
Wang Li
College of Information Science and Engineering, Hunan University, Changsha, 410082, China
Gang Luo
College of Information Science and Engineering, Hunan University, Changsha, 410082, China
Lingyun Xiang
College of Computer and Communication Engineering, Changsha University of Science and Technology, Changsha, 410114, China
Information Technology Journal
Year: 2014 | Volume: 13 | Issue: 15 | Page No.: 2404-2410







ABSTRACT
In practical applications, in order to extract data from the stego, some data hiding encryption methods need to identify themselves. When performing data hiding, they embed some specific logo for self-identification. However, it is unavoidable to bring themselves the risk of exposure. Suppose each hidden method has a corresponding logo S and the attacker has a logo set Φ which consists of some hidden methods’ logos. Once he find the logo S which matches a logo in Φ, he can easily recognize the very method. To solve this problem, we propose a method based on synchronization to hide the specific sign or logo. First, the sender generates a key using a public variable parameter which is always changing from time to time. Then, we can calculate the hidden data’s location in the cover from the key. According to the locations, we can embed the logo into the cover. As the public parameter is changing from time to time, each transmission of hidden data has a unique location sequence. When the stego reaches its receiver, according to the public parameter, the receiver could generate the key and get the hidden data’s location to extract the secret data correctly. Experimental results verify that the data hiding method performs well and hardly has impacts on the cover’s quality and has little impacts on the robustness, imperceptibility and capacity of the original stego-cover. Besides, it is able to recover the key with linear time complexity when the critical information which is used to generate the key is missing.
PDF Abstract XML References Citation
Received: April 18, 2014;
Accepted: June 19, 2014;
Published: July 02, 2014
How to cite this article
Wang Li, Gang Luo and Lingyun Xiang, 2014. An Automatically Changing Feature Method based on Chaotic Encryption. Information Technology Journal, 13: 2404-2410.
DOI: 10.3923/itj.2014.2404.2410
URL: https://scialert.net/abstract/?doi=itj.2014.2404.2410
DOI: 10.3923/itj.2014.2404.2410
URL: https://scialert.net/abstract/?doi=itj.2014.2404.2410
INTRODUCTION
Data hiding techniques are mainly about researching on hiding data into cover. Avoiding being noticed by adversaries is their main purpose. Until now, it consists of Steganography, Digital Watermark, Visual Cryptography and etc. With data hiding techniques, secret communications become possible. Data hiding techniques are being applied to military, business, finance areas, such as conveying military intelligence, the privacy data of e-business, secret contracts between business partners and so on. Besides, data hiding techniques are utilized for identification, copyright protection, integrity authentication and so on.
Nowadays, main researches on data hiding techniques can be roughly divided into three areas: Spatial domain, transform domain and file format.
For spatial domain methods, LSB and LSB matching are the most commonly used algorithms. Researches on data hiding in spatial domain focus on capacity improvement, imperceptibility advancement and resistance against steganalysis (Zhang, 2011; Omoomi et al., 2011; Geetha et al., 2011; Zeki et al., 2011; Zanganeh and Ibrahim, 2011; Rajagopalan et al., 2014).
For transform domain methods, though data hiding methods are more complicated, they often achieve better robustness than spatial domain ones. The QIM and adaptive embedding algorithms (Wang et al., 2002; Podilchuk and Zeng, 1998) are typical of these methods. There are also some researches (Cancellaro et al., 2011; Lian et al., 2007; Khan et al., 2011; Bouslimi et al., 2012) on techniques about reversible watermarking of encrypted media. Some (Qiao and Nahrstedt, 1998; Shi and Bhargava, 1998; Wu and Kuo, 2005; Qiu and Wang, 2012) are on encryption techniques for the compressed image and some (Chen et al., 2003; Abdulfetah et al., 2010) focus on robustness and imperceptibility.
