
Dheeb Al Bashish
Department of Information Technology, Al-Balqa Applied University, Salt Campus, Jordan
Malik Braik
Department of Information Technology, Al-Balqa Applied University, Salt Campus, Jordan
Sulieman Bani-Ahmad
Department of Information Technology, Al-Balqa Applied University, Salt Campus, Jordan
Information Technology Journal
Year: 2011 | Volume: 10 | Issue: 2 | Page No.: 267-275







ABSTRACT
The aim of this study is to design, implement and evaluate an image-processing-based software solution for automatic detection and classification of plant leaf diseases. Studies show that relying on pure naked-eye observation of experts to detect and classify such diseases can be prohibitively expensive, especially in developing countries. Providing fast, automatic, cheap and accurate image-processing-based solutions for that task can be of great realistic significance. The methodology of the proposed solution is image-processing-based and is composed of four main phases; in the first phase we create a color transformation structure for the RGB leaf image and then, we apply device-independent color space transformation for the color transformation structure. Next, in the second phase, the images at hand are segmented using the K-means clustering technique. In the third phase, we calculate the texture features for the segmented infected objects. Finally, in the fourth phase the extracted features are passed through a pre-trained neural network. As a testing step we use a set of leaf images taken from Al-Ghor area in Jordan. Present experimental results indicate that the proposed approach can significantly support an accurate and automatic detection and recognition of leaf diseases. The developed Neural Network classifier that is based on statistical classification perform well in all sampled types of leaf diseases and can successfully detect and classify the examined diseases with a precision of around 93%. In conclusion, the proposed detection models based neural networks are very effective in recognizing leaf diseases, whilst K-means clustering technique provides efficient results in segmentation RGB images.
PDF Abstract XML References Citation
Received: July 25, 2010;
Accepted: September 28, 2010;
Published: October 19, 2010
How to cite this article
Dheeb Al Bashish, Malik Braik and Sulieman Bani-Ahmad, 2011. Detection and Classification of Leaf Diseases using K-means-based Segmentation and Neural-networks-based Classification. Information Technology Journal, 10: 267-275.
DOI: 10.3923/itj.2011.267.275
URL: https://scialert.net/abstract/?doi=itj.2011.267.275
DOI: 10.3923/itj.2011.267.275
URL: https://scialert.net/abstract/?doi=itj.2011.267.275
INTRODUCTION
Plant diseases have turned into a nightmare as it can cause significant reduction in both quality and quantity of agricultural products (Weizheng et al., 2008), thus negatively influence the countries that primarily depend on agriculture in its economy (Babu and Srinivasa Rao, 2010). Consequently, detection of plant diseases is an essential research topic as it may prove useful in monitoring large fields of crops and thus automatically detect the symptoms of diseases as soon as they appear on plant leafs.
Monitoring crops for to detecting diseases plays a key role in successful cultivation (Babu and Srinivasa Rao, 2010; Camargo and Smith, 2009; Weizheng et al., 2008). The naked eye observation of experts is the main approach adopted in practice (Weizheng et al., 2008). However, this requires continuous monitoring of experts which might be prohibitively expensive in large farms. Further, in some developing countries, farmers may have to go long distances to contact experts, this makes consulting experts to very expensive and time consuming (Babu and Srinivasa Rao, 2010; Camargo and Smith, 2009). Therefore; looking for a fast, automatic, less expensive and accurate method to detect plant disease cases is of great realistic significance (Babu and Srinivasa Rao, 2010; Camargo and Smith, 2009).
Studies show that image processing can successfully be used as a disease detection mechanism (Weizheng et al., 2008; El-Hally et al., 2004). Since, the late 1970s, computer-based image processing technology applied in the agricultural engineering research became a common (Weizheng et al., 2008; Moshashai et al., 2008). In this study we propose and experimentally validate the significance of using clustering techniques and neural networks (Soltanizadeh and Shahriar, 2008; Wakaf and Saii, 2009) in automatic detection of leaf diseases.
