturk and Karaboga, 2006; Karaboga and Basturk, 2007a, b). This algorithm contains three groups of artificial bees which are employed bees, onlookers and scouts. Employed bees are the bees which are already visited the food sources. Onlookers’ bees are the bees which are waiting on the dance area for finalizing the decision of selecting the food source. The last kinds of bees are called scout bees which discover the new food sources and this kind of the dancing bees to select the random path to reach the new food sources. The random path is called the optimization steps of the given optimization problem.
The position of food source is called the solution of the optimization problem and the value of the nectar (amount of food source) is calculated through the fitness formula and its procedure is given below.
In this procedure, first we have to eliminate less important or contribution features before we apply the actual ABC algorithm:
| • | Given the 12 clinical and 22 histopathological conventional 0-1 features as input of the problem. All these feature are then converted into fuzzy based on Gaussian and Bell-shaped fuzzy membership function |
| • | For removing the less contributed features, we have to convert the fuzzy features into conventional 0-1 features with the help of the threshold value Ω: |
If the degree of the feature is <Ω then (Eq. 1):
| (1) |
In this problem, we have considered the minimum threshold value Ω be 0.35. This minimum threshold value is varying between the problems. The resultant 0-1 conventional vector of 34 clinical and histopathological features will be sent to the input of the ABC algorithm. This process will reduce the dimensionality considerably when compared to applying ABC algorithm directly (Eq. 2):
| (2) |
| • | Let us assume that there are N numbers of artificial bees taken as random and this is called size of the population. The first N/2 bees are assumed to be the employed bees and the second N/2 bees are assumed as onlookers’ bees and hence, N/2 solution exists in this problem. In this study, ABC algorithm generates a randomly distributed initial population P (C = 0) of 234 solutions (position of the food sources) and each solution is represented by a 34-dimensional vector. Hence, the number of the employed bees is equal to the number of solutions in the population. |
At the initial step, the food source positions are generated randomly and then find the most appropriate population is obtained after repeatedly applying cycles of the optimization search processes of all the three types of bees, namely employed, onlooker and scout. The pseudo code for obtaining optimal population is given Table 2.
Design of GUI for automatic DESD using ABC feature selection and FELM classifier: All the experienced doctors in this field are not familiar to use high performance computer in their professions. For that purpose, we need to construct a GUI design that will accept all the features of the patient and then the proposed system will predict the disease exactly by taking less computational time. It is already proved that the computational efficiency that has shown ELM very high when compared to all other technologies which was used in the recent literature.
Dermatology department in a hospital records the history of all the patients which contains the information of test, results, histopathological information and other details like family history, age and so on. Based on the test and other results, doctors have difficulty to predict the erythemato-squamous disease. The proposed mechanism will help the doctors to predict the disease exactly.
The design of GUI for the DESD is based on the machine learning algorithms, namely ABC algorithm and FELM classifier. This is very much helpful for the dermatologist to detect the diseases without biopsy and it can be predicted with very less computational time. The flow diagram of the proposed GUI architecture is given in Fig. 2.
