
Zhijie Zhao
School of Computer and Information Engineering, Harbin University of Commerce, Harbin, China
Zhimin Cao
School of Electronics Science, North-East Petroleum University, Daqing, China
Maoliu Lin
School of Electronics and Information Engineering, Harbin Insititute of Technology, Harbin, China
Xuesong Jin
School of Computer and Information Engineering, Harbin University of Commerce, Harbin, China
Information Technology Journal
Year: 2014 | Volume: 13 | Issue: 3 | Page No.: 414-424







ABSTRACT
In this study, for improving the performance of Motion Estimation (ME), a new Markov-Chain-Model based motion estimation method is proposed with a multi-class Support Vector Machine (SVM) classification network constructed to get one-step transition probabilities among initial prediction states used in this algorithm. Experimental results show that it is efficient to use the constructed SVM network in the Markov-Chain-Modeled Motion Estimation algorithm to various tested sequences.
PDF Abstract XML References Citation
Received: June 04, 2013;
Accepted: October 04, 2013;
Published: February 12, 2014
How to cite this article
Zhijie Zhao, Zhimin Cao, Maoliu Lin and Xuesong Jin, 2014. An Enhanced Markov-chain-modeled Motion Estimation Algorithm by using Support Vector Machine. Information Technology Journal, 13: 414-424.
DOI: 10.3923/itj.2014.414.424
URL: https://scialert.net/abstract/?doi=itj.2014.414.424
DOI: 10.3923/itj.2014.414.424
URL: https://scialert.net/abstract/?doi=itj.2014.414.424
INTRODUCTION
The digital multimedia coding, especially the digital video coding, has been extensively studied. It is well known that there is much of temporal-spatial redundancy existing in video sequence. To exploit the temporal-spatial redundancy, many kinds of block-matching ME algorithms have been widely developed. All of these algorithms are based on the idea that subdividing video frames into square Macro Blocks (MB) and then finding the Motion Vector (MV) for each block within a search range that minimizes the error criteria. The full search algorithm (FS) is a kind of exhaustive block matching method. It searches all of the possible points in the search range. However, this algorithm is terriblely time consuming. In order to improve the computational efficiency, lots of fast block matching algorithms have been proposed. These algorithms include: Three step search algorithm (TSS) (Koga et al., 1981), new three step search algorithm (NTSS) (Li et al., 1994), four step search algorithm (FSS) (Po and Ma, 1996), two dimensional logarithmic search algorithm (2D-LOG) (Jain and Jain, 1981), diamond search algorithm (DS) (Zhu and Ma, 2000), Hexagon-Based search algorithm (HEXBS) (Zhu et al., 2002). In additional, algorithms based on spatial or temporal correlations such as MVFAST (Hosur and Ma, 1998, 1999, 2000), PMVFAST (Tourapis et al., 2000, 2001) as well as multi-model based algorithms such as UMHexagonS used in H.264/AVC and method proposed in (Chen et al., 2006).
Among all of the algorithms mentioned above, there are two major deficiencies. Firstly, most of them exploit redundancy by using statistical properties of motion vector without considering the temporal redundancy. Secondly, they can hardly achieve satisfactory results among different video sequences with different motion activities.
In order to deal with these two problems to a certain extent, a fast Markov-Chain-Modeled ME method was proposed in Zhao et al. (2010). In that algorithm, the predicting mode of the starting point was modeled as a Markov Chain Model to exploit the temporal redundancy. But the transition probabilities were obtained in a statistical way. Therefore, there will be some increment of the computational cost.
In this study, the fast Markov-chain-modeled ME algorithm (MCMME) is optimized by adopting Support Vector Machine (SVM-MCMME). In the optimized algorithm, a classification network which of composed of many different SVMs is constructed to predict the states transition probabilities of the Markov-chain-model’s one-step transition matrix.
