
Ruogu Zhou
School of Computer, National University of Defense Technology, Changsha, 410073, China
Feng Ding
School of Computer, National University of Defense Technology, Changsha, 410073, China
Li Lu
School of Computer, National University of Defense Technology, Changsha, 410073, China
Information Technology Journal
Year: 2011 | Volume: 10 | Issue: 7 | Page No.: 1295-1304







ABSTRACT
There exist many deficiencies in current video surveillance system such as high expenditure, information omitting, data analysis difficulty, long response. This study proposes a design scheme of intelligent alarm system with the main technology of motion detection, image compression and WEB server pre-fetch which improves the algorithm based on differential image motion detection, controls the costs and reduces false positives. The system features as low cost but fast response with improvement of Loeffler algorithm and the quality of image compression while the decreasing of storage space and transmission bandwidth. It also improves the intelligent Wcol prediction algorithm, predicts the page that user will read soon and eventually improves the efficiency of WEB server. Experiments show that: this system reduces the false alarm rate, avoids filtering, has certain adaptability to light changes, reduces or even eliminates the interference of the CCD jitter, can accurately extract the moving object location. The total time of compressing 100 BMP images and completing the USB storage is lower than 48 sec. The performance that the server with pre-fetch module visits the next page at the second time is better than the performance that the server with no pre-fetch module visits the next page at the second time.
PDF Abstract XML References Citation
Received: January 31, 2011;
Accepted: April 07, 2011;
Published: June 10, 2011
How to cite this article
Ruogu Zhou, Feng Ding and Li Lu, 2011. Development and Implementation of Intelligent Video Surveillance Alarm System. Information Technology Journal, 10: 1295-1304.
DOI: 10.3923/itj.2011.1295.1304
URL: https://scialert.net/abstract/?doi=itj.2011.1295.1304
DOI: 10.3923/itj.2011.1295.1304
URL: https://scialert.net/abstract/?doi=itj.2011.1295.1304
INTRODUCTION
Today video surveillance systems show two main drawbacks, namely: they are not flexible in adapting to different operative scenarios (they only work in a well known and structured world); they generally need the assistance of a human operator in order to recognize and to tag specific visual events (Wong et al., 2009). Because humans being can not serve as fully trusted observer, this model itself may lead to omission phenomenon (Hapsari and Prabuwono, 2010). The need of people to judge against threat will cause a delay of security alerts and too long response time of security threats. Mass storage of data also increases the cost of video surveillance.
For these shortcomings of video surveillance systems, many new technologies are proposed. Mecocci et al. (2003) devised an automatic real-time video surveillance system, capable of autonomously detecting anomalous behavioral events. The proposed system is capable of automatically adapting to different scenarios without any human intervention and uses robust self-learning techniques to automatically learn the typical behaviour of the targets in each specific operative environment. A wireless video surveillance system supporting wide area access based on 3G network is proposed (Ruichao et al., 2009). Guo et al. (2010) implements and analyzes several commonly used methods for moving object detection in video surveillance system, such as temporal difference, median filtering and Single Gaussian model. Wong et al. (2009) proposed a surveillance system, the Omni directional scenes within a digital home are first captured using a web camera attached to a hyperbolic optical mirror. The captured scenes are then fed into a laptop computer for image processing and alarm purposes. Log-polar mapping is proposed to map the captured Omni directional image into panoramic image, hence providing the observer or image processing tools a complete wide angle of view. It can cover a wide angle of view (360deg Omni directional), small in size, low cost, lightweight, output images are with higher data compression and accurate trespasser detection. Moon and Pan (2009) analyses conventional methods of privacy protection in surveillance camera systems and applied scrambling and RFID system to existing surveillance systems to prevent privacy exposure in monitoring simultaneously for both privacy protection and surveillance. A new approach is proposed for a smart video surveillance system by Xu and Wu (2010). The proposed surveillance system uses canonical stereo configuration to set up a pair of statical cameras to support a salient map to control a Pan-Tilt-Zoom (PTZ) camera/cameras, which captures high definition image/video of the interesting moving object in the surveillance area for further forensic investigations. The other contribution of the proposed approach is that, 3D information generated by the set of static cameras is used to support reliable spatial-temporal based image segmentation and object detection.
The system which has been developed by us is characterized by its smart, convenience and power, which can process images in real time with its motion detection, thus eliminate the need to monitor staff. Its auto-recording of scene and efficient image data backup provides users with clear and reliable picture.
