
Jie Xu
Zhejiang University City College, Hangzhou, Zhejiang Province 310015, China
Hao Jiang
Zhejiang University City College, Hangzhou, Zhejiang Province 310015, China
Zhen Li
Department of Electrical and Electronic Engineering, Nanyang Technological University, Singapore
Information Technology Journal
Year: 2011 | Volume: 10 | Issue: 4 | Page No.: 877-882







ABSTRACT
The transmission and storage of large amounts of vertex geometry data are required for rendering geometrically detailed 3D graphic models. To mitigate bandwidth requirements, Vector Quantization (VQ) is an effective lossy compression technique for vertex data in triangular meshes. In this study, we present a new vertex encoding scheme based on VQ. Particularly, we propose a novel prediction method that generalizes the conventional parallelogram prediction method and further reduces the prediction error. During the encoding process, the vertex to be encoded is predicted by all the encoded vertices neighboring to it within a large edge-distance, instead of the encoded vertices directly connecting to it with 1-edge-distance as in the conventional parallelogram prediction. Experimental results show that, compared with the vertex encoding scheme based on the conventional parallelogram prediction, the proposed algorithm consistently achieves a higher encoding quality at the same bit rate.
PDF Abstract XML References Citation
Received: August 14, 2010;
Accepted: November 14, 2010;
Published: February 11, 2011
How to cite this article
Jie Xu, Hao Jiang and Zhen Li, 2011. 3D Mesh Compression by Generalized Parallelogram Predictive Vector Quantization. Information Technology Journal, 10: 877-882.
DOI: 10.3923/itj.2011.877.882
URL: https://scialert.net/abstract/?doi=itj.2011.877.882
DOI: 10.3923/itj.2011.877.882
URL: https://scialert.net/abstract/?doi=itj.2011.877.882
INTRODUCTION
Interactive computer graphics plays an important role in various fields such as entertainment, manufacturing and virtual reality When combining the graphics technology with the Internet, the transmission delay for 3D graphics data is becoming a major performance bottleneck, especially for meshes consisting of millions of triangles (Chou and Meng, 2002). As regard to the limited network bandwidth, as well as the storage problem within host systems, reducing the amount of data is, go without saying, an effective solution. Consequently, the interests in compression techniques for the 3D geometry data have surged in recent years.
At present, connectivity compression has reached its limit of less than two bits per triangle for the connectivity portion of a mesh; On the other hand, relatively more works need to be done in the geometry portion of a triangle mesh. Therefore, it is necessary to develop effective compression techniques for the vertex data in order to further reduce overall mesh representation and to meet geometry bandwidth requirements.
In this study, we are engaged in the application of Vector Quantization (VQ) (Gray, 1984) as an effective compression technique for vertex geometry data. So far, VQ is a popular technique for data compression and has already been extensively applied in audio, still image and video coding (Ilyas et al., 2010; Al-Husainy, 2007; Naushahi et al., 2006). It has many advantages over entropy coding, for example, high rate-distortion performance, real-time decompression for its simple decoding and hardware tractability. Furthermore, we assume that the new triangle can be reconstructed by the neighboring previously reconstructed triangles, so the compatibility is maintained for most existing connectivity compression schemes.
Prior work: The early works usually quantize, uniformly and separately, the vertex positions for each coordinate in the Cartesian space. Deering (1995) first proposed a vertex data compression scheme where positions are first normalized within an axis-aligned bounding box. Since then, many variations of Deering’s scheme were proposed (Deering, 1995; Touma and Gotsman, 1998; Taubin et al., 1998) and more sophisticated vector quantization schemes have been proposed by Chou and Meng (2002) and Lee and Ko (2000) as well. Karni and Gotsman (2000) demonstrated the relevance of applying quantization in the space denoted by spectral coefficients. Sorkine et al. (2003) addressed the issue on how to reduce the visual effect due to quantization errors.
As for the prediction scheme, the early work (Deering, 1995) employed simple delta coding or linear prediction along the vertex order dictated by the coding of the connectivity data (Touma and Gotsman, 1998; Taubin et al., 1998). The approach proposed by Lee et al. (2002) achieves better visual appearance by applying quantization in the angle space after prediction. Inspired by the TG parallelogram prediction scheme (Touma and Gotsman, 1998). Isenburg and Alliez (2002) complete the techniques described by Khodakovsky et al. (2002) by generalizing it to polygon mesh geometry compression. Kronrod and Gotsman (2002), prediction trees are employed to improve the prediction where the geometry drives the traversal order instead of the connectivity. Sorkine et al. (2003) suggest a multi-way prediction technique, where each vertex position is predicted from all its neighboring vertices, as opposed to the one-way parallelogram prediction. In the approach proposed by Shikhare et al. (2001), the redundancy is removed by detecting similar geometric patterns.