MCMME MOTION ESTIMATION METHOD
Early elimination of search: For consideration of the continuity of the video sequence, it is reasonable to believe that a large number of MBs are static (the corresponding MV is zero) or quasi-static (the corresponding MV approximate to zero). Furthermore, statistical results had shown that MVs are mainly scattered in the region of two pixel distance around the original point (Cheung and Po, 2002), especially the case of video sequence with low-motion activity. Therefore, if the current MB is static or quasi-static, search process should be terminated immediately before doing the model searching. It means that the corresponding criteria value should be calculated first to see whether or not it satisfies the static condition, e.g., SAD<512 in MVFAST. If so, the predicted MV is set to (0, 0). In some other algorithms, such as PMVFAST, the first checked point is the median of three MVs spatially adjacent to the current MB (top, top-right and left) which is called PMV here. If the PMV does not satisfy the stop criteria, a set of other MVs ((0, 0), MV of left MB (MVL), MV of top MB (MVT), MV of top-right MV (MVTR) and et al.,) are then tested before model searching.
To sum up, before model searching, a set of MVs (PRESET) are tested to decide whether stop or not. If none of the PRESET MVs satisfies the stopping conditions, a starting point correlated to motion activity for model searching should be decided.
Details of MCMME: The existing predicted ME algorithms are mainly based on the zero-centered or median-bias characteristic of motion vectors (Tourapis et al., 2000). A natural question is that whether or not the original point (0, 0) or the PMV can always being the best candidate MV for the first evaluation. To reveal the truth, the result of the subtraction of two continuous motion vector fields (MVF) is introduced here. Two continuous MVF and the corresponding MVDF of foreman.qcif are illustrated in Fig. 1.
From Fig. 1, it can be seen that there are more zero points in MVDF than MVF. Obviously, if the REFMV which is corresponding to the MB at the same spatial position of the current MB in reference frame is chose as the first tested MV, especially for low-activity video sequence, it will be more effective.
Traditionally, all of the PRESET MVs are tested to find whether or not the one that have minimum criteria value satisfy the stopping condition. Some methods (e.g., PMVFAST) test PRESET MVs in a fixed order. It is obvious that the majority for PRESET MVs testing mentioned above can not use the temporal correlation efficiently. In order to exploit temporal correlation existing in the test sequence more deeply, the test order of PRESET MVs should be rearranged according to the distribution feature of MVs or something else.
Base on this consideration, a Markov Chain Model was used to predict the test order. The PRESET are composed of (0, 0), PMV, MVT, MVL, MVTR and REFMV. Let:
Ω = {(mvxi, mvyi)|i = 1, 2, 3, 4, 5, 6} | (1) |
where, mvxi, mvyi denote the horizontal and the vertical components of the ith MV in the PRESET, respectively.
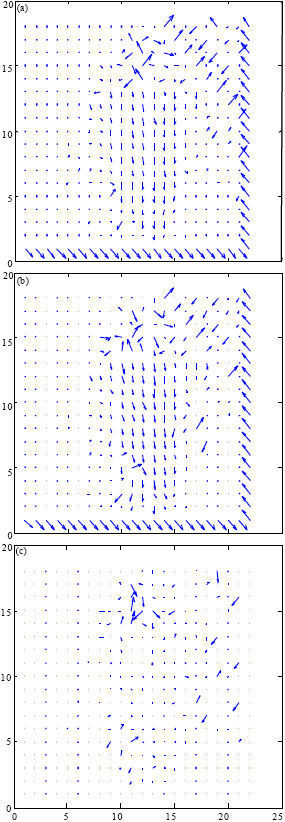 | |
| Fig. 1(a-c): | (a) and (b) are the two continuous MVFs (MVF12, MVF23) got from foreman.qcif test sequence and (c) The corresponding MVDF |
These six predicting MVs can be seen as six states. The criteria to determine the current state is:
| (2) |
where, mvxpre, mvypre denote the horizontal and vertical component of the predicted MV, respectively.
To consider the strong correlation among PMV, MVL,MVT and MVTR and to simplify the model, choosing (0, 0), REFMV as well as PMV to compose a state space as below:
SM = {S1, S2, S3} | (3) |
where SM is the state space. S1, S2, S3 denote REFMV predicting mode (temporal mode), original and PMV predicting mode (spatial mode), respectively.
