
Mohammad Syafrullah
Faculty of Computing, Universiti Teknologi Malaysia, Skudai, Johor, 81310, Malaysia
Naomie Salim
Faculty of Computing, Universiti Teknologi Malaysia, Skudai, Johor, 81310, Malaysia
Information Technology Journal
Year: 2014 | Volume: 13 | Issue: 9 | Page No.: 1631-1639







ABSTRACT
Term extraction is one of the layers in the ontology development process, which has the task to extract all the terms contained in the input document automatically. The objective of this process is to generate a list of terms that are relevant to the domain of the input document. In this study, we present a hybrid method for improving the precision term extraction using a combination of Continuous Particle Swarm Optimization (PSO) and Discrete Binary PSO (BPSO) to optimize fuzzy systems. In this method, PSO and BPSO are used to optimize the membership functions and rule sets of fuzzy systems, respectively. The method was applied to the domain of tourism documents and compared with other term extraction methods: TFIDF, Weirdness, GlossaryExtraction and TermExtractor. From the experiment conducted, the combination of PSO-BPSO showed their capability to generate an optimal set of parameters for the fuzzy membership functions and rule sets automatic adjustment. Findings also showed that fuzzy system performance after optimization achieved significant improvements compared with that before optimization and gave better results compared to those four algorithms.
PDF Abstract XML References Citation
Received: December 02, 2013;
Accepted: February 17, 2014;
Published: March 21, 2014
How to cite this article
Mohammad Syafrullah and Naomie Salim, 2014. Term Extraction Using Hybrid Fuzzy Particle Swarm Optimization. Information Technology Journal, 13: 1631-1639.
DOI: 10.3923/itj.2014.1631.1639
URL: https://scialert.net/abstract/?doi=itj.2014.1631.1639
DOI: 10.3923/itj.2014.1631.1639
URL: https://scialert.net/abstract/?doi=itj.2014.1631.1639
INTRODUCTION
Term extraction is a prerequisite for all aspects of ontology learning. A term is an instance of a recognisable entity in a multimedia corpus that conveys a single meaning within a domain (concept). A recognizable entity is something that can be recognized in corpora, such as words or phrases in textual corpora, or areas in images. Since terms “lexicalize” a concept, terms found in a corpus usually represent candidate concepts that can enrich an ontology. Thus, the main objective of term extraction is the identification of terms in a corpus that possibly convey concepts, which can be used for enriching an ontology.
Many methods have been presented in the literature, mainly for the processing of textual corpora. Most of these are based on linguistic method, terminology and NLP method, while others are based on a statistical/information retrieval method (Cimiano, 2006). Many linguistic methods use shallow text processing techniques such as tokenizer, Part-Of-Speech (POS) tagger and syntactic analyzer (parser). Text-to-Onto, for example, use a linguistic method called Saarbrucken Message Extraction System (SMES) in their system architecture to produce a list of terms from the input text (Maedche and Staab, 2000). Another system, SVETLAN, uses the syntactic analyzer, Sylex to find list of terms from the input text (De Chalendar and Grau, 2000).
Statistical methods usually try to determine the significance of each word with respect to other words in a corpus based on word occurrence frequencies. Various works have been applied in statistical methods for term extraction. Most of them are based on an information retrieval method for term indexing (Salton and Buckley, 1998; Yates and Neto, 1999; Witten et al., 1999; Medelyan and Witten, 2005). Other methods use the notion of “weirdness”(Ahmad et al., 1999), statistical measurement of frequency occurrence of multi-word terms (Frantzi et al., 2000), mutual information and Log Likelihood Ratio (Panel and Lin, 2001), domain specificity (Park et al., 2002; Kozakov et al., 2004), latent semantic indexing (Fortuna et al., 2005) and domain pertinence (Navigli and Velardi, 2004; Sclano and Velardi, 2007).