| Table 2: | Pseudo code representation of ABC algorithm |
 | |
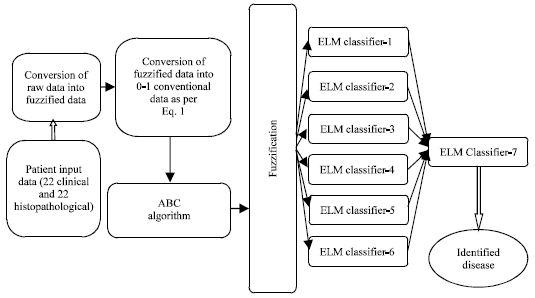 | |
| Fig. 2: | A typical GUI architecture for the prediction of ESDs through threshold based ABC-FELM algorithm |
The GUI consists of the following steps:
| • | In the proposed GUI, the input dataset of the patients consists of 34 features, out of which 12 are clinical features and 22 are histopathological features |
| • | Then, the dimensionality reduction is being done through ABC feature selection algorithm. In this problem, the datasets consists of 34 features are finally reduced to 22 features namely, ag, ac, aa, ae, f, l, o, t, y, v, g, h, u, ad, i, x, j, ab, p, n, e and z |
| • | From the reduced feature sets, we have to bifurcate into fuzzy and non-fuzzy input variables. The fuzzy input variables are linguistically classified into three levels, namely low, medium and high |
| • | Fuzzy and non-fuzzy input variables are then fed into all the six ELM classifiers and these six classifiers are used to classify all the six diseases of the ESDs. That is, classifier-1 gives the fuzzified output value of the disease-1 as far as the given input. Similarly, classifier-2 gives the fuzzified output value of the disease-2 and so on |
| • | Then, the output of the all the six classifiers are the inputs of the 7th classifier and its output will be called the significant ESDs of the patients |
The threshold-based ABC-FELM is achieved the better dimensionality reduction when compared to ABC-FELM algorithm.
From the available data sets (the reports of 366 patients was compiled by N. Ilter and H.A. Guvenir of Turkey (Ubeyli and Guler, 2005; Ubeyli and Dogdu, 2010; Ubeyli, 2008, 2009), ELM algorithm is trained with sufficiently large number of training data set. It is trained till the error tolerance is reached to 1e-06. In the trained system, test dataset is applied and the performance is measured. The performance of the proposed classifier is recorded for both data preprocessing stages, namely before and after data preprocessing. It is available in Fig. 3 and 4.
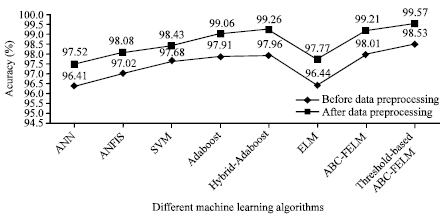 | |
| Fig. 3: | Performance Analysis between the proposed (ABC-FELM) and other machine learning algorithms |
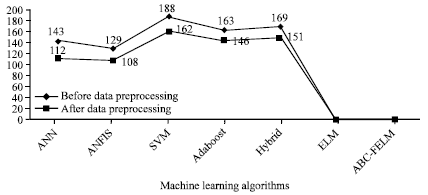 | |
| Fig. 4: | Computational time (sec) before and after data preprocessing |
EXPERIMENTAL RESULTS AND DISCUSSION
Even an experienced dermatologist has difficulty in identifying the ESDs because all those diseases have almost 90% of the unique features. In the technological era, the high performance computational facility is available in many places and with the help of its high computational efforts; one can easily determine the diseases exactly. In this research, we have to address mainly two issues, namely the accuracy and time. The recent literature survey shows that the accuracy of the DESD is improved to 93-95% before data preprocessing and it is reached to 96-99% after data preprocessing; where as in time, all the methods provides high computational complexity. In the proposed methods it out performs for both time as well as accuracy.
Out of 34 features listed in Table 1, ABC feature selection algorithm finds that there are 21 features are very crucial to decide the disease and other features are used as future references. The threshold based ABC-FELM increased the percentage of accuracy when compared to not using Eq. 1.
Without using equation, ABC algorithm reduces the features from 34 to 22 and following is the feature extraction. The dominant features are:
ag, ac, aa, ae, f, l, o, t, y, v, g, h, u, ad, i, x, j, ab, p, n, e, z
and its accuracy is 99.26% after applying ABC-FELM algorithm. Again, we find the extracted features after applying Eq. 1 called the ‘threshold-based ABC Algorithm’ and we obtain the following 21 features which are:
ag, aa, ae, ac, f, l, t, o, v, g, y, h, u, ad, i, x, ab, p, j, n, e
and its accuracy is raised from 99.26 to 99.57%. The advantage of the threshold-based ABC algorithm is to remove all irrelevant and less important features before applying ABC algorithm and it improves the percentage of accuracy. Clearly, the given data set is reduced to 64.7% without using Eq.1 and using Eq.1 it reduces to 61.7%. The performance analysis of before and after data processing of fuzzy based ELM and other machine learning algorithms are given in Fig. 3 and 4. The processing time for ABC-FELM and threshold-based ABC-FELM algorithm is same.