The proposed approach is image-processing-based and is composed of four main phases; in the first phase we create a color transformation structure for the RGB leaf image and then, we apply device-independent color space transformation for the color transformation structure. Next, in the second phase, the images at hand are segmented using the K-Means clustering technique (Macqueen, 1967; Hartigan and Wong, 1979; Ali et al., 2009; Jun and Wang, 2008). In the third phase, we calculate the texture features for the segmented infected objects. Finally, in the fourth phase the extracted features are passed through a pre-trained neural network. As a testbed we use a set of leaf images taken from Al-Ghor area in Jordan. We test our program on five diseases which effect on the plants; they are: Early scorch, Cottony mold, Ashen mold, late scorch and tiny whiteness. Using the proposed framework, we could successfully detect and classify the examined diseases with a precision of around 93% in average. The minimum precision value was 80%.
Present experimental results indicate that the proposed approach can significantly support accurate and automatic detection of leaf diseases.
PROBLEM FORMULATION AND THE PROPOSED APPROACH
Next we describe our proposal with more details. We also compare it to the other solutions already presented in literature. We select from literature the works that have addressed the topic of plant disease detection and classification.
We propose an image-processing-based solution for the automatic leaf diseases detection and classification. We test our solution on five diseases which effect on the plants. Those diseases are: (1) Early scorch, (2) Cottony mold, (3) ashen mold, (4) late scorch and (5) tiny whiteness.
The concept of automatic plants leaves-disease detection presented in the following sections was developed on the plant leaves images acquired from Al-Ghor area in Jordan. Detection and recognition of leaves diseases are likely to give better performance and can provide clues to treat the diseases in its early stages. Visual interpretation of plant diseases manually is both inefficient and difficult; also, it requires the expertise of trained botanist. A closer inspection of the plant diseases images reveals several difficulties for the possible leaves diseases detection.
Bauer et al. (2009) the authors have worked on the development of methods for the automatic classification of leaf diseases based on high resolution multispectral and stereo images. Leaves of sugar beet are used for evaluating their approach. Suger beet leaves may get infected by several diseases, such as rusts (Uromyces betae), powdery mildew (Erysiphe betae).
 | |
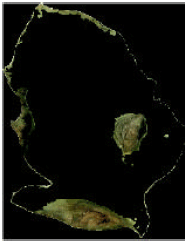
| Fig. 1: | A plant stem that is infected with the White mold disease |
The developed system classifies the leafs at hand into infected and not-infected classes. Compared to the work of Bauer et al. (2009), our systems can:
| • | Identify disease type in addition to disease detection |
| • | Deal with more diseases |
| • | Be directly expanded to cover even more diseases |
| • | Detect diseases that infect plant leaves and stems. Our proposal can identify and classify diseases that infect the stem part of plants as well. Figure 1 shows an example of such infection cases |
Weizheng et al. (2008), a fast and accurate new method is developed based on computer image processing for grading of plant diseases. For that, leaf region was segmented by using Otsu method (Sezgin and Sankur, 2004; Otsu, 1979). After that the disease spot regions were segmented by using Sobel operator to detect the disease spot edges. Finally, plant diseases are graded by calculating the quotient of disease spot and leaf areas. Our proposal is different as it aims at classifying diseased leafs based on disease type.
The proposed approach starts first by creating device-independent color space transformation structure. Thus, we create the color transformation structure that defines the color space conversion.
The next step in our proposal is that we apply device-independent color space transformation, which converts the color values in the image to the color space specified in the color transformation structure. The color transformation structure specifies various parameters of the transformation. A device dependent color space is the one where the resultant color depends on the equipment used to produce it. For example the color produced using pixel with a given RGB values will be altered as the brightness and contrast on the display device used. Thus the RGB system is a color space that is dependent. To improve the precision of the disease detection and classification process, a device independent color space is required. In a device independent color space, the coordinates used to specify the color will produce the same color regardless of the device used to draw it.