Clustering techniques also play an important role in term extraction: recognizable entities can be clustered into groups based on various similarity measures with each cluster being a possible term (comprising synonyms). (Kietz et al., 2000; Agirre et al., 2000; Faatz and Steinmetz, 2002) employed clustering techniques and other resources such as www and WordNet to successfully extract terms. Additionally, both frequency and clustering based approaches can be substantially enhanced through the use of natural language processing techniques (such as morphological analysis, part-of-speech tagging and syntactic analysis), as terms are usually noun phrases or often obey specific part-of-speech patterns (Haase and Stojanovic, 2005). Finally, morphological clues (such as prefixes and suffixes) can be extremely useful for some domains: suffixes such as “-fil” and “-it is” quite often mark terms in medical domains (Haase and Volker, 2008).
Esmin and Lambert-Torres (2006, 2007, 2010) and Lambert-Torres et al. (2000) have shown an efficient PSO based approach to construct and optimize a fuzzy rules base and fuzzy membership function. This method assumes that the fuzzy logics can also be formulated as a space problem, where each point of fuzzy sets corresponds to a fuzzy logic i.e. represents membership functions and rule base. Another work by Kiani and Akbarzadeh (2006) proposed a technique for combining a Genetic Algorithm (GA) and Genetic Programming (GP) to optimize rule sets and membership function of fuzzy systems.
As term extraction is an important task not only for concept discovery for ontology learning, but also for textual information extraction and retrieval, this study proposes a term extraction method using a hybrid method of Continuous Particle Swarm Optimization (PSO) and Discrete Binary PSO (BPSO). This method was used to optimize and automatically adjust the membership functions and rule sets of fuzzy systems, respectively.
MATERIALS AND METHODS
This section presents a new approach to extract terms based on an optimized fuzzy inference system, which takes into account several kinds of features including domain relevance, domain consensus, term cohesion, first occurrence and length of noun phrase.
Initially, syntactic parser performs a syntactic analysis on every input sentence from the input document and extracts a list of syntactic information (Noun Phrase-NP). All stop words were removed from each of the lists of NP. Finally, the list of NP was stemmed to produce a list of clean NP, as the term candidate. Each term candidate is associated with a vector that contains five features.
The features extracted in the previous step were used as inputs to the fuzzy inference system. In this approach, we want to maximize the accuracy of the fuzzy system output while optimizing its running time, by optimizing the membership function and the rule sets. Therefore, a hybrid of PSO and BPSO was used to find the optimal rule-based system.
Fuzzy system: Fuzzy systems are used in a wide number of applications areas, especially on fuzzy control problems. These systems can be considered as knowledge-based systems, incorporating human knowledge into their knowledge base through a fuzzy inference system and fuzzy membership functions. The definition of these fuzzy inference systems and fuzzy membership functions is generally affected by subjective decisions, having a great influence over the performance of the system.
Fuzzy inference is the process of formulating the mapping from a given input to an output using fuzzy logic. The mapping then provides a basis from which decisions can be made, or patterns discerned. The fuzzy inference process comprises five parts: Fuzzification of the input variables, application of the fuzzy operator (AND or OR) in the antecedent, implication from the antecedent to the consequent, aggregation of the consequents across the rule sets and defuzzification.
Fuzzy rules are linguistic IF-THEN constructions that have the general form "IF A THEN B", where A and B are collections of propositions containing linguistic variables. A is called the premise and B is the consequence of the rule. The fuzzy rules are written as:
| • | IF x is A THEN y is B, where x and y are linguistic variables; and A and B are linguistic values determined by fuzzy sets on the universe of discourses X and Y, respectively (Fig. 1) |
Continuous PSO: The particle swarm optimization (PSO) algorithm (Eberhart and Kennedy, 1995; Kennedy and Eberhart, 1995) has been introduced as an optimization technique for use in real-number spaces. It is originally designed for continuous optimization problems.
