
Long-Hua Ma
School of Aeronautics and Astronautics, Zhejiang University, Hangzhou, 310027, China
Yu Zhang
School of Aeronautics and Astronautics, Zhejiang University, Hangzhou, 310027, China
Chun-Ning Yang
School of Aeronautics and Astronautics, Zhejiang University, Hangzhou, 310027, China
Hui Li
School of Aeronautics and Astronautics, Zhejiang University, Hangzhou, 310027, China
Information Technology Journal
Year: 2012 | Volume: 11 | Issue: 11 | Page No.: 1655-1659







ABSTRACT
For signal processing and process control, the minimax problem is a crucial point in research subjects. But efficient solutions to equality and inequality constrained nonlinear general minimax problems are relatively scarce. A minimax neural network model was proposed to solve the general minimax problem based on penalty function. In this model, the unique requirement is that the objective function and constraint functions should be first-order differentiable. In addition to the global stability analysis based on the Lyapunov function, the proposed model was simulated and its validity was evaluated with numerical results. Experimental results demonstrated that the proposed minimax neural network model can solve the problem in seconds which is more efficient than the conventional genetic algorithm and simplex genetic algorithms.
PDF Abstract XML References Citation
Received: May 23, 2012;
Accepted: June 22, 2012;
Published: August 28, 2012
How to cite this article
Long-Hua Ma, Yu Zhang, Chun-Ning Yang and Hui Li, 2012. A Neural Network Model for Equality and Inequality Constrained Minimax Problems. Information Technology Journal, 11: 1655-1659.
DOI: 10.3923/itj.2012.1655.1659
URL: https://scialert.net/abstract/?doi=itj.2012.1655.1659
DOI: 10.3923/itj.2012.1655.1659
URL: https://scialert.net/abstract/?doi=itj.2012.1655.1659
INTRODUCTION
The Minimax Problem (MMP) is a kind of optimization problem to find the solution x with the minimum worst cost f, where some related parameter y is chosen by an adversary. At the same time, the design may have to satisfy a set of constraints. A general MMP with constraints can be formulated as follows:
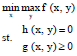 | (1) |
where, x = (x1, x2, …, xn)TεRn, y = (y1, y2, …, yr)TεRr, f: RnxRr→R, h: RnxRr→Rme and g: RnxRr→Rm-me. Minimax problems have been found in many fields such as scheduling (Herrmann, 1999), network design (Kalyanasundaram et al., 1999), filter design (Chao et al., 2000), controller design (Zheng et al., 2001), function approximation (Demyanov and Malozemov, 1974) and so on. The main difficulty is that how to make the cost function decrease with x while increase with y simultaneously. It is not an easy task to simply minimizing the cost function with x while fixing y and then maximizing the cost function with y while fixing x, since the cost function value may oscillate between peaks and valleys.
Several authors have investigated the minimax problem and introduced some heuristic solutions to this problem. Herrmann adopted the Genetic Algorithm (GA) over a set of possible scenarios (Herrmann, 1999; Liu, 1998) utilized GA to solve the minimax problem with both continuous variables. Longhua et al. (2001) proposed a Simplex-GA (SGA) based scheme through studying the convergence speed and solution accuracy of the GA approach (Longhua et al., 2001; Ye et al., 1997) presented a neural network model for unconstrained minimax optimization and proved its stability for some convex cases. Tao and Fang (2000) proposed a quadratic neural network model for quadratic minimax problems under some positive/negative matrix assumptions.
In virtue of penalty functions, this letter develops a kind of minimax neural network for the general minimax optimization problem with both equality-based and inequality-based constraints. The only requirement is that the objective function and constraint functions should be first-order differentiable. When the alternative searching point is forced into the feasible region by penalty terms, our neural network tries to solve the unconstrained minimax problem approximately similar to Ye et al. (1997) neural network. Thus, the neural network model of Ye et al. (1997) is used as a special case of ours safely. Although there are several types of penalty functions, for the sake of the global stability of neural network, the penalty function with an archetypical form is chosen which guarantees a large enough penalty parameter.