Therefore, the simplified PRESET will be:
Ω = {(mvxi, mvyi)| i = 1, 2, 3} | (4) |
where, (mvxi, mvyi)|i = 1, 2, 3 denote REFMV, (0, 0) and PMV.
Until now, the issue for determining the state of the Markov chain model which is for describing the process of predicting tested MV, can be expressed as below:
| (5) |
State-transition diagram of the model is shown in Fig. 2.
Let fn be the predicting mode of MB located at a given position (r, c) in the nth frame of video sequences, then all of the predicting modes {fn: n≥0} of continuous MBs at the same location formed a Markov chain. That is, with ∀n≥0 and any state {i, j, i0,þ, in-1; i, j, i0,þ, in-1∈SM}, there will be:
p(fn+1 = j|fn = i, fn-1 = in-1,þ, f0 = i0) = p(fn+1 = j|fn = i) | (6) |
and then the state transition probability will be defined as:
pij (n, m) = p(fm = j|fn = I) m≥n | (7) |
and the one-step transition probability:
pij (, n+1) = p(fn+1 = j|fn = i) | (8) |
It has to say that the MCMME method is used for video sequence with multi-frames but not for only two frames.
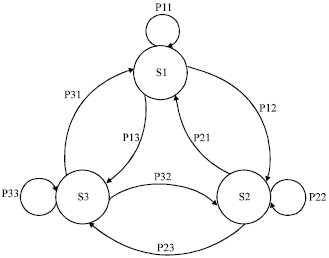 | |
| Fig. 2: | State-transition diagram of the built Markov chain model |
And for a video sequence, the transition probabilities can be assumed unchanged among a group of frames. Therefore, before MCMME method used, it must do three times of FS algorithm with the first four (1-2, 2-3 and 3-4) or six (1-2, 3-4 and 5-6) frames to calculate the transition probabilities. During the two times of FS algorithms, the corresponding predicting modes of each MB are recorded as ![]() , where, (r, c) denote the location of MB; k∈(1, 2) denote the index of FS algorithms. And during the second time of FS, the corresponding transition form of each MB is recorded as TF(r,c), where, TF(r,c)∈{T11, T12, T13, T21, T22, T23, T31, T32, T33} and Tij: i, j∈{1, 2, 3} is denote the transition form of MB is from mode i to mode j. Therefore, at the end of the second FS algorithm, the transition probability can be calculated by Eq. 9:
, where, (r, c) denote the location of MB; k∈(1, 2) denote the index of FS algorithms. And during the second time of FS, the corresponding transition form of each MB is recorded as TF(r,c), where, TF(r,c)∈{T11, T12, T13, T21, T22, T23, T31, T32, T33} and Tij: i, j∈{1, 2, 3} is denote the transition form of MB is from mode i to mode j. Therefore, at the end of the second FS algorithm, the transition probability can be calculated by Eq. 9:
| (9) |
where, NTij is the number of Tij; NMB is the toltal number of MBs in a frame.