Software architecture of intelligent video surveillance alarm system: The hardware platform of the intelligent video surveillance alarm systems involves ARM9 2410 processor and OV7620 + OV511 image acquisition card. Linux operating system is its software platform.
System software modules are divided into digital image acquisition module, image control detection module, image compression module, memory module and WEB modules. The overall framework of the system software is shown in Fig. 1. Image control detection, image compression, WEB pretreatment is the key to implementation of the system. Essential parts of the overall framework of the system which is shown in Fig. 1, include image control detection, image compression and WEB pretreatment.
The improved algorithm of differential image motion detection: The purpose of motion detection is to detect the video image sequence and to extract the moving target (Collins et al., 2000). Currently, there are some methods for motion detection such as optical flow which is poor at real-time control and with high time expense, noise-Gaussian-distribution-based methods with a large amount of calculation and the method of difference image, which is relatively simple and with strong real-time control (Seferidis and Ghanbari, 1993; Kim et al., 1999; Hongjian, 2009).
Generally there are two kinds of difference image method one is the difference between the current continuous two images (continuous image difference method) another is the difference between the current image and the fixed background image (the fixed background motion detection). The disadvantage of the continuous image difference method is that the detected location of objects is inaccurate and the detected target is much larger than the real one. The fixed background motion detection is performed as follows: firstly the background image is stored, then the difference image by the current image and the background image is read, finally the value of each pixel and a pre-sets threshold is compared. If a pixel value of background is greater than the pre-sets threshold, it will be considered as the pixel of the moving objects and if not, it will be background point Since this technology aims to get current image and there only exists the moving object in the difference image, which is the subtract of current frame and fixed background frame.
The new motion detection algorithm based on the difference image method introduces the block thought, determines the detection threshold with the method based on noise Gaussian distribution method. Compared with traditional rule of thumb threshold method, it is more accurate and more reliable since this method joins the brightness adjustment mechanism and reduces the light changes. Specific methods are as follows: firstly, the image is reasonably divided to blocks which are the basic units of motion detection; secondly, the mean gray value of the current frame image block and the mean gray value of fixed background image block are compared; thirdly, the method based on noise Gaussian distribution method to get the detection threshold and the threshold to determine whether there is moving objects in the image are applied which aid to extract the blocks where the moving objects are in.
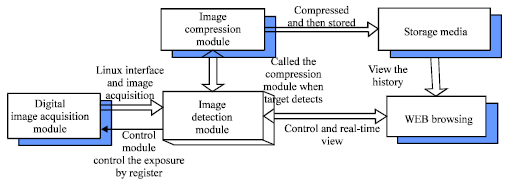 | |
| Fig. 1: | Intelligent video surveillance alarm system software architecture |
All the operations are prepared for the follow-up image compression. A brightness adjustment mechanism for the current frame is added to alleviate the impact of ambient light in motion detection which can effectively reduce or even eliminate the impact of illumination change. With the image data of a new frame, it can adaptively change the average brightness of the reference frame pixel.
The establishment of the fixed background model: At the beginning of motion detection, a pre-stored background image with no moving target constitutes the initial model. The following method to extract background model was conducted the first two consecutive frames with the difference method to determine whether there is moving objects. If there is no, the average gray values of N consecutive frames would be calculated out and one frame as the reference frame would be directed.
Since real time of motion detection algorithm is of great significance, the low cost computation algorithm is taken as the primary consideration. All moving objects have their size and the pixel brightness of each object has a certain similarity too. So there is no need to compare the image brightness of each pixel value. The image is divided into blocks whose size is similar to the objects to be detected. This method will improve the real time of motion detection.
In this system, scene images are divided into blocks with sizes about 1/4 of the body (i.e., 320x240, image is divided into 8x8, a total of 64), in order to avoid misjudgment of small objects. Selecting about 1/4 size of the human body can distinguish the movement of large objects and the motion of small size objects.
Specific identification process is as follow: when the average brightness value of a block changes was detected and the threshold was exceeded, the average brightness value of the adjacent new blocks was detected to determine whether their average brightness values exceed the threshold. Provided that the average brightness value of the new block exceeds the threshold, adjacent block based on this new block would be tested. Only when a total of four or more blocks that their average brightness exceeds the threshold were found, moving object would be identified as large-size objects.
The mechanism and experimental analysis of brightness adjustment: Changes of ambient light exert impact on fixed background motion detection. In the determination of conditions, a light-sensitive item was added. The improved conditions are as follow:
and ai is a piece of the overall image A, the total pixel number is n:
is the average brightness of all pixels in t+Δt time for the ai block:
is the average brightness of all pixels in t time for the ai block:
is the differences brightness of image A in time t+Δt and time t and the value can be positive or negative. N is the number of all pixels, the value of inhibition coefficient λ can be 1.