PSO is inspired by this kind of social optimization, where a problem is given and some way to evaluate a proposed solution exists in the form of a fitness function. A communication structure or social network is also defined, assigning neighbours for each individual to interact with. Then, a population of individuals, defined as random guesses at the problem solutions is initialized. These individuals are candidate solutions. They are also known as particles, hence the name particle swarm. In PSO, each particle in a population has a position and a velocity vector. Derived from utilization of other particles, individual best’s and global best’s positions which will be clarified later, a velocity vector is generated. That particle then modifies its own position due to the velocity vector for which the achievement of coordination and communication with the experience of other individuals is not ignored.
A PSO includes three basic steps: Evaluation of the fitness values of each particle, updating the values and positions of individual and global best and updating the velocities and positions of each individual in the population according to the Eq. 1 and 2:
| (1) |
| (2) |
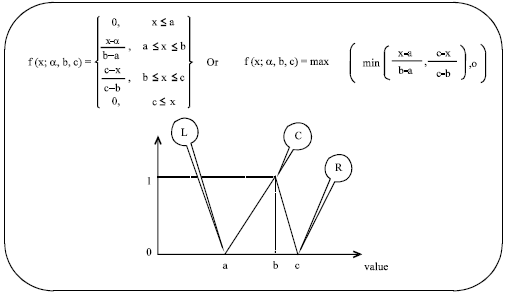 | |
| Fig. 1: | Triangular membership functions |
 | |
| Fig. 2: | PSO algorithms |
where, ![]() is the current position of the i-th particle in the swarm,
is the current position of the i-th particle in the swarm, ![]() is the velocity of the i-th particle,
is the velocity of the i-th particle, ![]() is the best position found by the i-th particle so far (local best). The best position found from the particle’s neighbourhood (global best) is then stored in a vector
is the best position found by the i-th particle so far (local best). The best position found from the particle’s neighbourhood (global best) is then stored in a vector ![]() and
and ![]() are the numbers uniformly chosen from [0, 1]. c1 is a positive constant called the coefficient of the self-recognition component and c2 is a positive constant called the coefficient of the social component. The variable w is called the inertia factor, whose value is typically set up to vary linearly from 1 to 0 during the search process (Fig. 2).
are the numbers uniformly chosen from [0, 1]. c1 is a positive constant called the coefficient of the self-recognition component and c2 is a positive constant called the coefficient of the social component. The variable w is called the inertia factor, whose value is typically set up to vary linearly from 1 to 0 during the search process (Fig. 2).
Discrete binary PSO: Continuous PSO is mainly applied in the area of continuous/real number space and rarely in discrete space. However, many optimization problems are set in a space featuring discrete binary or qualitative distinctions between variables, for example routing problem, scheduling/timetabling problem and data mining. To meet the need, Kennedy and Eberhart (1997) proposed a discrete binary version of PSO for binary problems (Eberhart and Shi, 1998). In their model, a particle will decide on "yes" or Ano", "true" or "false" etc. This binary value can also be a representation of a real value in binary search space.
Discrete PSO essentially differs from the original (or continuous) PSO in two characteristics. First, the particle is composed of the binary variable. Second, the velocity must be transformed into the change of probability, which is the chance of the binary variable taking the value one. In the binary PSO, the particle’s personal best and global best is updated as in continuous version. The major difference between binary PSO and continuous version is that velocities of the particles will change to one of the two decisions [0 or 1]. A sigmoid transformation as in (Eq. 3) is applied to make the velocities value into a range of [0 or 1] and force the component values of the particle’s position to be 0 or 1. The equation for updating the particle’s position is shown in Eq. 4:
| (3) |
| (4) |
Feature definition: All term candidates and their features were extracted from text. These entire term candidates were selected from noun phrases. First of all noun phrases were extracted with the syntactic parser and all stop words were removed from candidates. Five features (f1, f2, f3, f4, f5) were chosen to characterize the noun phrases in the documents. The features used are domain relevance, domain consensus, term cohesion, first occurrence and length of noun phrase.