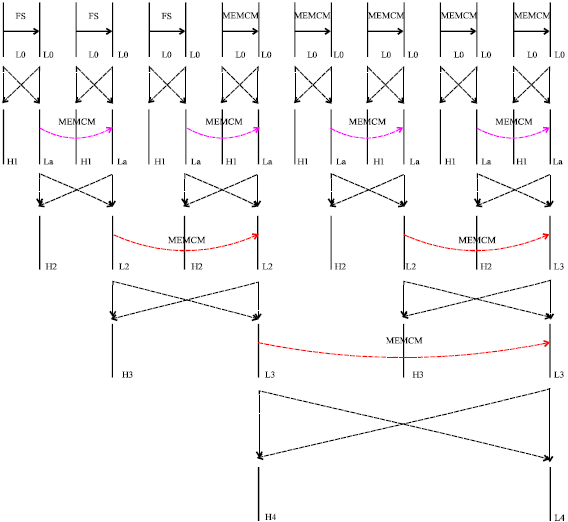
After getting the transition probabilities, MCMME algorithm can be used for the rest of motion estimation task. The main steps of MCMME algorithm are shown as below:
| Step 1: | Initialize the corresponding parameter used in the algorithm the same as PMVFAST. Let Found = 0 , PredEq = 0. According to the location of current MB, the PMV and the MV of REFMB can be obtained to prepare to test. If MVL = MVT = MVTR, let PredEq = 1 |
| Step 2: | Get the value of Distance by formula Distance = |PMVx|+|PMVy|. If PredEq = 1 and the predicted MV is equal to MV of REFMB, let Found = 2 |
| Step 3: | If Distance>0 or T2<1536 (which is used in PMVFAST) or PredEq = 1, choose the small diamond pattern to do the next search process |
| Step 4: | According to the relationship among the transition probabilities, compute the SADs of REFMV, (0,0) and PMV in order. If one of them satisfies the early elimination conditions, then stop search immediately and assign the current predicting mode, go to step 8. If none of them satisfy the conditions, go to step 5 |
| Step 5: | Compute SADs of the MVL, MVT and MVTR in turn, if one of them satisfies the early elimination conditions, stop search immediately and assign spatial mode to the current predicting mode, go to setp 8. Otherwise, get the minimum SAD as MinSAD go to step 6 |
| Step 6: | Get the minimum SAD of SAD of PMV, SAD of REFMV and the MinSAD as MSAD. If the corresponding MV is equal to REFMV and MSAD are less than the SAD of REFMV, stop search and go to step 8. Otherwise assign the current predicting mode and go to step 8 |
| Step 7: | Do search with line-small diamond or big diamond pattern. If Found = 2, do simplified (one step) diamond search, go to step 8 and assign the current predicting mode |
| Step 8: | Assign the point with the finial minimum SAD to the MV of current MB |
From the above description, it can be seen that the transition probabilities used are obtained by statistical method with lots of computational burden. Therefore, it is expected to develop some automatic and intellective way to predict these parameters.
SVM-MCMME MOTION ESTIMATION METHOD
SVM prediction networks: In order to avoid using the first two times of FS algorithms to obtain the state transition matrix, a learning method for Scalable Video Coding system (SVC) is developed in this study. For the excellent generalization ability of SVM, a multi-class SVM classifier is constructed. And then, this classifier is used for predicting the transition probabilities indirectly by classifying the feature vector of the test sequence. Therefore, this SVM classification networks is called SVM prediction networks in this study.
Binary tree structure based SVM classifier
Theory of two-class SVM: For binary problem, the basic idea of SVM classifier is to map the nonlinearly space to feature space in which the optimization hyper-plane is obtained by using nonlinear or linear transformation. And then, the SVM is found to do classification.
The optimal solution of the hyper-plane can be transformed into the following optimization problem:
| (10) |
where, ![]() is an positive semi-definite matrix in that the kernel function
is an positive semi-definite matrix in that the kernel function ![]() satisfies the Mercer conditions. This is a convex quadratic program that has exactly one optimal solution.
satisfies the Mercer conditions. This is a convex quadratic program that has exactly one optimal solution.
Theory of multi-class SVM: The traditional SVM can not solve the multi-class classification problem.
For multi-class classification problem, there are lots of methods that are put forward before and comparatively mature. The multi-class classification problem is often decomposed into several standard binary SVM classifiers. There are two types of decomposition: one-against-all and one-against-one.
One-against-all (Bottou et al., 1999): In this case, the multi-class classification functions are constructed between each class and the remaining classes. In this way, the class labels of the training data need to be modified. The label of the current class data is set to +1 and the others are set to -1. Therefore, N binary SVM can be obtained totally. Then, the input testing data is classified by these binary SVM respectively and get the corresponding discriminant functions. By comparing these discriminant functions, the class of the testing data will be the one whose discriminant function is maximal.
One-against-one (Kressel, 1999): In this case, the multi-class classification problem is decomposed into N child classifiers. Every two classes have one child binary SVM classifier. The input testing data is classified by all the child classifiers and calculate the appearing times of every class. The predicting result is chose the one which appear maximal times totally.
Binary tree structure based SVM classifier: If the multi-classification problem is N-class separable, N-1 binary SVM classifiers can be constructed to fulfill the classification task (Cheong et al., 2004).