Proposed method: The basic idea for vertex encoding in the existing 3D mesh geometry compression schemes is the parallelogram prediction, which predicts the vertex based on the assumption of planer mesh surface. In this work, we propose a VQ scheme which optimally employs the correlation between the vertex to be encoded and its adjacent encoded vertices in a larger edge-distance. The proposed prediction method is a generalized parallelogram prediction algorithm, which achieves better quality at the same bit rate as verified in the experiment section.
Conceptually, VQ is a generalization of non-uniform scalar quantization to operate on vectors rather than scalars and offers superior performance over scalar quantization in terms of rate-distortion (Gray and Neuhoff, 1998). VQ can be defined as a mapping procedure from a q-dimension Euclidian space to a finite subset, i.e., Q: Rq→ C, where the subset C = {ci |i = 1, 2,...,N} is called codebook, in which ci is a codevector and N is the codebook size. The mapping procedure is as follows: Select an appropriate codevector cp = (cp0, cp1, cp (q-1)) as the decoded vector for the training vector x = (x0, x1,...,x (p-1)), to guarantee that the codevector ---- is the closest vector to x amongst all the codevectors in C. The distance metric is usually the square Euclidian measure as follows:
| (1) |
Vector quantizer design: The first issue in designing a VQ scheme for compressing any kind of source is how to map the source data into a vector sequence as the input of the vector quantizer.
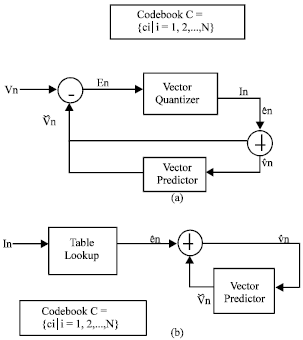 | |
| Fig. 1: | Predictive vector quantizer (a) encoder and (b) decoder (a) Encoder (b) Decoder |
We exploit Predictive Vector Quantization (PVQ) (Cuperman and Gersho, 1985) that is proper for 3D mesh compression (Chou and Meng, 2002). A block diagram of the PVQ encoder and decoder is shown in Fig. 1. In order to exploit the correlation between vertices, it is necessary to use a vector quantizer with memory. Let {vi}Ni=0 represent the sequence of vertices encountered as a mesh is being traversed dictated by its topology information and let vn be the vertex to be encoded. The encoder forms a prediction vn of vn based on observations of previously encoded vertices. The residual vector en, i.e. the error vector, is then computed as en = vn - vn. This residual vector is then quantized by the vector quantizer, which generates a codevector e’n that approximates en. The index identifying this codevector is then stored or transmitted to the decoder. Each vertex is thus encoded with log 2 N bits in ordinary VQ, where N is the codebook size.
To permit reconstruction of the vertices by the decoder, the prediction must only be based on previous reconstructed vertices. Therefore, the encoder also needs to reconstruct the vertex to be encoded for computing the prediction vectors for subsequent vertices. The decoder receives the sequence of indices. Given an index, the decoder first performs a table lookup operation to obtain the residual vector e’n. The decoder then adds en and vn as shown in Eq. 2 to reconstruct the quantized vertex vn. As in the case of the encoder, vn is fed back to the predictor for computing subsequent vertex predictions. The residual vectors are then used as training vectors to generate the codebook based on the minimax partial distortion competitive learning technique (Zhu and Po, 1998). Compared with some well-known codebook design algorithms, the MMPDCL algorithm consistently produces the best codebooks with the smallest average distortions.