Finally, K-means clustering is used to partition the leaf image into four clusters in which one or more clusters contain the disease in case when the leaf is infected by more than one disease. K-means uses squared Euclidean distances.
The proposed approach starts first by creating device-independent color space transformation structure. Thus, we create the color transformation structure that defines the color space conversion. Then, we apply device-independent color space transformation, which converts the color values in the image to the color space specified in the color transformation structure. The color transformation structure specifies various parameters of the transformation. Finally, K-means clustering is used to partition the leaf image into four clusters in which one or more clusters contain the disease in case when the leaf is infected by more than one disease. K-means uses squared Euclidean distances.
Clustering method: K-means clustering is used to partition the leaf image into four clusters in which one or more clusters contain the disease in case when the leaf is infected by more than one disease. K means clustering algorithm was developed by Macqueen (1967) and then by Hartigan and Wong (1979). The k-means clustering algorithms tries to classify objects (pixels in our case) based on a set of features into K number of classes. The classification is done by minimizing the sum of squares of distances between the objects and the corresponding cluster or class centroid (Macqueen, 1967; Hartigan and Wong, 1979).
In present experiments, the K-means clustering is set to use squared Euclidean distances. An example of the output of K-Means clustering for a leaf infected with early scorch disease is shown in Fig. 2a-f.
It is observed from Fig. 2a-f that cluster 4 contains infected object of early scorch disease. Furthermore, clusters 1 and 2 contain the intact parts of leaf, although they are distinct from each other. However, cluster 3 represents the black background of the leaf which can be discarded primarily. Finally, the image in (f) facilitates the segmentation procedure followed in K-Means algorithm.
 | |
| Fig. 2: | An example of the output of K-Means clustering for a leaf that is infected with early scorch disease. (a) The infected leaf picture, (b, c, d, e) the pixels of the first, second, third and fourth cluster, respectively and (f) a single gray-scale image with the pixels colored based on their cluster index |
Feature extraction: The method followed for extracting the feature set is called the color co-occurrence method or CCM method in short. It is a method, in which both the color and texture of an image are taken into account, to arrive at unique features, which represent that image. Next we explain this method in more detailed.
Co-occurrence methodology for texture analysis: The image analysis technique selected for this study was the CCM method. The use of color image features in the visible light spectrum provides additional image characteristic features over the traditional gray-scale representation (Aldrich and Desai, 1994).
The CCM methodology consists of three major mathematical processes. First, the RGB images of leaves are converted into HSI color space representation. Once this process is completed, each pixel map is used to generate a color co-occurrence matrix, resulting in three CCM matrices, one for each of the H, S and I pixel maps. Hue Saturation Intensity (HSI) space is also a popular color space because it is based on human color perception (Stone, 2001). Electromagnetic radiation in the range of wavelengths of about 400 to 700 nanometers is called visible light because the human visual system is sensitive to this range. Hue is generally related to the wavelength of a light and intensity shows the amplitude of a light. Lastly, saturation is a component that measures the colorfulness in HSI space (Stone, 2001).
Color spaces can be transformed from one to another easily. In our experiment, the following equations were used to transformation the images from RGB to HSI (Ford and Roberts, 2010):
| (1) |
| (2) |
| (3) |
| (4) |
The color co-occurrence texture analysis method was developed through the use of spatial gray-level dependence matrices or in short SGDM’s (Weizheng et al., 2008). The gray level co-occurrence methodology is a statistical way to describe shape by statistically sampling the way certain grey-levels occur in relation to other grey-levels.