The first binary SVM is trained by setting the 1st class as +1 class and the other classes as -1. The ith binary SVM is trained by setting the ith class as +1 class and (i+1) th to nth as -1.
Now let us review the Markov Chain Model has been built. There are three states S1, S2 and S3. The corresponding prediction modes are Mt, Mo and Ms (temporal, original and special modes), respectively. The states transition matrix of this Markov Chain Model is:
| (11) |
Now, these nine parameters in Eq. 11 can be seen as nine classes. Therefore, a 9-classes binary-tree SVM classification network can be constructed to evaluate the current MB s’ feature vector ![]() belonging to which class. This problem can be described as follow:
belonging to which class. This problem can be described as follow:
For the given training data:
| (12) |
where, n is the dimension of feature vector; l is the number of training data used; ![]() i is the corresponding feature vector of the ith data and y is the corresponding class label.
i is the corresponding feature vector of the ith data and y is the corresponding class label.
Constructing a binary-tree SVM classification network to achieve the follows mapping:
| (13) |
In order to reflect the essential character of the MB, the feature vector is chosen as:
| (14) |
where, μ represent the mathimatical expectation of the corresponding MB; σ represent the standard derviation of the corresponding MB; σ is the temperal correlation coefficient between the corresponding MB and its REFMB; ρt is the mean value of spatial correlation coefficients of the corresponding MB and its spatial neighbor MBs.
Therefore, a prediction networks is constructed as shown in Fig. 3a.
In Fig. 3a, C-ij, (i, j = 1, 2, 3) denote the case that current MB belongs to state transformation from mode i to mode j. For the consideration that a large number of predicting modes is temporal mode and that the number of the other two modes is much smaller, the first SVM (SVM1 in Fig. 3a is taking T1j described in section 2.2 as the +1 class and the other ones is the -1 class.
Let {pij, i∈{1, 2,..., 8}, j∈{1, 2}} be the probabilities of the positive class and negative class (where, j = 1 denote the positive class and j = 2 denote the negative one) of the child binary SVMs, respectively.
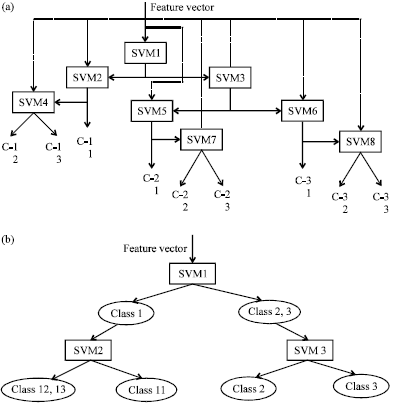 | |
| Fig. 3(a-b): | Constructed SVM prediction networks, (a) Prediction networks in theory and (b) Prediction networks in practice |
For any child binary SVM classifier, if using Ppos and Pneg denote the probability of +1 and -1 sample data and the correct classification rate is P, then:
Pposout = Ppos.P+Pneg.(1-P) | (15) |
Pnegout = Pneg.P+Ppos.(1-P) | (16) |
where, pposout, pnegout are the probabilities of +1 output and -1 output, respectively. Therefore, the nine output of the constructed 9-classes binary tree SVM classification networks are:
PC-11 = (P11.P1+P12.(1-P1)). (P21. P2+P22. (1-P2)) | (17) |
PC-12 = (P11.P1+P12.(1-P1)).(P22.P2+P21. | (18) |
PC-12 = (P11.P1+P12.(1-P1)). (P22.P2+P21.(1-P2))(P42.P4+P41.(1-P4)) | (19) |
PC-21 = (P12.P1+P11.(1-P1)). | (20) |
PC-22 = (P12.P1+P11.(1-P1)).(P31.P3+P32.(1-P3)). (P52.P5+P51.(1-P5)).(P71.P7+P72.(1-P7)) | (21) |
PC-23 = (P12.P1+P11.(1-P1)).(P31.P3+P32.(1-P3)). (P52.P5+P51.(1-P5)).(P72.P7+P71.(1-P7)) | (22) |
PC-31 = (P12.P1+P11.(1-P1)). (P31.P3+P32.(1-P3))(P61.P6+P62.(1-P6)) | (23) |
PC-32 = (P12.P1+P11.(1-P1)).(P31.P3+P32.(1-P3)). (P62.P6+P61.(1-P6)).(P81.P8+P82.(1-P8)) | (24) |
PC-33 = (P12.P1+P11.(1-P1)).(P31.P3+P32.(1-P3)). (P62.P6+P61.(1-P6)).(P82.P8+P81.(1-P8)) | (25) |
By testing various video sequences with different motion activity, it can be found that the ratio of S1 state is more than 50% in most case. This is said that there are lots of test data classified by SVM1 and SVM2. And only the relative information is needed for the MCMME algorithm, a decision was made that, SVM4, SVM5, SVM6, SVM7 and SVM8 can be neglected. Then, the simplified SVM network is as follows in Fig. 3b.