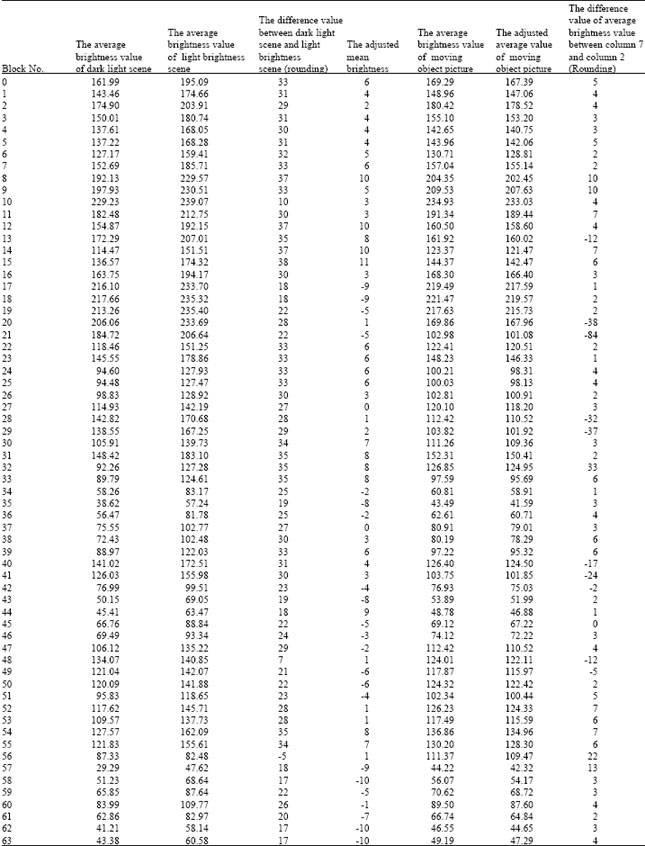
Two pictures are taken in the same scene but under different light intensity in experiment. The 2nd and 3rd column of Table 1, respectively showed the average brightness value of each divided blocks of two scenes. Data in column 2 is obviously lower than it in column 3 because of light difference. The 4th column indicated the difference value of each block between the 2nd column and the 3rd column.
In addition, the average brightness value of the whole dark light scene is 119.365257 and that of the whole light brightness scene is 146.048981. In 4th column of Table 1, the value of the 48th-block is 7, the value of the 56th-block is -5, so moving objects are in these blocks, we can not consider these blocks. Taking dark light scene as the reference frame, the light brightness scene as the detected frame, according to algorithm, the difference value between 119.365257 and 146.048981, takes -27 must be added to the average brightness of light brightness scene. The adjusted difference value of average brightness was showed on the 5th column of Table 1.
Thus, the adjusted difference values of average brightness are between -9 and 10. In other words, provided that the threshold value T is greater than 10, the changes of light intensity will not affect the results of motion detection. It shows that this improved algorithm has certain adaptability to brightness variations.
| Table 1: | The average brightness value test |
 | |
Threshold determination and experimental analysis: The motion detection algorithm based on CCD noise characteristics can be viewed as a Gaussian distribution of deviations, its background noise can be regarded as Gaussian and the average value of various random electronic noises can be regarded as 0.Therefore, the problem of determining the moving object is transformed to find whether the difference image are wholly in the rule of Gaussian distribution.
According to the "3σ" feature of Gaussian distribution, for Gaussian data, most of them distribute within the 3σ (where, σ is the standard deviation). We can set the detection threshold according to this feature and use it to determine whether the image blocks have moving objects.
In the initial motion detection, we estimate the average value of the difference image block and the initial value of variance, according to the difference image between two consecutive images and in the two consecutive images there are not any moving object. According to multiple difference images, we calculate the error between the brightness value of difference image and the estimated value. Finally, we use the iterative weighting method. By the way, the value of the standard deviation σ is determined by the physical properties of CCD, so when motion detection begins, we can determine the initial value of the standard deviation and set 3σ to be the threshold of motion detection.
Next, according to the determined threshold, we look at the algorithm’s effect of moving object detection. The standard deviation is stably at about 4; take 12 as its threshold value. Consider dark light image to be the reference frame. We take a moving object picture in experiment scene. And the 6th column of Table 1 shows the average brightness value of the picture. The average brightness value of the whole image is 121.260445.