These matrices measure the probability that a pixel at one particular gray level will occur at a distinct distance and orientation from any pixel given that pixel has a second particular gray level. For a position operator p, we can define a matrix Pij that counts the number of times a pixel with grey-level i occurs at position p from a pixel with grey-level j. The SGDMs are represented by the function P(i, j, d, θ) where i represents the gray level of the location (x, y) in the image I(x, y) and j represents the gray level of the pixel at a distance d from location (x, y) at an orientation angle of θ. The reference pixel at image position (x, y) is shown as an asterix. All the neighbors from 1 to 8 are numbered in a clockwise direction. Neighbors 1 and 5 are located on the same plane at a distance of 1 and an orientation of 0 degrees. An example image matrix and its SGDM are already given in the three equations above. In this research, a one pixel offset distance and a zero degree orientation angle was used.
The RGB image is converted to HIS and then we calculate the feature set for H and S, we dropped the intensity (I) since it does not give extra information. However, we use GLCM function in MatLab to create gray-level co-occurrence matrix. The number of gray levels is set to 8 and the symmetric value is set to true and finally, offset is given a 0 value.
Normalizing the CCM matrices: The CCM matrices are then normalized using the equation given below, where, p (i, j, 1, 0) represents the intensity co-occurrence matrix:
| (5) |
where, Ng is the total number of intensity levels. Next is the marginal probability matrix:
| (6) |
Sum and difference matrices:
| (7) |
where, k = 1+j; for k = 0, 1, 2,..., 2(Ng-1) and:
| (8) |
where, k = |I-j|; for k = 0, 1, 2,..., 2(Ng-1) and p(i, j) is the image attribute matrix.
Texture features identification: The angular moment (I1) is a measure of the image homogeneity and is defined as
| (9) |
The mean intensity level, I2, is a measure of image brightness and is derived from the co-occurrence matrix as follows:
| (10) |
Variation of image intensity is identified by the variance texture feature (I3) and is computed as:
| (11) |
Correlation (I4) is a measure of intensity linear dependence in the image:
| (12) |
The produce moment (I5) is analogous to the covariance of the intensity co-occurance matrix:
| (13) |
Contrast of an image can be measures by the inverse difference moment (I6)
| (14) |
The entropy feature (I7) is a measure of the amount of order in an image and is computed as:
| (15) |
The sum and difference entropies (I8 and I9) can not be easilty interreted, yet low entropies indicates high levels of order. I8 and I9 can be computed by:
| (16) |
| (17) |
The information measures of correlation (I10 and I11) do not exhibit any apparent physical interpretation:
Where:
| (18) |
| (19) |
| (20) |
THE PROPOSED APPROACH-STEP-BY-STEP DETAILS
The underlying approach for all of the existing techniques of image classification is almost the same. First, digital images are acquired from environment around the sensor using a digital camera. Then image-processing techniques are applied to extract useful features that are necessary for further analysis of these images. After that, several analytical discriminating techniques are used to classify the images according to the specific problem at hand. This constitutes the overall concept that is the framework for any vision related algorithm. Figure 3 depicts the basic procedure of the proposed vision-based detection algorithm in this research.
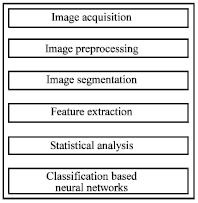 | |
| Fig. 3: | The basic procedure of the proposed vision-based disease detection algorithm |
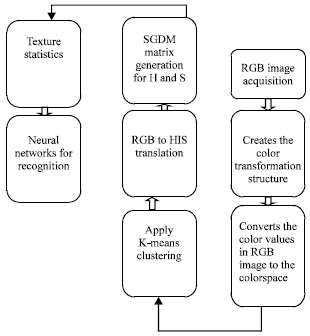 | |
| Fig. 4: | Image acquisition and classification |
The first phase is the image acquisition phase. In this step, the images of the various leaves that are to be classifies are taken using a digital camera. In the second phase image preprocessing is completed. In the third phase, segmentation using K-Means clustering is performed to discover the actual segments of the leaf in the image. Later on, feature extraction for the infected part of the leaf is completed based on specific properties among pixels in the image or their texture. After this step, certain statistical analysis tasks are completed to choose the best features that represent the given image, thus minimizing feature redundancy. Finally, classification is completed using neural network detection algorithm.