Style of file (such as XML, HTM, PDF, etc.) can be utilized in data hiding as well (Bo et al., 2009; Shahreza, 2006; Cantrell and Dampier, 2004; Liu and Tsai, 2007; Liu et al., 2008), according to the character of the file’s style. Such techniques are based on specific style of files which are different from each other.
In some cases, when extracting hiding information, we always needs a logo to mark the specific steganography algorithm. This brings great unsafety to the hiding system. For example, the software ffencode (Schroder, 2005) embeds a fixed sequence of “011001100110011001100011011011110110010001100101” into the carrier without any hiding processing. As long as an attacker calculates this specific sequence, he or she can confirm that the carrier he or she catches is encrypted by ffencode. Unfortunately, there are few researches on how to resolve such problems. Our purpose is to resolve this kind of problems. We put forward a method that can make the logo’s appearance different from time to time. Meanwhile, it makes sure that the receiver can extract the logo with 100% accuracy and recognizes the steganography tool correctly. And when the key is missing, it can recover the key with limited time cost in linear time complexity.
METHODOLOGY
Problem statements and analysis: To hide the specific logo, we need to encrypt it first. However, a proficient can get the logo with Chosen-plaintext attack when the logo is encrypted by the same key all the time. To avoid this, we need a key that can automatically change itself. A changing mechanism is what we need. Using an automatically changing key, the key of the sender’s must synchronize with the receiver’s. When sender’s key doesn’t match the receiver’s, we need a mechanism to restore the key’s synchronization. Considering all the requirements listed above, we take system time as the changing factor of the key. The system time has 4 key important natures: Linearity, uniqueness, finiteness in a finite interval and dynamics. The uniqueness and dynamics nature of time are necessary to the key’s automatically changing. And in case of being damaged or tampered, we need an efficient way to recover the key. The finiteness and linearity nature of the time can be used to recover the key. We also need a method to hide the encrypted logo. Comparing to hiding a logo in a fixed position, it is safer to hide the logo in random positions. The chaotic system performs well in producing pseudo-random sequences. Among chaotic mappings, the skew tent mapping has excellent pseudo-randomness and it obeys uniform distribution. With the skew tent mapping, we calculate the embedding locations so that it has the ability to resist statistical analysis.
Merits of the method:
| • | Choosing different keys from time to time |
| • | Being able to figure out the missing or damaged key in linear time complexity |
| • | Resistance to statistics analysis |
Description of the method: First, P stands for plaintext, VI denotes the initial vector of 128 bits. T is the time that generated by the computer system and its precision is second. In this study, we choose the format of time as “YYYYMMDDHHMISS”. Specifically, we encrypt the time T with MD5 algorithm (128 bits) and get a sequence of hex numbers: Tmd5 = MD5(T), Tmd5 = tmd5_0tmd5_1…tmd5_15. S is the logo that need to be encrypted and its length is l bytes (each character is 1 byte and 1 byte = 8 bits). VI and S are divided into the following groups:
![]()
![]()
(Each vii or si is 8 bits).
According to Tmd5 and VI, the system generates the secret key K in the following way:
![]()
![]()
The logo S is encrypted to M in the following way:
![]()
![]()
The M is what we need to hide into the carrier. Its length is the same with S, the length of M is also l bytes.
And T(j) is the jth created time and the corresponding secret key is K(j) (j is an integer). T is different from time to time and the K(j) is created by T(j) nd VI. When i ≠ j, K(i) ≠ K(j).