Prediction design: The proposed prediction scheme is inspired by the famous parallelogram prediction rule (Isenburg and Alliez, 2002), which is intuitively illustrated in Fig. 2. In parallelogram prediction, a vertex is predicted by its neighboring triangle, exploiting the tendency for neighboring triangles to be roughly coplanar and similar in size. This is particularly true for high-resolution, scanned meshes, which have little variation in the triangle size. Suppose that ![]() and
and ![]() in Fig. 2 are the three vertices of a neighboring triangle buffered by the encoder. Then, an effective and computationally inexpensive way to compute the prediction vnof the next vertex vn is:
in Fig. 2 are the three vertices of a neighboring triangle buffered by the encoder. Then, an effective and computationally inexpensive way to compute the prediction vnof the next vertex vn is:
| (2) |
However, in case of more curving 3D meshes, Eq. 2 is not proper any more. To tackle this problem, we propose a generalized prediction scheme here, in which en is minimized by observing the encoded vertices within k-ring edge-distance to achieve a better prediction.
If we consider vi ∈M, a vertex whose 3D coordinates are given by the vector vi, from the 3D mesh M, we define its r-ring neighborhood as the vertices connected to it with a r-edge distance:
| (3) |
where, |vj vi| denotes set cardinality and counts the set of points on the line segment joining the two vertices, but excluding the end-points and L denotes the total number of vertices of the neighborhoods Nr (vi). The point vi is considered as being its own 0-ring neighborhood.
Then we can represent quantized vn and its neighborhood in the i-th ring as follows:
| (4) |
where vn-1 is a i-ring neighborhood to vn, m = 0, 1,...,Li and Li is the cardinality of vertices in vn’s i-ring neighborhood, while v(m)n-i and e(m)n-i are vn’s m-th prediction vector from Eq. 2 and error vector, respectively.
We assume that all the triangles in the mesh are equilateral, which is an ordinary assumption in 3D mesh analyses. We define ∈(m)n-i as the average error vector e(m)n-i from the i-th ring of vn. It is certainly that when vn is the vertex to be encoded, ∈n = en (0) =en.
If the mesh surface is rather planar, we can estimate that ∀0n-i = 0, I = 0,...,k; when the shape of the surface gradually becomes more curving, it can be approximated that ∈n-i is a non-zeros constant, i.e., d2 ∈n/dn2 = 0 and then
| (5) |
When the shape of the mesh surface becomes even more curving, namely, εn-i varies more dramatically, d2εn/dn2k = 0 may occur and then dεn = dεn-1, i.e.
| (6) |
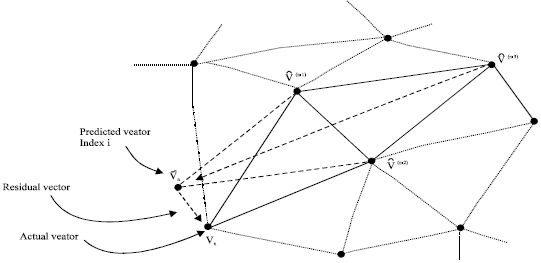 | |
| Fig. 2: | Prediction |
When the shape of the mesh satisfy the following condition:
| (7) |
Then we can generalize εn using induction theory:
| (8) |
where Cik is the combination of i out of k. It is obvious that Eq. 5 and 6 are specific instances of Eq. 8.
Then when the surface satisfies the following condition:
| (9) |
it can be iteratively deduced as follows:
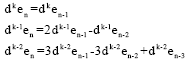 |
| (10) |
according to the assumption in Eq. 8.
From Eq. 10, we can easily deduce that:
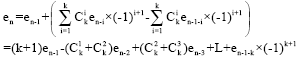 | (11) |
Combined with the basic theorem as follows:
| (12) |
we can deduce that:
| (13) |
It can be safely concluded now that assumption (8) is true according to the induction theory based on Eq. 5, 6, 8 and 13.
Now we can represent vn as follows when Eq. 7 is satisfied:
| (14) |
where vn is the newly predicted vector of vn, while εn-1 is the average of the error vector e (m)n-1 for each predicted vertex.
Now Eq. 4 is updated to the following equation:
| (15) |
where, ηn is the error vector between vn and vn and is expected to be of less magnitude than en that is generated by the conventional parallelogram prediction. Parallelogram prediction is obviously equivalent to the situation of k = 0 in the proposed algorithm. ηn is then quantized as �n and represented by its corresponding codevector index. The smaller error vectors are, the higher quantization quality is expected to be achieved.