Domain relevance (f1): Domain relevance can be given according to the amount of information captured in the target document with respect to contrastive documents. Let Dk as the domain of interest (a set of relevant documents) and {D1... Dn} as sets of documents in another domain, domain relevance of a term t in class Dk be computed as (Navigli and Velardi, 2004; Sclano and Velardi, 2007) Eq. 5 and 6:
| (5) |
| (6) |
where, ft,k is the frequency of term t in the domain Dk.
Domain consensus (f2): Domain consensus measures the distributed use of a term in domain Dk. Domain consensus is expressed in Eq. 7 and 8 as follows (Navigli and Velardi, 2004; Sclano and Velardi, 2007):
| (7) |
| (8) |
Term cohesion (f3): Term cohesion is used to calculate the cohesion of the multi-word terms. The measure is proportional to the co-occurrence frequency and the length of the term (Eq. 9) (Park et al., 2002; Kozakov et al., 2004):
| (9) |
where, wj are the words composing the term t.
First occurrence (f4): First occurrence of a term is calculated as the distance of a phrase from the beginning of a document in words, normalized by the total number of words in the document. The result represents the proportion of the document preceding the phrase=s first appearance (Eq. 10) (Witten et al., 1999; Medelyan and Witten, 2005):
| (10) |
Length of noun phrase (f5): Length of noun phrase score is calculated as frequency times (Eq. 11) length (in words) (Barker and Corrnacchia, 2000):
| (11) |
Fuzzy PSO model: Several assumptions are used for the model formulation:
| • | Triangular membership functions were used for both input and output variables |
| • | Complete rule-base was considered. A rule-base is considered complete when all possible combinations of input membership functions of all the input variables participate in fuzzy rule-base formation |
The features extracted in the previous section are used as inputs to the fuzzy inference system. We use triangular membership functions which are specified by three parameters (a, b, c) as in Fig. 1. Parameters a and c locate the "feet" of the triangle and parameter b locates the peak of the triangle.
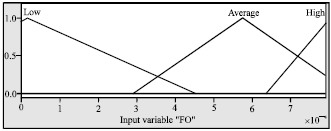
The input membership function for each feature is divided into three fuzzy sets which are {low, average, high}. For instance, membership functions of the first occurrence are shown in Fig. 3.
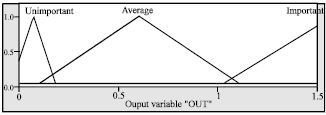
The output membership functions are shown in Fig. 4, which is divided into 3 fuzzy sets: {unimportant, average, important}.
The most important part in this procedure is the definition of fuzzy IF THEN rules. We define full rule sets (243 rules). For example, our rules are demonstrated as follows (Fig. 5):
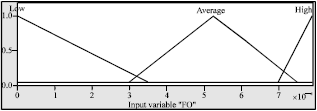 | |
| Fig. 3: | Membership function of first occurrence |
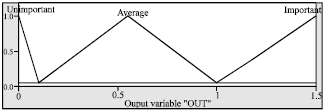 | |
| Fig. 4: | Membership function of output |
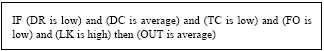 | |
| Fig. 5: | Samples of IF-THEN rules |
| Table 1: | Parameter setting of particle swarm based optimization |
 | |
Optimization by PSO: The objective of this optimization process is to find the optimal adjustment values of membership function. For each fuzzy membership function, there are three parameters as shown in Fig. 1: L (left), C (centre), R (right).