Logistic map is often used to design random encryption system. Logistic mapping not only has low computing complexity but also has good pseudo-random performance. However, the skew tent mapping’s distribution is more uniform than logistic mapping’s (Xiang et al., 2008) and it has stronger pseudo-randomness as well (Masuda and Aihara, 2001). Therefore, the chaotic sequence generated by the skew tent mapping is better for cryptographic purpose:
| • | Logistic mapping: |
| (1) |
| • | Skew tent mapping: |
| (2) |
We set r (r is 8 bits) as follows:
![]()
To get the hidden data’s location by skew tent map, x0, p, N is initiated as follow:
![]()
![]()
![]()
We embed the encrypted logo M into a cover grayscale I, M is l bytes and the length of the cover I is L bytes. Suppose there is a logo set Φ = {S0, S1, S2ÿSn-1} and the ldiv = max{length(Si)}+ε, ε+N and ε is agreed on by both the sender and receiver. The cover I is divided into 8ldiv (ldiv>l) blocks. There are g(g = ⌊L/8ldiv⌋) pixels in each block and the block set is denoted as Block = {B0, B1, B2ÿB8ldiv-1} The ith bit of M(bm_i) is embedded into the block Bi. To embed the bit bm_i into the block Bi, we set di = ⌊gxxi⌋ as the embedding location of Bi and embed bm_i into the dith pixel of Bi (0≤i≤8ldiv-1). Then we convert pixel’s value from decimal to binary, in the form of b7b6b5b4b3b2b1b0 (0~255). To hide the bit bm_i, if b0 = bm_i, we do nothing to b0, otherwise we replace b0 with bm_i.
Figure 1 shows the embedding process and the embedding algorithm is as follows:
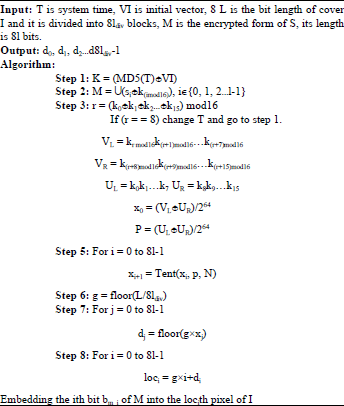
The sender embed M into I and the original I becomes stego-carrier Im. The receiver already has VI and receives T from the sender. During the extraction phase, he generates K with the T and VI. The receiver gets the sub-location sequence d0d1d2ÿd8ldiv-1 to extract the message MM which contains M. With the K, he decrypts MM and gets the message SS which contains logo S.
Figure 2 shows the extracting process and the extracting algorithm is as follows:
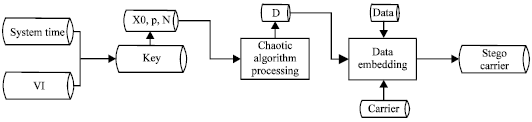 | |
| Fig. 1: | Embedding process |
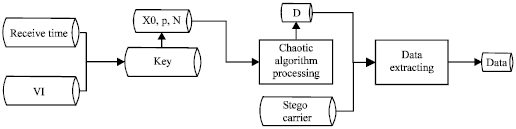 | |
| Fig. 2: | Extracting process |
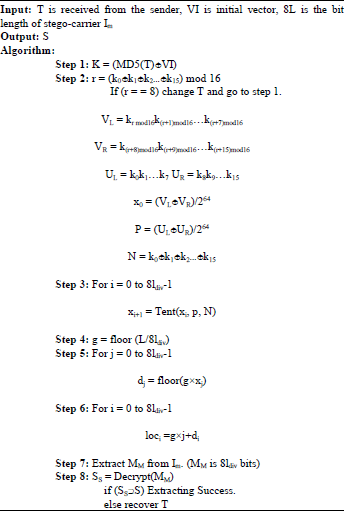
To extract the hidden logo S, the extracting algorithm needs to extract 8ldiv bits from Im and get the message MM which is ldiv bytes. It decrypts MM to the form of SS = S∪Se, Se = slsl+1ÿsldiv-1. We compare SS with each logo in the set Φ. If we find that there is a logo SiεΦ and Si = S, then we get the correct logo.
Analysis of the algorithm: Both the sender and receiver need to have the same logo set Φ. The algorithm embeds an uncertain logo that is from the logo set Φ into the cover I. Because the receiver doesn’t know which logo the sender selects, to define a fixed length ldiv is necessary. In this study, ldiv meets the following requirements: ldiv≥max{l/l = length(Si), Si∈Φ} Adding a new logo to the set Φ needs to reset ldiv. There is a difference between embedding and extracting: The T is generated by the system at the sender side while the receiver receives T instead of generating it. And the using of skew tent mapping makes sure that the logo bits are uniformly hidden in the cover. With a dynamic T, the hidden locations are different from time to time.