PROPOSED NEURAL NETWORKS MODEL AND STABILITY ANALYSIS
Equality constrained problem: Let us consider the following Equality-constrained Minimax Programming (EMMP) problem first:
| (2) |
where, x = (x1, x2, …, xn)TεRn, y = (y1, y2, …, yr)TεRr and f: RnxRr→R and c: RnxRr→Rm are given functions that are assumed to be first-order differentiable. Before detailed theoretic analysis, some definitions and evident propositions are given.
| Definition 1: | Ω: RnxRr is the feasible region of EMMP, if (x, y)εΩ⇔c(x, y) = 0. |
| Definition 2: | Ω’: RnxRr is the ε-feasible region of EMMP, if (x, y)εΩ’⇔||c (x, y)||≤ε, where ε>0 is a small enough positive real number. |
| Definition 3: | (x*, y*) is the solution of EMMP, if ∀(x, y)εΩ, there is f(x*, y)≤f(x*, y*)≤f(x, y*), that is (x*, y*) is a saddle point in Ω. |
| Proposition 1: | If (x*, y*) is a saddle point in Ω, then: |
| (3) |
where:
Present goal is to design a neural network that can settle down to an equilibrium point satisfying (3), whereas, what should primarily be considered are the constraints. In general, a penalty approach is employed. And consider the following equivalent expression of Eq. 2:
| (4) |
where, σ>0. Thus, if L1 can be minimized with x, it is equivalent to minimizing f with x, unless constraints are not satisfied which makes L1 going away from minima. Similarly, minimizing L2 with y is equivalent to minimizing -f, that is, maximizing f, unless constraints are not satisfied. Wah et al. (2000) have showed that the convergence speed and/or the solution accuracy could be affected by an additional weight in the objective function (Wah et al., 2000). Thus, take into account an additional balance factor ω in the objective function as follows:
| (5) |
where, σ>0 and ω is a tunable weight, e.g., we can adopt:
| (6) |
where, ε>0 is a small positive real number, e.g., ε = σ-0.75. Take above instantiated ω and ε values as default values for later simulation if there is no additional annotation. Thus, the transient behaviors of the proposed neural network can be defined as follows:
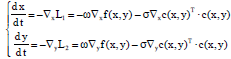 | (7) |
Theorem 1: When ||c(x, y)||≤ε, ε = σ-0.75, Eq. 5 nearly degenerates to an unconstrained minimax problem ![]() and there exists:
and there exists:
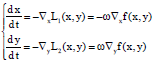 | (8) |
This theorem obviously exists, since if ε = σ-0.75 and ||c(x, y)||≤ε, then 0.5σ||c(x, y)||2≤0.5σ-0.5, thus 0.5σ||c(x, y)||2 is neglectable in Eq. 5 when σ is large enough. Note that ω = 10 when ||c(x, y)||≤ε, merely because the gradient and accelerate the convergence speed are supposed to augment. If the network is physically stable, the equilibrium point denoted by (x*, y*) that satisfies Eq. 3 and c(x*, y*) = 0 obviously also satisfies Eq. 7.
Theorem 2: Let the energy function of the neural network be E1(x, y) = L1(x, y), E2(x, y) = L2(x, y). If ||c(x, y)||>ε and σ is sufficiently large, the energy functions decrease with x and y, respectively.
This theorem can be proved by checking if ![]() and
and ![]() or not. Since:
or not. Since:
| (9) |
On the one hand, we have:
| (10) |
On the other hand, we have:
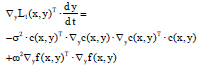 | (11) |
Note that when σ is sufficiently large, the second term is much smaller than the first term (especially when ω is small) and thus it can be neglectable. Thereby we have:
| (12) |
Therefore, we can obtain that:
Similarly we can also get:
That is to say, the system energy is decreasing. Note that the condition that σ is sufficiently large is easily satisfied, for that as a penalty parameter, σ starts from a large positive number and is always increasing. And when ||c(x, y)||>ε, ω = 0.1, that means the term with ω2 is tuned to be much smaller.
Theorem 3: Let f be the energy function when ||c(x, y)||≤ε, it decreases with x if y is fixed and increases with y if x is fixed.