The integration of PSO algorithms with a fuzzy system was made as follows:
| • | The parameters are the adjustment factor centres (k) and widths (w) of each fuzzy set. Parameter k makes each membership function move to the right or left with no change in the form. The membership function shrinks or expands through parameter w |
| • | These parameters act as particles and look for the global best fitness |
| • | The initial set of particle swarm optimization variables is shown in Table 1 |
| • | After the parameters had been adjusted using optimization method, this parameter was used to evaluate the performance of the fuzzy system using fitness function as in Eq. 13 |
| • | For the adjustment of membership functions, the following equations were defined (Eq. 12): |
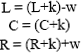 | (12) |
| • | The process is repeated until the termination criterion is met (Fig. 6): |
| (13) |
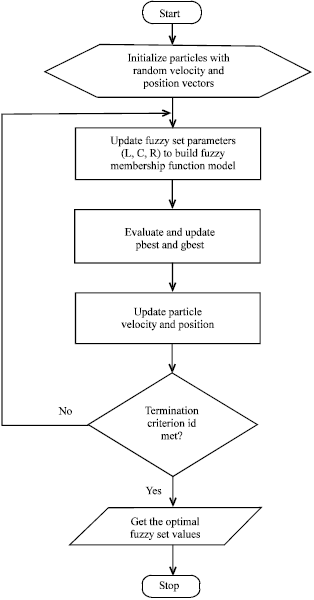 | |
| Fig. 6: | Flowchart of fuzzy membership function adjustment using PSO |
Optimization by BPSO: In this research, we used BPSO to optimize the IF-THEN rules of the fuzzy system. The integration of BPSO algorithms with the fuzzy system was made as follows:
| • | The parameters are the rule number of rule sets, which will determine whether the rule is "select" or Anot select" in the rule sets |
| • | These parameters act as particles and look for the global best fitness |
| • | The initial set of particle swarm optimization variables is shown in Table 1 |
| • | After the parameters had been adjusted using the optimization method, the fitness of rules was obtained by bonding the rules with membership functions. The fitness was evaluated using Eq. (14) |
| • | The process is repeated until the termination criterion is met: |
| (14) |
Datasets
Tourism: The data used for testing and evaluating the proposed method was document collection about tourism [http://olc.ijs.si/lpTxt/] and has already been used by Cimiano (2006). The collection with approximately a million tokens size consists of 1800 text documents, describing countries, cities, places, regions, sights etc. from all continents. In this experiment, we used 300 documents as datasets.
Reuters-21578: The documents in the Reuters-21578 collection appeared on the Reuters newswire in 1987. We converted all the documents into 22 plain text files (reut2-000.txt until reut2-021.txt); the size of the text corpus is about 218 Mio tokens. Reuters-21578 was used in the experiment as contrastive documents.
RESULTS AND DISCUSSION
After execution of the optimization process, we can see that PSO has successfully adjusted fuzzy membership function and fuzzy rule sets. The fuzzy set for every membership function has been adjusted from standard fuzzy membership function and the number of rule sets is reduced from 243 rules to 190 rules (Fig. 7 and 8).
In this extraction stage, we evaluate the precision of our proposed method at seven points: top 25, 125, 225, 325, 425, 525 and 625 terms, both for each feature and the scores of the term candidates using the following (Eq. 15):
| (15) |
We compared the terms extracted by the system with the gold standard. Table 2 shows the term extraction precision for each feature for different numbers of terms evaluated.
In order to see the improvement in our proposed method, it was compared with a fuzzy system without using optimization. From the experimental results, it can be seen that our proposed method, combination of PSO and fuzzy system, can increase the precision of the extracted term compared to a fuzzy system without using optimization.