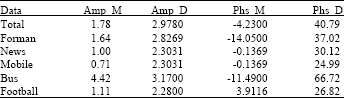
Training data selection: There are lots of test sequences with various motion activities. The selected training data must represent the real distribution of the feature parameters. Obviously, selecting training data from many different sequences randomly or in some other manner is an inefficiency and difficult task. For this consideration, a certain test sequence should be used to select training data. It assumes that the distribution of amplitude and phases of the MVs should be normal distribution. And then, the corresponding normal distribution fitting process is operated to MVs got from foreman.qcif, bus.qcif, news.qcif, mobile.qcif and football.cif test sequences respectively as well as the total mixed data. The corresponding data is described in Table 1, where Amp_M and Phs_M denote the average mean value of amplitudes and phases of MVs, Amp_D and Phs_D denote the average standard derivations of amplitudes and phases of MVs. The corresponding distribution histograms are shown in Fig. 4.
From the fitting results and the histogram figures, it can be seen that the distribution characteristic of foreman.qcif is almost as same as the total data. Therefore, the training data is selected from foreman.qcif.
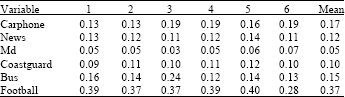
The training results of SVM1, SVM2 and SVM3 are shown in Table 2.
Table 3 and 4, where 1, 2, 3, 4, 5, 6 denote training with different training data. For there are little MBs belonging to state S2 and state S3 in test sequence such as news.qcif, in Table 4, there are only three lines of training results.
| Table 1: | Normal fitting results of amplitude and phase of MVs from differenct trainning data |
 | |
| Table 2: | Error rates of SVM1 classifier of six different learned SVM (No. of test points:1791) |
 | |
| Table 3: | Error rates of SVM2 classifier of six different learned SVM (No. of test points: 1791) |
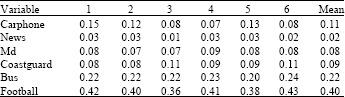 | |
| Table 4: | Error rates of SVM3 classifier of six different learned SVM (No. of test points:681) |
 | |
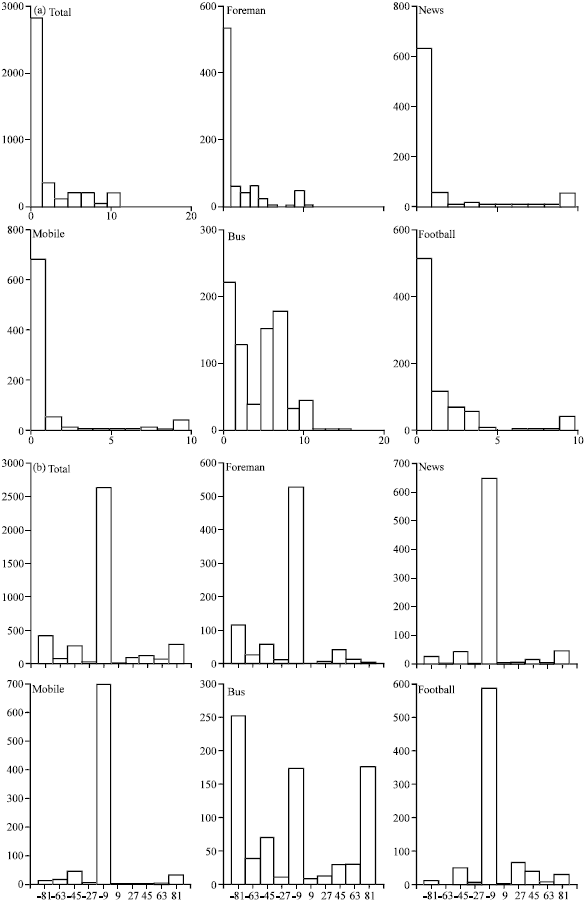 | |
| Fig. 4(a-b): | Histograms of MVs from six different trainning sequences, (a) Amplitude histograms and (b) Phase histograms |
By using the trained SVM networks, the transition matrix described above can be predicted efficiently while only the relative relation among these transition probabilities is needed. The following matrixes are the predicting results of bus.qcif and football.qcif test sequences which have much dramatic activity:
 |
Therefore, constructed SVM classification network can be used to predict the transition matrix indirectly and to guide the fast motion estimation procedure.