The detail step by step account of the image acquisition and classification process is shown in Fig. 4.
In the initial step, the RGB images of all the leaf samples were obtained. Some samples of those diseases are shown in the Fig. 5a-c.
 | |
| Fig. 5: | (a-c) Sample images from our dataset (a) early scorch, (b) cottony mold and (c) ashen mold |
 | |
| Fig. 6: | A leaf image infected with (a) tiny whiteness disease and (b) a normal leaf image |
From Fig. 5a-c and 6a, b it is obvious that leaves belonging to early scorch, ashen mold and normal classes showed significant difference form greasy spot leaves in terms of color and texture. The leaves belonging to these three classes had minute differences as discernible to the human eye, which may justify the misclassifications.
For each image in the data set the subsequent steps were repeated. Image segmentation of the leaf is done on each image of the leaf sample using K-Means clustering. A sample clustered image with four clusters of the leaf sample image is shown in Fig. 7. In our experiments multiple values of number of clusters have been tested. Best results were observed when the number of clusters was 4.
Once the infected object was determined. The image was then converted from RGB format to HSI format. The SGDM matrices were then generated for each pixel map of the image for only H and S images. The SGDM is a measure of the probability that a given pixel at one particular gray-level will occur at a distinct distance and orientation angle from another pixel, given that pixel has a second particular gray-level. From the SGDM matrices, the texture statistics for each image were generated.
 | |
| Fig. 7: | Clustered detected image of a leaf sample (cluster 1) |
Input data preparation: Once the feature extraction was complete, two files were obtained. They were: (1) Training texture feature data and (2) Test texture feature data. The files had 192 rows each, representing 32 samples from each of the six classes of leaves. Each row had 10 columns representing the 10 texture features extracted for a particular sample image. Each row had a unique number (1, 2, 3, 4, 5 or 6) which represented the class of the particular row of data. 1 represented Early scorch disease infected leaf. 2 represented Cottony mold disease infected leaf. 3 represented Ashen mold disease infected leaf. 4 represented late scorch disease infected leaf. 5 represented tiny whiteness disease infected leaf and 6 represented normal leaf.
Classification using neural network based on back propagation algorithm: A software routine was written in MATLAB that would take in. mat files representing the training and test data, train the classifier using the train files and then use the test file to perform the classification task on the test data. Consequently, a MATLAB routine would load all the data files (training and test data files) and make modifications to the data according to the proposed model chosen.
The architecture of the network used in this study was as follows. The number of hidden layers in the neural network was 10. The number of inputs to the neural network is equal to the number of texture features listed above. The number of output is 6 which is the number of classes representing the 6 diseases (Early scorch, Cottony mold, Ashen mold, late scorch, tiny whiteness) and the normal leafs. The neural network used is the feed forward back propagation. The performance function was the Mean Square Error (MSE) and the number of iterations was 10000 and the maximum allowed error was 10-5.
EXPERIMENTAL RESULTS AND OBSERVATIONS
With these parameters, the network was trained. Once the training was complete, the test data for each class of leaves was tested. The results for NN classification strategy that were used are given in Table 1.
The results shown in Table 1 were obtained using a NN classifier for five different diseases. The results reported better classification accuracies for all the data models. In particular, model M1 achieved the highest overall classification accuracy. Model M1 achieved an overall accuracy of 89.5%, model M2 achieved an overall accuracy of 84.0% and model M3 achieved an overall accuracy of 83.66%.
However, it should be noted that models M4 and M5 involve calculation of intensity texture features, which is disadvantageous in terms of computational complexity. Therefore, it is deciphered that model M1 is the overall best model in this classifier. One more advantage of using M1 is the decrease in computational time for training and classification. This is because of the elimination of intensity features and because of the less number of features present in the model.