Vertex encoding: At first, the 3 vertices of the initial triangle of the region growing process are uniformly scalar quantized at 8 bit in each coordinate and then Huffman encoded. Then we set the error vectors of these 3 vertices to be 0, i.e. if we encode the first vertex vj that is adjacent to the initial triangle, εj-1 = εj-2 = 0. Vn, , a subsequent vertex in the traversal order, is at first predicted by Eq. 2, obtaining its initial predicted vector vn and each εn-1 is computed by averaging all the error vectors in the i-ring of vn. Then the new predicted vector vn is computed according to Eq. 14. When we have encoded vn, the prediction error ηn is quantized by the codebook and identified by its corresponding codevector index. The encoded vector v’n is computed by adding vn to �n. vnis replaced with �n in order not to accumulate errors for the encoding of subsequent vertices. The error vector v’n is calculated by Eq. 4 and then buffered for computing the subsequent average error vectors.
Vertex decoding: At first, the 3 vertices of the initial triangle are Huffman decoded. When we encode a subsequent vertex vn, we get its initial predicted vertex v’n from Eq. 2 and compute each εn-1 of the i-th ring of vn. Then v’n is computed according to Eq. 14. Now vn is easily acquired by adding vn to![]() that is identified by its corresponding codevector index. The error vector en of vn is calculated by Eq. 4 and buffered. Note that when we encode the first vertex vj that is adjacent to the initial triangle, εj-1 = εj-2 = 0. Thus according to Eq. 14, it is apparent that vn = v’n and then
that is identified by its corresponding codevector index. The error vector en of vn is calculated by Eq. 4 and buffered. Note that when we encode the first vertex vj that is adjacent to the initial triangle, εj-1 = εj-2 = 0. Thus according to Eq. 14, it is apparent that vn = v’n and then ![]() = εj = ej, namely, the first VQ encoded vertex is actually predicted by the traditional parallelogram prediction rule.
= εj = ej, namely, the first VQ encoded vertex is actually predicted by the traditional parallelogram prediction rule.
Residual vector quantization: In our scheme, 42507 residual vectors were randomly selected from a famous 3D mesh library (Princeton University 2001) for training the approximate universal codebook off-line, and the size of it ranges from 64 to 8192. In this way, we expect the codebook to be suitable for nearly all triangle meshes for VQ compression and can be pre-stored in each terminal in the network. Thus the compressed bit stream can be transmitted alone without any codebook in convenience.
EXPERIMENTAL RESULTS
In this study, we limit k to be 2 in order to reduce the computational complexity while maintaining prediction precision. Distortion results based on the conventional parallelogram prediction VQ is also implemented for comparison. Performance comparisons of the proposed method with the conventional parallelogram on models with various characteristics are shown in Table 1. The codebook size is 1024 for all the experimental meshes, i.e. the compression bit rate is 10.0 bpv. P1 and P2 in Table 1 denote PSNR by the conventional parallelogram method and the proposed method, respectively.
The proposed method performs as high as about 1.7 dB better than the conventional VQ for Stanford Bunny, because of the relatively smooth and curving surface which is proper for the proposed method. For Caltech Feline, some parts of the surface are jugged while other parts are smooth, so the gain of the proposed method is only 0.9 dB. The worst case appear in Fandisk, because it is rather smooth in most area (in this case the proposed method is the same as the parallelogram prediction) and in some parts, the surface is extremely jugged (in this case neither proposed method nor the parallelogram prediction works). We also experiment on a simplified version of Bunny, in order to verify the scalability of the proposed method. Although the surface of the simplified model becomes more jugged than that of the original model, the proposed method also achieves a gain of 0.7 dB.
PSNR in this study is defined as PSNR 20log10 Peak/d, where peak is the mesh bounding box diagonal and d is the root mean square error defined by symmetric face to face Hausdorff distance (Aspert et al., 2002):
| (16) |
where, d (X, Y) is the asymmetric distance from the mesh X to mesh Y and is defined as:
| (17) |
where, d (X, Y) is the Euclidean distance from a point x on X to its closest point on Y and A (X) is the area of X.
| Table 1: | Comparisons of two methods on different meshes |
 | |
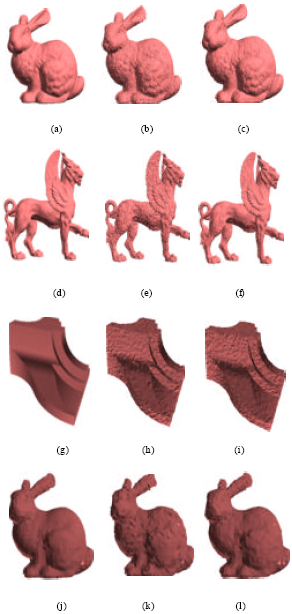 | |
| Fig. 3: | Rendered meshes of the uncompressed models, compressed models with parallelogram prediction and proposed methods. (a, b, c) Bunny models (d, e, f) Feline models (g, h, i) Fandisk models (j, k, l) Simplified Bunny models. Models in the three columns are the uncompressed, compressed with parallelogram prediction and compressed with the proposed multi-ring prediction, respectively |
To illustrate, Fig. 3 depicts the Bunny, Feline, Fandisk and the simplified Bunny meshes uncompressed, compressed with the parallelogram VQ method and compressed with the proposed method for comparison.