In addition, when Tc (system time) is damaged or tampered by some attacker, we still have a chance to obtain it. Suppose we lost Tc and we have Tlast which is got from the last transmission. And we received the M at the real time Treal. (Tcε(Tlast, Treal) T here is a integer). We can try each T from either Tlast to Treal, or Treal to Tlast. It is certain that we can deduct the correct T which is equal to Tc. And if the searching direction is from Tlast to Treal, we need to set the time cost to Δtlast. And if the time interval is from Treal to Tlast, we need to set the time cost as Δtreal. In addition, we denote the time cost to locate Tc as Δt and Δt≤max{Δtlast, Δtreal}. And the searching of Tc is in a linear way, so the time complexity to find Tc is O(Δt).
Experiments: Let Tc = 20140303122212, VI = 7154A05BCC 3E552D5E5E21BA716A31EF and the images size be 512x512, 512x256 and 256x256. Each image size consists of 456 images. The images we use for experiments are all from http://sipi.usc.edu/database/. Let secret logo be m. Set m = “Hunan University is a good university”. We choose LSB embedding method for the experiments, because it is easy to operate and causes little distortion to the original images.
Figure 3 shows the impacts on 1000 locations when Tc is changing from Tc = 20140303122212 to Ts = 201403031 22213. y is the degree of location’s difference between Tc and Ts. dc_i is the ith location generated by the Tc, ds_i is the ith location generated by Ts. yi is the degree of difference between dc_i and ds_i. yi = |dc_i-ds_i|/8l, 8l is the bit length of S, iε{0, 1, 2…8l-1}. The average degree of difference from 8l locations is:
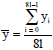
In this experiment, we calculate the = 33.99%.
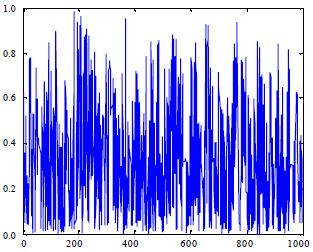 | |
| Fig. 3: | Key sensitivity to initial value |
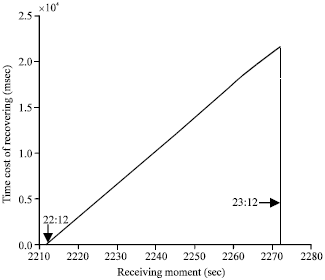 | |
| Fig. 4: | Cost time for T’s recovery |
| Table 1: | Average of MSE and PNSR |
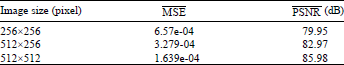 | |
Here, we count the changed locations and unchanged ones. When the ith location is changed, then zi = 1, otherwise, zi = 1. Then we calculate the changing rate of the locations when time changes from T to Ts. We set rc as the global changing rate:
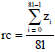
Testing 456 images, we find the average rc is ![]()
Figure 4 shows the time cost from different starting position when Tc = 22:12 is the correct solution. And from the figure, we can see that the time cost to find the exact T = Tc is linear. Δt = |Tx-Ti|, the value of the Δt is determined by Tx. And the longer the logo is, the steeper the line is. It proved that the searching for the missing key cost is O(Δr).
Generally, a logo is short, embedding it hardly causes distorsion to the cover. There are 3 kinds of image size, each size consists of 456 images. According to Table 1, we could easily find that, the ![]() of each size is very close to 0 and the
of each size is very close to 0 and the ![]() has a high value that is more than 80. It verifies the fact that embedding the logo has little impacts on original algorithm’s robutness, capacity and invisibility. And we could also conclude from the Table 1 that, the larger the image size is, the less impacts caused by the embedding.
has a high value that is more than 80. It verifies the fact that embedding the logo has little impacts on original algorithm’s robutness, capacity and invisibility. And we could also conclude from the Table 1 that, the larger the image size is, the less impacts caused by the embedding.
