
P. B. Khanale
D.S.M. College, Parbhani, India
Journal of Artificial Intelligence
Year: 2010 | Volume: 3 | Issue: 3 | Page No.: 135-140







ABSTRACT
Marathi language is an Indo-Aryan language. It is one of the most popular language used by over ninety million people in India and rest of the world. It is the official language of Government of Maharashtra State, India. Various commercial transactions such as bank transactions takes place in Marathi, particularly in rural part of Maharashtra State. Many times it is needed to process numerals written in Marathi through computer. Recognition of Marathi Numerals is required in various applications where Marathi data need to be processed. It is also the first step towards language understanding. Here, I have proposed a Artificial Neural Network System that can recognize numerals (0-9) written in Marathi language. The system perfectly recognizes ideal numerals and performs reasonably accurate for noisy numerals.
PDF Abstract XML References Citation
Received: November 15, 2009;
Accepted: April 06, 2010;
Published: May 29, 2010
How to cite this article
P. B. Khanale, 2010. Recognition of Marathi Numerals Using Artificial Neural Network. Journal of Artificial Intelligence, 3: 135-140.
DOI: 10.3923/jai.2010.135.140
URL: https://scialert.net/abstract/?doi=jai.2010.135.140
DOI: 10.3923/jai.2010.135.140
URL: https://scialert.net/abstract/?doi=jai.2010.135.140
INTRODUCTION
Marathi is an Indo-Aryan language spoken by peoples of Maharashtra State, India. It is the official language of Maharashtra State, India and second language by other states such as Goa, India. Marathi language is used by over ninety million people world wide. It is a 1300 years old language evolving from Sanskrit language. In most part of Maharashtra, people use Marathi for their day to day work. They use Marathi numerals for their banking purposes and write payment slips using Marathi numerals. Particularly, in rural part, people can only read and write in Marathi has to use Marathi language for their every activity. Marathi is very weekly supported by computer systems. Only recently certain data publishing software are available. Marathi language understanding by machine is vast research area where a lot work is yet to be done. Here, study is prosing a Artificial Neural Network System that can recognize Marathi numerals.
Artificial Neural Network (ANN) is a information processing paradigm. It is inspired by biological nervous system such as brain. It is composed of simple elements operating in parallel (Al Daoud, 2009). These elements are called as neurons. The ANN can learn by example as like people. ANNs are widely used in area of data classification. A lot of research is carried out on digit recognition (Bahlmann et al., 2004; Isokoski, 2001; Lalomia, 1994; Pittman, 1991; Li, 1998; Liu et al., 2003). But no good citations are available for Marathi numerals recognition. The development of more powerful networks, better training algorithms and improved hardware has contributed in the revival of the field.
PROBLEM
A network is to be designed and trained to recognize ten (0-9) Marathi numerals. Marathi numerals are different from English numerals and their shapes are as shown in Fig. 1.
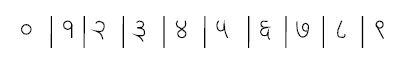 | |
| Fig. 1: | Marathi numerals 0-9 |
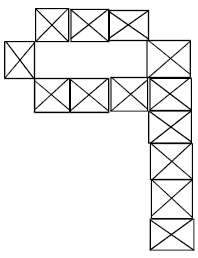 | |
| Fig. 2: | 5 by 7 representation of Marathi numeral one |
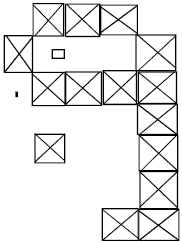 | |
| Fig. 3: | Noisy Numeral one |
An imaging system that digitizes each numeral centered in the system’s field of vision is prepared. The result is that each digit is represented by 5 by 7 grid of Boolean values. For example, numeral (One) is represented as shown in Fig. 2.
However, the system is not perfect and numerals may suffer from noise. Figure 3 gives such noisy numeral. The noise is in the form of un wanted additional values in image. Sometimes noise is in the form of small dots and some time they are larger values. It may change the shape and the recognition becomes difficult. Perfect classification of ideal vectors is required and reasonably accurate classification of noisy vectors is required.
The ten 35 element input vectors are defined in function PR1 as a matrix of input vectors called mnumeral. The target vectors are also defined with variable target. Each target is a ten element vector with 1 in the position of numeral it represents and 0 elsewhere. The numeral zero is represented by 1 in first element, one represented by 1 in second element and so on.
NEURAL NETWORK
Network receive 35 boolean values as a 35 element input vector. It responds to it, by outputting 10 element vector output with 1 in the numeral position and 0 elsewhere. Also, the network should handle noise, that is, network must make few mistakes with noise of mean 0 and standard deviation of 0.2 or less.
Network Architecture
Various types of architectures are available for ANN. The selected architecture is a two layer feed forward network with both the layers consisting of 10 neurons each. The performance of two layer network is much better than a single layer network. The transfer function selected is log-sigmoid function. Log-sigmoid is chosen because its output range 0-1 is perfect for learning to output Boolean values. Figure 4 shows the neural network.
In the Fig. 4, IW is input weight matrix of size 10 by 35, b is bias vector of size 10 by 1, F is log-sigmoid transfer function, a1 is first layer output, LW is layer weight matrix of size 10 by 10 and a2 is output of second layer which is output of network.