Proof: It has been proved that when ||c(x, y)||≤ε, Eq. 5 nearly degenerates to an unconstrained minimax problem ![]() . Based on Eq. 8, we have:
. Based on Eq. 8, we have:
| (13) |
| (14) |
That means the system energy decreases with x when y is fixed and increases with y when x is fixed, if the neural network state is restricted in the ε-feasible region.
When utilizing neural networks for optimization, people are usually much more interested in the global stability of the network. It is highly desirable that the network is globally stable in the sense that it will never display oscillation or chaos, starting from an arbitrary point. Thus an optimal solution can always be obtained by setting the initial state of the network with an arbitrary value. One of the most effective approaches for stability analysis is Lyapunov's method. So we construct a Lyapunov energy function for our neural network as follows.
Definition 4: The Lyapunov energy function is defined by:
| (15) |
Theorem 4: When ||c(x, y)||>ε and σ is sufficiently large, the proposed neural network model is nearly Lyapunov stable.
This theorem can be proved by checking if ![]() or not. Based on Eq. 15, we have:
or not. Based on Eq. 15, we have:
| (16) |
Here, P1(x, y)=∇xL1(x, y)T.∇xL1(x, y)+∇yL2(x, y)T.∇yL2 (x, y) and P2(x, y) = ∇yL1(x, y)T.∇yL2(x, y)+∇xL2(x, y)T.∇xL1 (x, y).
Obviously, P1(x, y)≥0. Furthermore, when ||c(x, y)||>ε and σ is sufficiently large, we have:
∇yL1(x, y)T.∇yL2(x, y) = σ2||∇yc(x, y)T.c(x, y)
||2-ω2||∇yc(x, y)||2≥0
So does ∇xL2(x, y)T.∇xL1(x, y)≥0. Thus, P1(x, y)≥0. Therefore, it follows ![]() .
.
Theorem 4 concerns the stability of network when ||c(x, y)||>ε. In the case that ||c(x, y)||≤ε, Ye et al. (1997) have argued the global stability of unconstrained minimax neural networks (Ye et al., 1997) and the conclusion are simply list here.
Proposition 2: Assume that f: RnxRr→R is a convex-concave function (that is, convex to x and concave to y), the neural network defined by Eq. 8 is global stable and the asymptotical equilibrium point is unique (Tao and Fang, 2000).
So far we have presented the neural network model and completed its stability proof. However, we would like to point out that, the watershed ε which divides the space into the ε-feasible region and the remainder region is merely a supposed parameter. It does not exist at all. We make it out just for the convenience of proof, making a smooth conjuncture between the previous work and ours.
Inequality constrained problem: If inequality constraints are counted in, the EMMP in Eq. 2 is extended to MMP in Eq. 1. Yuan (1993) have summarized some techniques to convert inequality constraints into equality constraints, including the following one (Yuan, 1993).
| (17) |
where, c: RnxRr→Rm, h: RnxRr→Rme and g: RnxRr→Rm-me. By such disposition, all constrained conditions can be transferred into equality constraints.
SPECTRAL RADIUS ANALYSIS AND COMPARISON
The multilevel programming example given (Liu, 1998) can be modified as a good minimax programming example where n = 2 which can be described as follows:
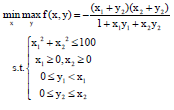 | (18) |
The solution given by GA (Liu, 1998) is x* = (7.0854, 7.0291), y* = (7.0854, 0.0000), with f = -1.9760. We have studied the transient behavior of the network from various initial states by simulating the dynamic equations via the classical fourth-order Runge-Kutta method (Atkinson et al., 1994; Li et al., 2010) on a Pentium III 500 Hz digital computer. We found that the total computation time varies with different start points. As a representation we choose x = (80, 80) and y = (80, 80) as our initial points that have a mean performance. The results are listed in Table 1 in comparison with the GA (Liu, 1998) (number of chromosomes 30, number of generations 300) and the Simplex-genetic Algorithm (SGA) (number of chromosomes 8, number of generations 100) (Longhua et al., 2001; Jia-Liang et al., 2010).
