
Ang Wei
School of Natural Sciences, Nanjing University of Posts and Telecommunications, Nanjing 210046, China
F.U. Chunyao
Key Laboratory for Organic Electronics and Information Displays and Institute of Advanced Materials, Nanjing University of Posts and Telecommunications, Nanjing 210046, China
Wei Wei
XI`an University of Technology, School of Computer Science and Engineering, XI`an 710048, China
Information Technology Journal
Year: 2012 | Volume: 11 | Issue: 6 | Page No.: 730-733







ABSTRACT
In this study, a new method to acquire the decision rule of information system with continuous attributes was proposed. The modeling theory and the estimation method of partially linear auto-regression model are discussed and the lag variables, best model, the optimal bandwidth are determined. Partially linear auto-regression models of Shanghai stock index and Shenzhen component index based on partial residual estimate are established and the validity of the model are examined. Finally, forecasting with the model and judged the effect of the model based on the real data.
PDF Abstract XML References Citation
Received: January 18, 2012;
Accepted: February 06, 2012;
Published: February 28, 2012
How to cite this article
Ang Wei, F.U. Chunyao and Wei Wei, 2012. A New Method on Partially Linear Autoregression Forecasting. Information Technology Journal, 11: 730-733.
DOI: 10.3923/itj.2012.730.733
URL: https://scialert.net/abstract/?doi=itj.2012.730.733
DOI: 10.3923/itj.2012.730.733
URL: https://scialert.net/abstract/?doi=itj.2012.730.733
INTRODUTION
Partially linear auto-regression model with parametric variable and nonparametric variable has more adaptability and explanatory ability than the parametric model and the nonparametric model. The wavelet is a perfect tool to deal with instability signals. This thesis has established models of Shanghai stock index and Shenzhen component index based on wavelet and time series models.
Traditional methods discretize the attributes before apply linear auto-regression model to the information system. Fayyad and Irani (1993) use a recursive entropy minimization heuristic for attribute discretization. In (Wang, 2001), naïve and semi naïve scaler methods are proposed to find the appropriate cut point of the continuous attribute. In this study, we construct the indiscernibility set of x by defining the toleration relation on the information systems. Using the indiscernibility set of x, we partitioned U and acquired the decision rule. This decision rule is influence by the system permitted error. The relation between the system permitted error and the effectiveness of the acquired decision rule is discussed through a numerical experiment. And we compared our methods with the traditional ones under the optimum system permitted error. It shows that our method is better than the traditional ones in many cases.
INFORMATION SYSTEM WITH CONT-INUOUS CONDITION ATTRIBUTES
First, let us have a look on the definition of decision information system.
Definition 1: A decision information system including, where:
| • | U is a non-empty finite set of objects |
| • | A is a non-empty finite set of attributes |
| • | D is a non-empty finite set of decisions |
| • | F is the relation set between U and A |
| • | fj: U→vj (j≤q), Vj is the domain of aj |
| • | G is the relation set between U and D |
| • | gj: U→V’j (j≤q), V’j is the domain of dj |
In order to solve the problem of continuous condition attributes discretization, we define the relationship ![]() and
and ![]() in the following way.
in the following way.
Definition 2: A decision information systems Xt = (Xt1,..., Xtp)T we define the toleration relation as the following:
Here δ≥0 is called a system permitted error.
Under this relation, the indiscernibility set of x is Wψf (a,b).
Hence, ∀X⊆U, we can get its approximation under the relation:
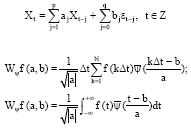 |
Let:
then RD is equivalent relation in X, its equivalent class is denoted as:
DECISION RULE ACQUISITION
According to Zhang et al. (2001, 2003a, b), Let:
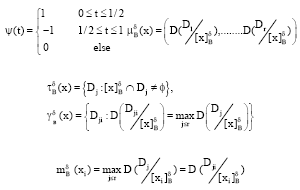 |
Definition 1:
let:
Theorem 1: Suppose that (U,A,F,D,G) is an information system with continuous condition attributes, then all the non-empty: 0≤α≤1 (hj (t) = E (Xj|T = t)) form a partition of U.
Proof: (1) first, to prove that with different Yt = βTXt+ g (Zt)+εt, Xti (I = 1,...,p) ∩ Xt = (Xt1,..., Xtp)T = φ (i≠j), reduction to absurdity is used, supposed that Yt = βYt-1+ g (Yt-2+εt (t≥3), then Ψ (t) εL2 (R) lead to ![]() :
:
so:
we can get the result as Di = Dj, which is obviously a confliction.