EXPERIMENT RESULTS
In order to evaluate the perforemance of the proposed method, the proposed SVM-MCMME method is embeded into a t+2D Scalable Video Coding system, respectively. The corresponding encoder structure is shown in Fig. 5.
The corresponding ME/MCTF structure with the original MCMME algorithm is illustrated in Fig. 6.
The corresponding ME/MCTF structure with the proposed method is just like the structure shown in Fig. 6, the only difference is the first three FS algorithm is changed to MCMME.
 | |
| Fig. 5: | Encoder structure of the used SVC |
 | |
| Fig. 6: | ME/MCTF structure with the original MCMME algorithm |
And the corresponding transition probabilities are evaluated by the SVM network constructed off-line.
| Table 5: | Comparison of the average ME/MCTF time per GOP and the corresponding PSNR |
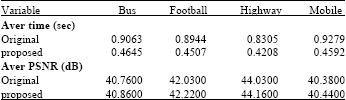 | |
For obtaining the evaluation data, the average time used for ME/MCTF procedure which account for about 70% of the total encoding time was got for one Group of Pictures (GOP). And highway.qcif, mobile.qcif, bus.qcif and football.qcif were selected as the test sequences with different motion activity. The corresponding data and average PSNR were illustrated in Table 5. The corresponding curves were shown in Fig. 7 and 8.
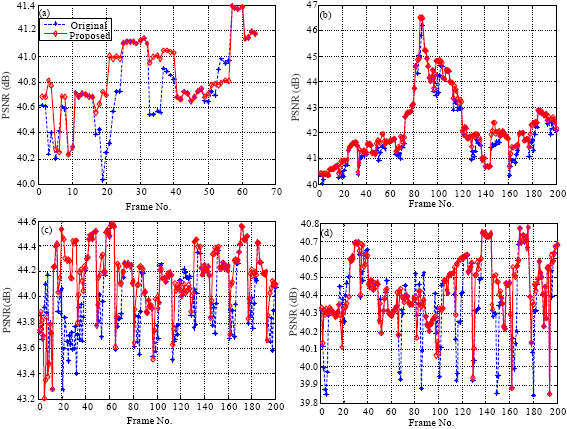 | |
| Fig. 7(a-d): | PSNR performance curves of four different test sequences with different motion activities, (a) Bus, (b) Football, (c) Highway and (d) Mobile |
 | ||
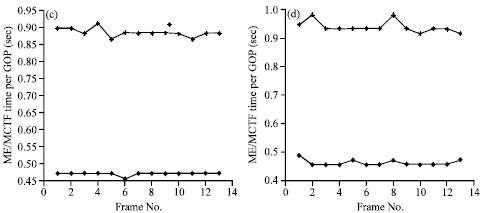 | ||
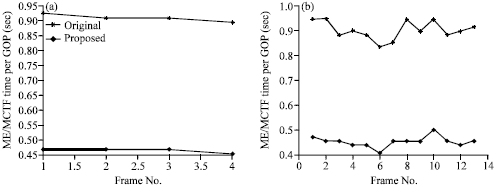
| Fig. 8(a-d): | Curves of time consumption per GOP of original SVC system and SVC system with SVM-MCMME used of different test sequences with different motion activities, (a) Bus, (b) Football, (c) Highway and (d) Mobile | |
CONCLUSION
In this study, the predictive motion estimation algorithm-MCMME proposed by us previous and its main drawback is analyzed first. For reducing the computational cost caused by statistical evaluation for using MCMME algorithm. An improved SVM-based method which is called SVM-MCMME is proposed. By using a multi-class SVM classification network, the corresponding transition probabilities of tested sequence is calculated indirectly. For evaluating the performance of the SVM-MCMME method, the performances of SVC system with ME/MCTF structure using the original MCMME algorithm and using the proposed method are tested. The corresponding ME/MCTF time per GOP and PSNR values are obtained. From the experimental results, it can be seen that there is about 100% improved in coding speed even with little PSNR increase.