Despite the improvement in accuracy results that were achieved using the Fuzzy PSO model, it was necessary to compare the prediction accuracy results to other algorithms. This study compared the precision of our proposed method with other known algorithms as shown in Fig. 9. It was observed that the precision of the Fuzzy PSO model is much higher than the accuracy of any other algorithms. Table 3 and Fig. 9 show the comparison of the precision between the fuzzy swarm model, fuzzy model and the four other algorithms (TFIDF, Weirdness, GlossaryExtraction and TermExtractor).
 | |
| Fig. 7: | First occurrence membership function after applying PSO |
 | |
| Fig. 8: | Output membership function after applying PSO |
| Table 2: | Term extraction precision for each feature |
 | |
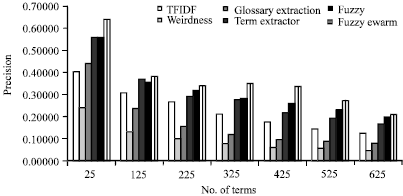 | |
| Fig. 9: | Comparison of term extraction precision (Fuzzy swarm model, fuzzy, TFIDF, weirdness, glossary extraction and term extractor) |
| Table 3: | Comparison of term extraction precision using different methods |
 | |
Finally, the experimented results conclude that Fuzzy PSO leads to improving the precision results while adjusting fuzzy membership function and keeping the number of fuzzy rules to a minimum with a high degree of accuracy.
CONCLUSION
In this study, a new approach is proposed to extract terms based on an optimizing fuzzy inference system. The continuous PSO is used to optimize the membership functions and Discrete Binary PSO is used to optimize the fuzzy rule sets. Based on the results of the experiment, the PSO has successfully adjusted fuzzy membership function and fuzzy rule sets and improved the performance result in terms of precision. Finally, the proposed method is compared with four other known algorithms (TFIDF, Weirdness, GlossaryExtraction and TermExtractor). Our experimental results show that the use of particle swarm optimization to optimize fuzzy membership function and fuzzy rule sets can significantly improve the precision of the extracted term.
ACKNOWLEDGMENT
This study is funding by Research Management Centre, Universiti Teknologi Malaysia.
REFERENCES
- Ahmad, K., L. Gillam and L. Tostevin, 1999. University of surrey participation in TREC 8: Weirdness Indexing for Logical Document Extrapolation and Retrieval (WILDER). Proceeding of the 8th Text REtrieval Conference, November 17-19, 1999, Department of Commerce, National Institute of Standards and Technology, USA., pp: 717-724.
Direct Link - Barker, K. and N. Corrnacchia, 2000. Using noun phrase heads to extract document Keyphrases. Proceedings of the 13th Biennial Conference of the Canadian Society for Computational Studies of Intelligence, May 14-17, 2000, Canada, pp: 40-52.
CrossRef - De Chalendar, G. and B. Grau, 2000. SVETLAN' or how to classify words using their context. Proceedings of the 12th International Conference on Knowledge Engineering and Knowledge Management Methods, Models and Tools, October 2-6, 2000, Juan-les-Pins, France, pp: 203-216.
CrossRef - Eberhart, R.C. and J. Kennedy, 1995. A new optimizer using particle swarm theory. Proceedings of the 6th International Symposium on Micro Machine and Human Science, October 4-6, 1995, Nagoya, Japan, pp: 39-43.
CrossRefDirect Link - Kennedy, J. and R. Eberhart, 1995. Particle swarm optimization. Proceedings of the International Conference on Neural Networks, Volume 4, November 27-December 1, 1995, Perth, WA., USA., pp: 1942-1948.
CrossRef - Eberhart, R.C. and Y. Shi, 1998. Comparison between genetic algorithms and particle swarm optimization. Proceedings of the 7th International Conference on Evolutionary Programming VII, March 25-27, 1998, Germany, pp: 611-616.
Direct Link - Esmin, A.A.A. and G. Lambert-Torres, 2006. Fitting fuzzy membership functions using hybrid particle swarm optimization. Proceedings of the IEEE International Conference on Fuzzy Systems, July 16-21, 2006, Vancouver, Canada, pp: 2112-2119.
CrossRef - Esmin, A.A.A. and G. Lambert-Torres, 2007. Evolutionary computation based fuzzy membership functions optimization. Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, October 7-10, 2007, Montreal, Canada, pp: 823-828.