So:
(2) Then, let us prove that to all:
According to the definition of ![]() , we know that
, we know that ![]() and then
and then ![]() , Whereas, ∀ xεU, suppose that:
, Whereas, ∀ xεU, suppose that:
and then:
therefore:
From (1) and (2) we can draw a conclusion that:
According to theorem 1, we can partition U as U = {C1, C2, C3,..., Ct}, in which:
And hence gain the decision rule:
Now, we call:
the reliability of ![]() ,
, ![]() is called the precision of
is called the precision of ![]() . Then we obtain the rule with precision:
. Then we obtain the rule with precision:
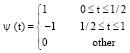 |
To be more practical, we normally transform the rule to attribute expression. We denote:
where:
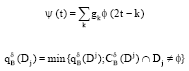 |
This formula of rule can be expressed as:
To illustrate this decision rule acquisition process clearly, let us see some examples.
Example 1:
 |
Let δ = 0.3.
We can accomplish the decision rule acquisition:
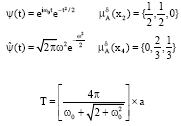 |
Hence, we have:
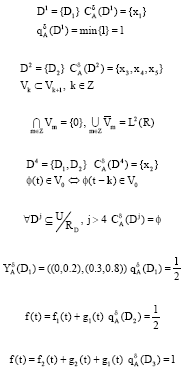 |
NUMBERICAL EXPERIMENT
We apply the method of rule acquisition to the famous Iris data.
We conduct the experiment in the following way:
| Step 1: | Given δ = 0 |
| Step 2: | Randomly chose these samples from the whole data set as training samples 15, 30, 45, 60, 75, 90, 105, 120, 135, 150 |
| Step 3: | Then acquire the rules by applying our methods on the training samples |
| Step 4: | We gain the rules of f (t) = fm (t)+gm-1 (t)+...+g1 (t) |
| Step 5: | Judge the whole data set by the rules we acquired and compare our judgments with the original decision of the data sets. We can gain the percentage of the data that are being judged correctly |
| Step 6: | Repeat step (2-4) for 500 times. Then, compute the average percentage of correctness |
| Step 7: | δ = δ+2.0 if δ<51 go to step 2 or else end |
We convert the result into chart. With the value of δ as abscissa and the average percentage of correctness as y-axis, we plot ten curves according to different capability of training data.
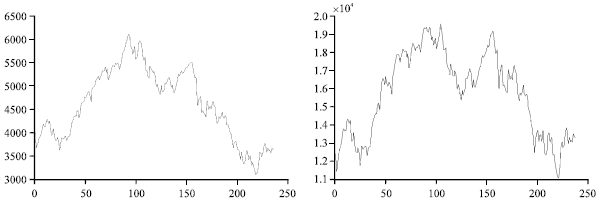 | |
| Fig. 1: | The initial data of (a) stock index and (b) component indexz |
| Table 1: | Comparison of all the methods |
 | |
From Fig. 1, we can see that as the capability of the training data becomes larger, the optimum δ slides away from the point δ = 0. When the capability of the training data exceed 75, most the optimum δ stays at the point δ = 8.0.
After the optimum system permitted error was gained, we compare our methods to the traditional ones. 90 samples from the whole data set were chosen randomly and the decision rules under the optimum system permitted error acquire were acquired. Then, we apply the acquired decision rule to the whole data set and gain the correctness of the rule. The comparison between our methods with traditional methods of discretizing the data is showed as follows.
Comparison: Rules derived from 90 samples applying to the whole data set.
In fact, our methods greatly improved the percentage of correctness in many cases. The Table 1 is only an example.
CONCLUSION
The main work of this study can be summarized as: First, a method of decision rule acquisition on decision information system with continuous condition attributes is given. This method avoids the step of data discretization and hence decreases the information which is lost in pretreatment. Second, the relation between system permitted error and the effectiveness of the decision acquisition is discussed through a numerical experiment. We also demonstrate that our method gets better results than traditional discretizing methods by comparison.
ACKNOWLEDGMENTS
This work is supported by the financial support from the Natural Science Research Project of Jiangsu Ordinary University (09KJB430008), the Opening Project of State Key Laboratory of High Performance Ceramics and Superfine Microstructure (SKL201111SIC) and Education Reform Project of NJUPT (JG00711JX39).
REFERENCES
- Fayyad, U. and K. Irani, 1993. Multi-interval discretization of continuous-valued attributes for classification learning. Int. Joint Conf. Artificial Intel., 13: 1022-1029.
Direct Link