The entire dataset has been divided into training dataset (80%) and testing dataset (20%). The disease classification of the proposed methodologies is given in the form of the confusion matrix and it is represented in Table 3. The performance analysis of the proposed methodologies along with other methods which are recently published is given in Table 4.
| Table 3: | Confusion matrix |
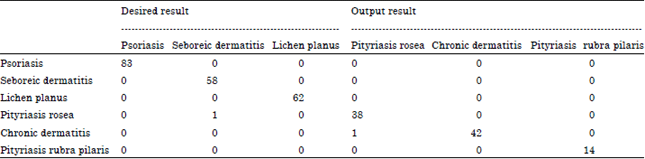 | |
| Table 4: | Performance analysis of the proposed method and other machine learning algorithm |
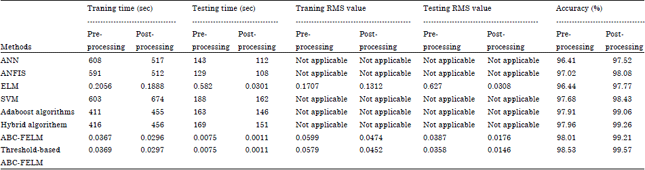 | |
Table 3 shows that the overall accuracy of the proposed ABC algorithm and fuzzy based ELM classifier after data preprocessing is 99.57% approximately with Kappa value is 0.98996. For all the kappa calculation methods, namely unweighted kappa, kappa with linear weight and kappa with quadratic weight, the percentage of accuracy is obtained almost the same.
The performance analysis of ANN, ANFIS, ELM, SVM, AdaBoost Algorithms (Modest), Hybrid-AdaBoost Algorithm (Adaboost and SVM) and the proposed algorithm is given in Table 4.
Table 4 shows that Hybrid-AdaBoost algorithm performs better than all other methods except threshold-based ABC-FELM and its accuracy is reached to 99.26% but the processing times are very high. The percentage of accuracy of the proposed threshold based ABC-FELM algorithm is 99.57% which is a little bit higher than Hybrid adaboost algorithms but the processing time is very low, that is less than 1 sec.
CONCLUSION
In this study, ABC-FELM algorithm was proposed for the detection of ESDs. The data preprocessing has been done here by using ABC algorithm which has certainly reduced the dimensionality of the data set and the time complexity. The fuzzy logic played an important role and was used to work with the uncertainty in differential diagnosis of ESDs which resulted in imprecise boundaries between the six diseases. Existing methods such as neural networks, SVM, ANFIS and ELM, AdaBoost algorithm, Hybrid Adaboost algorithm and the proposed ABC-FELM algorithm were discussed in the study. They were useful for result comparison and detailed analysis of the problem. The detailed analysis of the ABC-FELM algorithm produced some conclusions associated with the affect of 34 features in the detection of ESDs. The total classification accuracy of the threshold-based ABC-FELM algorithm was reached to 99.57%. Hence, to conclude we state that the proposed ABC-FELM algorithm can be of efficient use in the detection of ESD by considering speed and accuracy compared to other models.
REFERENCES
- Elsayad, A.M., 2010. Diagnosis of erythemato-squamous diseases using ensemble of data mining methods. ICGST-BIME J., 10: 13-23.
Direct Link - Aruna, S., L.V. Nandakishore and S.P. Rajagopalan, 2012. A hybrid feature selection method based on IGSBFS and naive bayes for the diagnosis of Erythemato-Squamous diseases. Int. J. Comput. Appl., 41: 13-18.