CONCLUSIONS
This study has demonstrated that the proposed generalized parallelogram prediction scheme based vector quantization is a promising VQ technique for compressing the geometry of triangle meshes. Experimental results indicate that the proposed prediction scheme shows superior performance over the conventional parallelogram prediction scheme which has been used extensively in 3D triangular mesh compression. The prominent benefits of the proposed technique include superior rate-distortion performance, efficient decompression that is amenable to hardware implementation, compatibility with existing connectivity compression schemes and maintaining low computation complexity. The future work will concentrate on the estimation of k based on the characteristics of local surface patches in order to achieve a better rate-distortion performance while maintaining low computation complexity.
ACKNOWLEDGMENT
This study was supported by Science Foundation of Zhejiang Province in China “electronic walking Assistive Technology Research based on Multi-dimensional continuous data Sonification” (grant No. Y1080338).
REFERENCES
- Deering, M., 1995. Geometry compression. Proceedings of the 22nd Annual Conference on Computer Graphics and Interactive Techniques, (ACCGIT`95), ACM., New York, USA., pp: 13-20.
Direct Link - Touma, C. and C. Gotsman, 1998. Triangle mesh compression. Proceedings of the Graphics Interface, June 1998, Vancouver, Canada, pp: 26-34.
Direct Link - Taubin, G., W. Horn, J. Rossignac and F. Lazarus, 1998. Geometry coding and VRML. Proc. IEEE, 86: 1228-1243.
CrossRef - Chou, P.H. and T.H. Meng, 2002. Vertex data compression through vector quantization. IEEE Trans. Visualization Comput. Graphics, 8: 373-382.
Direct Link - Lee, E. and H. Ko, 2000. Vertex data compression for triangular meshes. Proceedings of the Pacific Graphics, Oct. 3-5, Hong Kong, China, pp: 225-234.
Direct Link - Karni, Z. and C. Gotsman, 2000. Spectral compression of mesh geometry. Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, (CGIT`00), ACM Press/Addison-Wesley Publishing Co., New York, USA., pp: 279-286.
Direct Link - Sorkine, O., D. Cohen-Or and S. Toldeo, 2003. High-pass quantization for mesh encoding. ACM Int. Conf. Proc. Ser., 43: 42-51.
Direct Link - Khodakovsky, A. P. Alliez, M. Desbrun and P. Schroder, 2002. Near-optimal connectivity encoding of 2-manifold polygon meshes. Graphical Models, 64: 147-168.
CrossRef - Kronrod, B. and C. Gotsman, 2002. Optimized compression of triangle mesh geometry using prediction trees. Proceedings of the 1st International Symposium on 3D Data Processing, Visualization and Transmission, Nov. 7, Technion-Israel Institute of Technology, Haifa, pp: 602-608.
CrossRef - Cuperman, V. and A. Gersho, 1985. Vector predictive coding of speech at 16 kbits/s. IEEE Trans. Commun., 33: 685-696.
Direct Link - Zhu, C. and L.M. Po, 1998. Minimax partial distortion competitive learning for optimal codebook. Design. IEEE Trans. Image Process., 7: 1400-1409.
CrossRef - Ilyas, M.Z., S.A. Samad, A. Hussain and K.A. Ishak, 2010. Improving speaker verification in noisy environments using adaptive filtering and hybrid classification technique. Inform. Technol. J., 9: 107-115.
CrossRefDirect Link - Al-Husainy, M.A.F., 2007. A tool for compressing images based on genetic algorithm. Inform. Technol. J., 6: 457-462.
CrossRefDirect Link - Naushahi, K.R., M.A.U. Khan and M.S.H. Khiyal, 2006. Lossless image coding using conditional entropy constrained vector quantization. Inform. Technol. J., 5: 1136-1139.
CrossRefDirect Link