ACKNOWLEDGMENT
This study is partially supported by the Natural Science Foundation of Heilongjiang Province (F201114, F201245) and by Harbin, a special study of technological innovation fund (2012RFQXG090). The authors also gratefully acknowledge the helpful comments and suggestions of the reviewers which have improved the presentation.
REFERENCES
- Li, R., B. Zeng and M.L. Liou, 1994. A new three-step search algorithm for block motion estimation. IEEE Trans. Circuits Syst. Video Technol., 4: 438-442.
CrossRefDirect Link - Po, L.M. and W.C. Ma, 1996. A novel four-step search algorithm for fast block motion estimation. IEEE Trans. Circuits Syst. Video Technol., 6: 313-317.
CrossRefDirect Link - Jain, J. and A. Jain, 1981. Displacement measurement and its application in interframe image coding. IEEE Trans. Commun., 29: 1799-1808.
CrossRefDirect Link - Zhu, C., X. Lin and L.P. Chau, 2002. Hexagon-based search pattern for fast block motion estimation. IEEE Trans. Circuits Syst. Video Technol., 12: 349-355.
CrossRef - Hosur, P.I. and K.K. Ma, 1998. Fast block motion estimation based on prediction of initial motion vectors of interleaved blocks using spatial correlation. Proceedings of the IEEE Asia Pacific Conference on Communications and International Conference on Communication Systems, November 23-27, 1998, Singapore, pp: 659-662.
- Hosur, P.I. and K.K. Ma, 1999. Motion vector field adaptive fast motion estimation. Proceedings of the 2nd International Conference on Information, Communications and Signal Processing, December 7-10, 1999, Singapore, pp: 1-4.
Direct Link - Tourapis, A.M., O.C. Au and M.L. Liou, 2001. Predictive Motion Vector Field Adaptive Search Technique (PMVFAST)-enhancing block based motion estimation. Proceedings of the SPIE Visual Communications and Image Processing, January 24-26, 2001, San Jose, CA., USA., pp: 883-892.
CrossRef - Chen, P.H., H.M. Chen, K.J. Hung, W.H. Fang, M.C. Shie and F. Lai, 2006. Markov model fuzzy-reasoning based algorithm for fast block motion estimation. J. Visual Commun. Image Representation, 17: 131-142.
CrossRef - Zhao, Z., Z. Cao, M. Lin and X. Jin, 2010. A motion estimation algorithm based on markov chain model. Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing, March 14-19, 2010, Dallas, TX., USA., pp: 1174-1177.
CrossRef - Cheung, C.H. and L.M. Po, 2002. A novel cross-diamond search algorithm for fast block motion estimation. IEEE Trans. Circuits Syst. Video Technol., 12: 1168-1177.
CrossRef - Bottou, L., C. Cortes, J.S. Denker and H. Drucker, 1999. Comparison of classifier methods: A case study in handwritten digit recognition. Proceedings of the 12th IAPR International Conference on Pattern Recognition, October 9-13, 1999, Jerusalem, Israel, pp: 77-87.
CrossRef