CrossRef - Esmin, A.A.A. and G. Lambert-Torres, 2010. Generate and optimize fuzzy rules using the Particle Swarm Algorithm. Proceedings of the IEEE International Conference on Systems Man and Cybernetics, October 10-13, 2010, Istanbul, Turkey, pp: 4244-4250.
CrossRef - Frantzi, K., S. Ananiadou and H. Mima, 2000. Automatic recognition of multi-word terms: The C-value/NC-value method. Int. J. Digit. Lib., 3: 115-130.
CrossRefDirect Link - Haase, P. and L. Stojanovic, 2005. Consistent evolution of OWL ontologies. Proceedings of the 2nd European Semantic Web Conference, May 29-June 1, 2005, Heraklion, Greece, pp: 182-197.
CrossRef - Kennedy, J. and R.C. Eberhart, 1997. A discrete binary version of the particle swarm algorithm. Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Computational Cybernetics and Simulation, Volume 5, October 12-15, 1997, Orlando, FL., USA., pp: 4104-4108.
Direct Link - Kiani, A. and M.R. Akbarzadeh, 2006. Automatic text summarization using hybrid fuzzy GA-GP. Proceedings of the IEEE International Conference on Fuzzy Systems, July 16-21, 2006, Vancouver, BC., Canada, pp: 977-983.
CrossRef - Kozakov, L., Y. Park, T. Fin, Y. Drissi, Y. Doganata and T. Cofino, 2004. Glossary extraction and utilization in the information search and delivery system for IBM technical support. IBM Syst. J., 43: 546-563.
Direct Link - Lambert-Torres, G., M.A. Carvalho, L.E.B. da Silva and J.O.P. Pinto, 2000. Fitting fuzzy membership functions using genetic algorithms. Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Volume 1, October 8-11, 2000, Nashville, USA., pp: 387-392.
CrossRef - Maedche, A. and S. Staab, 2000. Mining ontologies from text. Proceedings of the 12th International Conference on Knowledge Acquisition, Modeling and Management, October 2-6, 2000, Juan-les-Pins, France, pp: 189-202.
CrossRef - Medelyan, O. and I.H. Witten, 2005. Thesaurus-based index term extraction for agricultural documents. Proceedings of the Joint Conference on European Federation for Information Technology in Agriculture and World Congress on Computers in Agriculture, July 25-28, 2005, Vila Real, Portugal, pp: 1122-1129.
Direct Link - Navigli, R. and P. Velardi, 2004. Learning domain ontologies from document warehouses and dedicated web sites. Comput. Linguist., 30: 151-170.
CrossRef - Panel, P. and D. Lin, 2001. A statistical corpus-based term extractor. Proceedings of the 14th Biennial Conference of the Canadian Society for Computational Studies of Intelligence, June 7-9, 2001, Ottawa, Canada, pp: 36-46.
CrossRef - Park, Y., R.J. Byrd and B.K. Boguraev, 2002. Automatic glossary extraction: Beyond terminology identification. Proceedings of the 19th International Conference on Computational Linguistics, August 26-30, 2002, Taipei, Taiwan, pp: 772-778.
Direct Link - Salton, G. and C. Buckley, 1988. Term-weighting approaches in automatic text retrieval. Inform. Process. Manage., 24: 513-523.
CrossRefDirect Link - Sclano, F. and P. Velardi, 2007. Termextractor: A web application to learn the shared terminology of emergent web communities. Proceedings of the 3rd International Conference on Interoperability for Enterprise Software and Applications, March 28-30, 2007, Portugal, pp: 287-298.
CrossRef - Witten, I.H., G.W. Paynter, E. Frank, C. Gutwin and C.G. Nevill-Manning, 1999. KEA: Practical automatic keyphrase extraction. Proceedings of the 4th ACM Conference on Digital Libraries, August 11-14, 1999, California, USA., pp: 254-256.
CrossRef - Fortuna, B., M. Grobelnik and D. Mladenic, 2005. Visualization of text document corpus. Informatica, 29: 497-502.
Direct Link