DISCUSSION
In this study, we analyzed the feasibility of the algorithm. In the process of embedding, we encrypt logo with a dynamic key. Then embed the encrypted logo into cover in a random way. In this way, the attacker has little chance to find the logo. When in extracting process, we need to extract an encrypted message that contains the encrypted logo. We decrypt the encrypted message and get the message which contains logo. In this way, we can use a set of data hiding algorithms which is based on logo, instead of only one. By conducting experiments on testing how sensitive the key to the chaotic mapping’s parameter, we find that the hiding location sequence’s (d1d2d3…) changing rate is close to 100% when T changes 1 bit. When the time Tc for generating key is damaged, the algorithm can recover the damaged Tc in a linear computation complexity with limited cost. By embedding logos into more than 1300 images of different sizes, measuring by both the MSE and PSNR shows that the algorithm has little impact on the robutness, capacity and invisibility of original one. However, though the proposed algoritm can resolve the risk but there is still an efficient problem. The system time T for K’s generation is not hidden during the message’s transmission, it could be tampered easily. Though there is a way for T’s recovery, it degrades the efficiency of the algorithm to some extent.
CONCLUSION
The data hiding software which relies on some fixed logo to identify themselves can perform data hiding and data extracting efficiently. However, the fixed logo may bring great risk to the data hiding algorithm, because it can be easily caught by an attacker especially when the attacker has knowledge of the algorithm. To solve this problem, this study propose a method to enable the logo to change itself automatically by adding time variable. In theory, each change of the logo is different from each other. And the method hides the logo bit by bit with a random sequence which is generated by the skew tent mapping. The random sequence is used to calculate the bit’s hiding location. In this way, the attacker can hardly extract the logo even though he has the knowledge of the data hiding algorithm. Furthermore, when the time is damaged, there is a remedy for the receiver to generate the key in limit time cost. Though the proposed method resolves the problems brought by the fixed logo, there is still room for improvements. The future study will focuse on improving the robustness of the algorithm. Besides, we need to find an efficient way to protect the system time which is exposed during the transmission.
ACKNOWLEDGMENTS
This study was supported by National Natural Science Foundation of China (No. 61202439, 61103215) and the Fundamental Research Funds for the Central Universities of China.
REFERENCES
- Zhang, X., 2011. Reversible data hiding in encrypted image. IEEE Signal Process. Lett., 18: 255-258.
CrossRefDirect Link - Omoomi, M., S. Samavi and S. Dumitrescu, 2011. An efficient high payload ±1 data embedding scheme. Multimedia Tools Appl., 54: 201-218.
CrossRefDirect Link - Geetha, S., V. Kabilan, S.P. Chockalingam and N. Kamaraj, 2011. Varying radix numeral system based adaptive image steganography. Inform. Process. Lett., 111: 792-797.
CrossRefDirect Link - Zeki, A.M., A.A. Manaf and S.S. Mahmod, 2011. High watermarking capacity based on spatial domain technique. Inform. Technol. J., 10: 1367-1373.
CrossRef - Zanganeh, O. and S. Ibrahim, 2011. Adaptive image steganography based on optimal embedding and robust against chi-square attack. Inform. Technol. J., 10: 1285-1294.
CrossRefDirect Link - Rajagopalan, S., H.N. Upadhyay, S. Varadarajan, J.B.B. Rayappan and R. Amirtharajan, 2014. Gyratory assisted info hide-a nibble differencing for message embedding. Inform. Technol. J., 13: 2005-2010.
CrossRefDirect Link - Wang, S., X. Zhang and T. Ma, 2002. Image watermarking using dither modulation in dual-transform domain. J. Imaging Soc. Jpn., 41: 398-402.