The input to bias vector is fix to 1. The equations for a1 and a2 are given in (1) and (2).
| (1) |
| (2) |
In Eq. 1 P is input vector. In Eq. 1 and 2, the symbol *stands for multiplication. In Eq. 1, the product of input weight matrix with input vector P is added to bias b. The logsig value of this is assigned to a1. In Eq. 2, the product of layer weight matrix and a1 is added to b. The logsig value of this is assigned to a2.
The neural network shown in Fig. 4 is created by using MATLAB.
Training of the Network
Once the network is initialized then we need to train the network. The network training is done with backpropogation algorithm (Leung and Cheng, 1996). In backpropogation, the network weights and biases are updated in the direction in which the performance function decreases most rapidly, that is, negative of gradient. It can be given by Eq. 3.
| (3) |
In Eq. 3, XK is Vector of current weights and biases, GK is current gradient, LK is learning rate. The symbol *stands for multiplication. Out of various batchpropogation, I have used a faster algorithm, that is, batch propogation with adaptive learning rate.
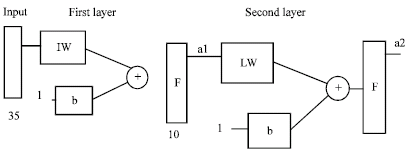 | |
| Fig. 4: | Diagram of neural network |
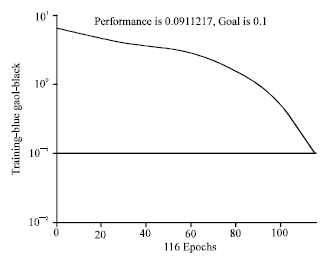 | |
| Fig. 5: | Training of network |
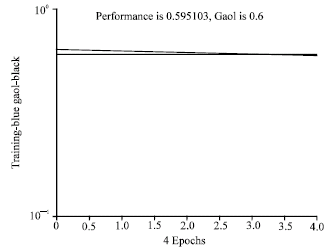 | |
| Fig. 6: | Training with noisy vector |
The performance function used is sum squared error (sse). The goal of sse was set to 0.1. Figure 5 shows training of network. The training of the network involves changing the biases and weights until the goal is achieved. The network is run in two passes- forward pass and backward pass. In forward pass output is calculated and error at output units is calculated. In backward pass the output unit error is used to alter weights on the output units. Then the error at hidden nodes is calculated by back-propagating the error at the output units through the weights and the weights on the hidden layers are altered using these values. Observe in Fig. 5 that, initially the error was high, but it goes on decreasing as number of epochs increases. The training stops when the goal is achieved.
Initially network was trained with ideal vectors until it has a 0.1 sum squared error. Then, the network was trained with 10 sets of ideal and noisy vectors. For noisy vectors, the goal of sse was set to 0.6. This value is set by certain understanding. It is normally more than that of with ideal vectors. One can test the network for other value as well. Figure 6 gives noisy vector training. Observe that, only after 4 epochs the goal is achieved. Then, again the network is trained with ideal vectors.
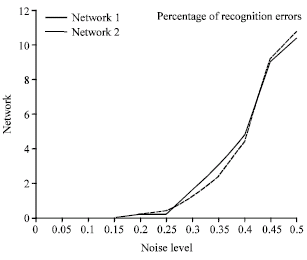 | |
| Fig. 7: | Performance of the network |
Testing of Network
After successful training, the network is ready to use. The network is tested on noisy numerals and its performance is given in Fig. 7. Observe that up to noise level 0.25 recognition rate is almost 100%.
CONCLUSION
Several work on recognition is carried by researcher, but still there is a scope for improvement. Here, Artificial Neural Network is successfully developed which can recognize Marathi numerals. Ideal numerals are recognized with accuracy 100%. Noisy numerals are recognized with reasonable accuracy.
REFERENCES
- Al-Daoud, E., 2009. A comparision between three neural network models for classification problems. Int. Artif. Intell., 2: 56-64.
CrossRefDirect Link - Liu, C.L., K. Nakashima, H. Sako and H. Fujisawa, 2003. Handwritten digit recognition: Benchmarking of state-of-the-art techniques. Patt. Recog., 36: 2271-2285.
CrossRef - Isokoski, P., 2001. Model for unistroke writing time. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, (HFCS'01), ACM Press, Seattle, pp: 357-364.
CrossRef - Lalomia, M., 1994. User acceptance of handwritten recognition accuracy. Proceedings of the CHI '94 Conference Companion on Human Factors in Computing Systems, April 24-28, ACM Press, Boston, pp: 107-108.
CrossRef - Leung, W.N. and K.S. Cheng, 1996. A stroke-order free chinese handwriting input system based on relative stroke positions and back-propagation networks. Proceedings of the 1996 ACM Symposium on Applied Computing, Feb. 17-19, ACM Press, Philidelphia, pp: 22-27.
CrossRef - Pittman, J.A., 1991. Recognizing handwritten text. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems: Reaching Through Technology, April 27-May 02, ACM Press, New Orleans, pp: 271-275.
CrossRef - Li, X., R. Plamondon and M. Parizeau, 1998. Model-based online handwritten digit recognition. Proceedings of 14th International Conference on Pattern Recognition, Aug. 16-20, Brisbane, Australia, pp: 1134-1136.
CrossRef