The recognition rate for NN classification strategy of HS and HSI models for early scorch, cottony mold and normal leaf image were shown in Table 2.
The results shown in Table 1 were obtained using Neural Network based on Back Propagation principle for 10 testing images of the three testing types. In particular, model M1 achieved better overall classification rates than model M5. Model M1 achieved an overall accuracy of 99.66% and model M5 an accuracy of 96.66%. However, it should be noted that model M5 involves calculation of intensity texture features as already explained in the above paragraphs. Therefore, model M1 is the overall best model in this classifier.
In general, Table 1 and 2 prove that the results for NN classifier based on statistical classification perform well in both cases, it is not useful in real world applications, since choosing only intensity may be detrimental to the classification task due to inherent intensity variations in an outdoor lighting environment. Hence, model M1 emerges as the best model in classifiers based on statistical classification.
It is evident from Table 1 and 2 that, for models M4 and M5, the classification accuracies for some classes of leaves were inconsistent with the excellent results that were obtained for other models. Similarly, from Table 1 and 2, the results for neural network classifiers also show some discrepancies in terms of accuracies for some models. In the case of neural network with back propagation as well as with radial basis functions, model M4 (with only intensity features) performs poorly. This can be attributed to the fact that the network did not have enough information (in other words, there was overlapping of data clusters) to make a perfect classification hyperplane to separate the data clusters belonging to various classes of leaves. The intensity of the leaves when considered as a whole may not have incorporated enough information, for the network to make correct classification decisions. This proves the fact that for neural network classifiers using only intensity texture features will not yield good classification. One significant point to be noted in neural network classifiers is that the results may not be consistent across several trials using the same input and parameters. This is because the weight initialization in the network is random. Hence, the outputs vary. The results for neural network classifiers that were shown in this research were the average of outputs (classification accuracies) for three successive trials.
Model M1 emerged as the best model among various models. It was noted earlier, that this was in part because of the elimination of the intensity texture features. Elimination of intensity is advantageous in this study because it nullifies the effect of intensity variations. Moreover, it reduces the computational complexity by foregoing the need to calculate the CCM matrices and texture statistics for the intensity pixel map. However, in an outdoor application, elimination of intensity altogether may have an effect on the classification, since the ambient variability in outdoor lighting is not taken into consideration.
| Table 1: | Percentage classification accuracy results of the test data from various diseases |
 | |
| Table 2: | Percentage classification accuracy results for neural network using back propagation |
| Table 3: | Classification results per class for neural network with back propagation |
 | |
Table 3 shows the number of leaf samples classified into each category for the neural network classifier with back propagation algorithm using model M1.
The results show that a few samples from late scorch and tiny whiteness leaves were misclassified. For the case of Late scorch infected leaves, five test images were misclassified. Two leaf samples were misclassified as belonging to normal leaf class and the others as a Cottony mold, Ashen mold and Tiny whiteness infected leaves. Similarly, in the case of tiny whiteness images, three test images from the class were misclassified as belonging to ashen mold, late scorch and normal classes. In general, it was observed in various trials that misclassifications mainly occurred in four classes; cottony mold, late scorch, tiny whiteness and normal.
ABOUT THE ADCGPD PROJECT
The research conducted in this study is part of a project titled by Automatic Detection and Classification of the Ghor-area Plant Diseases, or the ADCGPD project for short. The main goal of the project is to develop and implement a software solution to detect and classify the main diseases that can be observed in the Ghor area in the Jordan valley. The first step of this project, presented in this study, is to provide a solution for detecting and classifying five diseases; they are: Early scorch, Cottony mold, Ashen mold, late scorch and tiny whiteness. As a next step, we are working on automatically estimating the severity of the detected disease in addition to identifying it. This research is partially supported by the deanship of scientific research at Al-Balqa Applied University. The ADCGPD project has started in February 2010.