Performance of the proposed minimax neural network outperforms the evolution-based algorithms in shortening the computation time, because it is a gradient guided algorithm while GA and SGA are "blind search" algorithms to some degree. But the solution accuracy of minimax neural network is a bit inferior to that of the other two algorithms. Three reasons for this phenomenon may be: Firstly, there is truncated error in Runge-Kutta method which is ineluctable; Secondly, to avoid becoming infinite, it is obliged to cease increasing at 106 which brings a lot of error; Thirdly, the gradient around the saddle point is very small and our algorithm stops somewhere near the equilibrium. The geometric shape of f when x = (7.0711, 7.0711) with y = (y1, y2) between 0 and 8 is shown in Fig. 1 and the surface is so flat that our algorithm could not proceed any more within the error limit which confirms our supposal.
The speed advantage of neural circuits over evolution strategies is more salient in large dimension optimization. GA has to spread initial seeds in the whole search space uniformly, so with the increase of variable dimension, the number of seeds increases exponentially. For example, if the 2-D plane are divided in grid with 9 equal parts per dimension and make every cross point be an initial chromosome, consequently we have about (9+1)2 initial seeds. If the space is not a 2-D plane but a 3-D cube, the number is 103. Thus when the variable dimension increases to N, the number of initial chromosomes needed is about 10N. The more the chromosomes, the slower the algorithm converges. In contrast, neural networks start at an arbitrary point then follow gradient information searching every dimension, respectively, thus the computation assignment does not increase much.
However, the proposed neural network model is a purely gradient guided algorithm which could not escape from the attraction of local minima of x or local maxima of y spontaneously.
 | |
| Fig. 1: | Geometric information of f when x = (7.0711, 7.0711) (y = (y1, y2) are the vector when n = 2 in Eq. 2) |
| Table 1: | Comparisons among genetic algorithm, simplex-genetic algorithm and the minimax neural network model scheme |
 | |
| x = (x1, x2) and y = (y1, y2) are vectors where n = 2 | |
This algorithm is global stable but does not guarantee that global minima or maxima are bound to reach. Since some algorithms, such as simulated annealing, evolutionary algorithm, gradient descent with multi-starts (Wah et al., 2000), perform well in global optimization, combination with neural network may be a way out. Nevertheless, how to combine them with only little sacrifice of speed is still an open topic.
CONCLUSIONS
In this letter, a novel kind of neural network for general minimax problems with both equality and inequality constraints has been constructed based on the penalty function approach. There is no explicit restriction imposed on the functional form. A Lyapunov function is established for the global stability analysis. Finally, simulation results show that the proposed model exhibits remarkable capability in solving general nonlinear minimax programming. In a word, the proposed minimax neural network is a powerful computing tool in minimax problem research.
ACKNOWLEDGMENTS
The authors would like to gratefully acknowledge the financial support from the National Nature Science Foundation of China under grant No. 61070003 and 61071128; Zhejiang Provincial Natural Science Foundation of China under grant No. R1090052 and Y1101184; Project of Zhejiang Department of Education under the grant No. N20100690.
REFERENCES
- Chao, H.C., C.S. Lin and B.C. Chieu, 2000. Minimax design of FIR digital all-pass filters. IEEE Trans. Circuits Syst., 47: 576-580.
CrossRefDirect Link - Liu, B.D., 1998. Stackelberg-nash equilibrium for multilevel programming with multiple followers using genetic algorithms. Comput. Math. Appl., 36: 79-89.
Direct Link - Longhua, M., Z. Yongling and Q. Jixin, 2001. A new hybrid genetic algorithm for global minimax optimization. Int. Conf. Info-tech Info-Net, 4: 316-323.
CrossRefDirect Link - Wah, B.W., T. Wang, Y. Shang and Z. Wu, 2000. Improving the performance of weighted Lagrange-multiplier methods for nonlinear constrained optimizatin. Inform. Sci., 124: 241-272.
CrossRefDirect Link - Li, H., F.X. Yu, X.l. Zhou and H. Luo, 2010. Every connection routing under modified random waypoint models in delay tolerant mobile networks. Inform. Technol. J., 9: 1686-1695.
CrossRefDirect Link - Jia-Liang, G., Z. Hong-Xia and Z. Jin, 2010. Fuzzy logic based current control schemes for vector-controlled asynchronous motor drives. Inform. Technol. J., 9: 1495-1499.
CrossRefDirect Link