CrossRefDirect Link - Castellano, G., C. Castiello, A.M. Fanelli and C. Leone, 2003. Diagnosis of dermatological diseases by a neuro-fuzzy approach. Proceedings of the International Conference in Fuzzy Logic and Technology, September 10-12, 2003, Zittau, Germany, pp: 747-750.
Direct Link - Davar, G., H. Salimi, A.A. Bitaraf and Y. Khademian, 2011. Detection of erythemato-squamous diseases using AR-CatfishBPSO-KSVM. Signal Image Process.: Int. J., 2: 57-72.
Direct Link - Guvenir, H.A. and N. Emeksiz, 2000. An expert system for the differential diagnosis of erythemato-squamous diseases. Exp. Syst. Appl., 18: 43-49.
CrossRefDirect Link - Guvenir, H.A., G. Demiroz and N. Ilter, 1998. Learning differential diagnosis of erythemato-squamous diseases using voting feature intervals. Artificial Intell. Med., 13: 147-165.
CrossRefDirect Link - Guvenir, H.A. and M. Cakir, 2010. Voting features based classifier with feature construction and its application to predicting financial distress. Exp. Syst. Appl., 37: 1713-1718.
CrossRefDirect Link - Huang, G.B., Q.Y. Zhu and C.K. Siew, 2006. Extreme learning machine: Theory and applications. Neurocomputing, 70: 489-501.
CrossRefDirect Link - Karaboga, D. and B. Basturk, 2007. A powerful and efficient algorithm for numerical function optimization: Artificial Bee Colony (ABC) algorithm. J. Global Optim., 39: 459-471.
CrossRefDirect Link - Karaboga, D. and B. Basturk, 2007. Artificial Bee Colony (ABC) optimization algorithm for solving constrained optimization problems. Proceedings of the 12th International Fuzzy Systems Association World Congress, June 18-21, 2007, Springer, Berlin/Heidelberg, pp: 789-798.
Direct Link - Nanni, L., 2006. An ensemble of classifiers for the diagnosis of erythemato-squamous diseases. Neurocomputing, 69: 842-845.
CrossRef - Parthiban, L. and R. Subramanian, 2009. An intelligent agent for detection of erythemato- squamous diseases using Co-active Neuro-fuzzy inference system and genetic algorithm. Proceedings of the International Conference on Intelligent Agent and Multi-Agent Systems, July 22-24, 2009, Chennai, pp: 1-6.
CrossRef - Ravichandran, K.S., N. Badrinath, G. Gopinath, S. Ravalli and J. Sindhura, 2013. An efficient approach to an automatic detection of erythemato-squamous diseases. Neural Comput. Appl.
CrossRefDirect Link - Ubeyli, E.D. and I. Guler, 2005. Automatic detection of erythemato-squamous diseases using adaptive neuro-fuzzy inference systems. Comput. Biol. Med., 35: 421-433.
CrossRefDirect Link - Ubeyli, E.D. and E. Dogdu, 2010. Automatic detection of erythemato-squamous diseases using k-means clustering. J. Med. Syst., 34: 179-184.
CrossRefDirect Link - Ubeyli, E.D., 2008. Multiclass support vector machines for diagnosis of erythemato-squamous diseases. Exp. Syst. Appl., 35: 1733-1740.
CrossRefDirect Link - Ubeyli, E.D., 2009. Combined neural networks for diagnosis of erythemato-squamous diseases. Exp. Syst. Appl., 36: 5107-5112.
CrossRefDirect Link - Xie, J., J. Lei, W. Xie, X. Gao, Y. Shi and X. Liu, 2012. Novel hybrid feature selection algorithms for diagnosing erythemato-squamous diseases. Proceedings of the 1st International Conference on Health Information Science, April 8-10, 2012, Beijing, China, pp: 173-185.
CrossRef - Xie, J., J. Lei, W. Xie, Y. Shi and X. Liu, 2013. Two-stage hybrid feature selection algorithms for diagnosing erythemato-squamous diseases. Health Inform. Sci. Syst., Vol. 1.
CrossRefDirect Link