Direct Link - Podilchuk, C.I. and W. Zeng, 1998. Image-adaptive watermarking using visual models. IEEE J. Sel. Areas Commun., 16: 525-539.
CrossRefDirect Link - Cancellaro, M., F. Battisti, M. Carli, G. Boato, F.G.B. De Natale and A. Neri, 2011. A commutative digital image watermarking and encryption method in the tree structured Haar transform domain. Signal Process.: Image Commun., 26: 1-12.
CrossRefDirect Link - Lian, S., Z. Liu, Z. Ren and H. Wang, 2007. Commutative encryption and watermarking in video compression. IEEE Trans. Circ. Syst. Video Technol., 17: 774-778.
CrossRefDirect Link - Khan, M.I., V. Jeoti, A.S. Malik and M.F. Khan, 2011. A joint watermarking and encryption scheme for DCT based codecs. Proceedings of the 17th Asia-Pacific Conference on Communications, October 2-5, 2011, Sabah, Malaysia, pp: 816-820.
CrossRef - Bouslimi, D., G. Coatrieux and C. Roux, 2012. A joint encryption/watermarking algorithm for verifying the reliability of medical images: Application to echographic images. Comput. Methods Programs Biomed., 106: 47-54.
CrossRefDirect Link - Qiao, L. and K. Nahrstedt, 1998. Comparison of MPEG encryption algorithms. Comput. Graphics, 22: 437-448.
CrossRefDirect Link - Shi, C. and B. Bhargava, 1998. A fast MPEG video encryption algorithm. Proceedings of the 6th ACM International Conference on Multimedia, September 13-16, 1998, Bristol, UK., pp: 81-88.
CrossRef - Wu, C.P. and C.C.J. Kuo, 2005. Design of integrated multimedia compression and encryption systems. IEEE Trans. Multimedia, 7: 828-839.
CrossRef - Qiu, J. and P. Wang, 2012. Encryption algorithm for compressed image based on chaotic maps. Comput. Sci., 6: 44-46.
Direct Link - Chen, T.H., G. Horng and S.H. Wang, 2003. A robust wavelet-based watermarking scheme using quantization and human visual system model. Inform. Technol. J., 2: 213-230.
CrossRefDirect Link - Abdulfetah, A.A., X. Sun, H. Yang and N. Mohammad, 2010. Robust adaptive image watermarking using visual models in DWT and DCT domain. Inform. Technol. J., 9: 460-466.
CrossRefDirect Link - Bo, L., L. Wei, C. Yuan-Yuan, J. Dong-Dong and C. Ying-Zhi, 2009. HTML integrity authentication based on fragile digital watermarking. Proceedings of the IEEE International Conference on Granular Computing, August 17-19, 2009, Nanchang, China, pp: 322-325.
CrossRef - Cantrell, G. and D.D. Dampier, 2004. Experiments in hiding data inside the file structure of common office documents: A steganography application. Proceedings of the International Symposium on Information and Communication Technologies, June 16-18, 2004, Las Vegas, Nevada, USA., pp: 146-151.
Direct Link - Liu, T.Y. and W.H. Tsai, 2007. A new steganographic method for data hiding in microsoft word documents by a change tracking technique. Trans. Inform. Forensics Secur., 2: 24-30.
CrossRefDirect Link - Liu, Y., X. Sun, Y. Liu and C.T. Li, 2008. MIMIC-PPT: Mimicking-based steganography for microsoft power point document. Inform. Technol. J., 7: 654-660.
CrossRefDirect Link - Xiang, T., K. Wong and X. Liao, 2008. An improved chaotic cryptosystem with external key. Commun. Nonlinear Sci. Numer. Simul., 13: 1879-1887.
CrossRefDirect Link - Masuda, N. and K. Aihara, 2001. Cryptosystems based on space-discretization of chaotic maps. Proceedings of the IEEE International Symposium on Circuits and Systems, Volume 3, May 6-9, 2001, Sydney, Australia, pp: 321-324.
CrossRef