CONCLUSIONS AND FUTURE WORK
In this study an image-processing-based approach is proposed and used for leaf disease detection. We test our program on five diseases which effect on the plants; they are: Early scorch, Cottony mold, ashen mold, late scorch, tiny whiteness.
The proposed approach is image-processing-based and is highly based on K-Means clustering technique and Artificial Neural Network (ANN). The approach is composed of four main phases; after the preprocessing phase, the images at hand are segmented using the K-means technique, then some texture features are extracted in which they are passed through a pre-trained neural network. As a testbed we use a set of leaf images taken from the Ghor area in Jordan.
Present experimental results indicate that the proposed approach is a valuable approach and can significantly support accurate and automatic detection of leaf diseases. Based on our experiments, the developed Neural Network classifier that is based on statistical classification perform well and can successfully detect and classify the tested diseases with a precision of around 93%.
For future research, they have been some directions, such as, developing better segmentation technique; selecting better feature extraction and culling classification algorithms.
REFERENCES
- Aldrich, B. and M. Desai, 1994. Application of spatial grey level dependence methods to digitized mammograms, Image Analysis and Interpretation, 1994. Proceedings of the IEEE Southwest Symposium on, April 21-24, UK., pp: 100-105.
CrossRef - Ali, S.A., N. Sulaiman, A. Mustapha and N. Mustapha, 2009. K-means clustering to improve the accuracy of decision tree response classification. Inform. Technol. J., 8: 1256-1262.
CrossRefDirect Link - Camargo, A. and J.S. Smith, 2009. An image-processing based algorithm to automatically identify plant disease visual symptoms. Biosyst. Eng., 102: 9-21.
CrossRef - Hartigan, J.A. and M.A. Wong, 1979. Algorithm AS 136: A K-means clustering algorithm. J. R. Stat. Soc. Ser. C (Applied Stat.), 28: 100-108.
CrossRefDirect Link - MacQueen, J., 1967. Some methods for classification and analysis of multivariate observations. Proc. 5th Berkeley Symp. Math. Statist. Prob., 1: 281-297.
Direct Link - Moshashai, K., M. Almasi, S. Minaei and A.M. Borghei, 2008. Identification of sugarcane nodes using image processing and machine vision technology. Int. J. Agric. Res., 3: 357-364.
CrossRefDirect Link - Otsu, N., 1979. A threshold selection method from gray-level histogram. IEEE Trans. Syst. Man Cybern., 9: 62-66.
CrossRefDirect Link - Sezgin, M. and B. Sankur, 2004. Survey over image thresholding techniques and quantitative performance evaluation. J. Electron. Imaging, 13: 146-165.
CrossRefDirect Link - Weizheng, S., W. Yachun, C. Zhanliang and W. Hongda, 2008. Grading method of leaf spot disease based on image processing. Proceedings of the 2008 International Conference on Computer Science and Software Engineering, Dec. 12-14, CSSE, IEEE Computer Society, Washington, DC., pp: 491-494.
Direct Link - Jun, W. and S. Wang, 2008. Image thresholding using weighted parzen-window estimation. J. Applied Sci., 8: 772-779.
CrossRefDirect Link - Wakaf, Z. and M.M. Saii, 2009. Frontal colored face recognition system. Res. J. Inform. Technol., 1: 17-29.
CrossRefDirect Link - Soltanizadeh, H. and S.B. Shokouhi, 2008. Feature extraction and classification of objects in the rosette pattern using component analysis and neural network. J. Applied Sci., 8: 4088-4096.
CrossRefDirect Link
karthick Reply
sir me doing M.E then i am doing project for detection for disease in one leaf .what and all algorithm me used pso ,genetic, abc algorithm and which one is best ,,,,r any other algorithm used ..please send have any coding for this project help me.....
Seth lfc Reply
Hello can i get this project code on matlab fully and its pdf. Thank you
RANGASWAMY H Reply
I need code on leaf disease identification.
chirunjeevi Reply
i want the project code
Floris Olivier Reply
Github Link?