According to the reference frame, adjust the average brightness value of each block in moving object picture, that is every block in moving object picture adds the difference value of the whole average brightness value between dark light scene and light brightness scene, i.e., 119.365257 -121.260445 = -1.895188, take -1.90, as shown in the 7th column of Table 1.
It can be seen from the 8th column of Table 1: the 21st, 22nd, 28th, 29th, 32nd, 40th, 41st, 56th blocks change very apparently. Comparing moving object picture and dark light scene, obviously, there is a person, he caused a change in the first block of 21st, 22nd, 28th, 29th and the amplitude is relatively large. Look at the more obvious changes in the 32nd, 40th, 41st, 56th blocks. We find the regional block 32nd, 40th, 41st have a case, the first 56 regional block has a cloth.
According to the threshold, we can detect a moving object in the 21st, 22nd, 28th, 29th, 32nd, 40th, 41st, 48th, 56th, 57th blocks and it is consistent with the actual situation.
According to the experimental results, the 3σ threshold for motion detection can detect the movement of large objects but also can detect the movement of small objects. And 3σ threshold should be the minimum threshold; the movement of small objects is also very sensitive. The system is mainly for large objects, so the appropriate threshold value can be increased to 3.5 or 4σ.
THE OPTIMIZATION OF JPEG COMPRESSION ALGORITHM
Storage capacity and transfer rate is an important fact of cost and performance of the video surveillance system. In order to reduce the demand for network bandwidth and save storage space, the data video system captured need to compress (Logashanmugam and Ramachandran, 2008). Compression is the most expensive part of system performance, we need design carefully. Compression module system is DCT-based. The compression process is irreversible. System uses less number of bits to get better quality restored image. The image is inputted into the encoder, through the DCT transforms, through quantization, through entropy encoded, at last compressed image is outputted.
The introduction of adaptive quantization table based on motion images: The final image compression quality and file size depend on the quantization table. Quantification is a one-to-many mapping. It is in accordance with the JPEG standard and uses a linear uniform quantizer (Han and Jie, 2007). The introduction of adaptive quantization table is to implement that: If no movement is detected, system uses the standard quantization table to loss more details. But once movement is detected, system uses optimized quantization table to retain more specific information.
Consider the complexity of the implementation and the restriction of the environment conditions, we use two set of brightness and color quantization tables to separately quantify the images with no motion and the image with motion. It not only effectively improves the quality of the detected movement image but also effectively reduces the size of the image with no movement. It also increases the number of stored images, and an implement simply, has low complexity.
The introduction of adaptive quantization table based on moving images: To the moving target and its background, we can also use the method of adaptive quantization tables. The basic idea is: we mark the results of block motion detection, according to the magnitude of each motion, adaptively change the number of quantization levels, quantify the independent part of the movement crudely and quantify the dependent part of the movement carefully. Ensuring the clarity of moving target, we also allow a small amount of movement independent blocks to have mosaic effect, thus we can speed up the compression rate and reduce the image size.
The implementation of this method based on motion detection, after the block motion detection of a picture; we refine the motion blocks and quantify the independent part of the movement crudely, desert the useless information, allow these blocks have mosaic appearance. The adaptive quantization table adopts two different quantization tables. It is contrary to the optimization of quantization table. It uses multiplying quantization table (the standard JPEG quantization table multiplied by 2) to quantify the independent part of the motion picture and makes more details to be lost, so as to reduce the size of the entire picture to improve compression ratio.
The comparison of two methods: The core of the two optimization methods is that they all use adaptive quantization table. The difference is the using level of the adaptive quantization table. Motion detection to the image with movement and the image with no movement use different quantization tables. It can effectively reduce the size of the picture which people is not interested and assure the quality of interested image. The adaptive quantization for different regions of each picture improves the efficient of image compression, highlights the goals and blurs unrelated areas. But the whole process of quantification is complex and for the performance of current development platform, the efficient will be greatly affected.
Image filtering: JPEG can compress "continuous" image well, if the image has many sudden changes in color brightness, JPEG can not work well (Haseeb and Khalifa, 2006). In view of this principle, the noise filtering of picture to a certain degree is necessary.
Median filters use nonlinear processing methods to remove noise which can be done to remove noise and also protect the edge of the image (Gonzalez and Woods, 2002). Median filtering algorithm in the system still uses a sliding window but modifies the image pixel value of the window’s center to the value in the middle of all the window’s pixel values. As a result, the noise can be removed; system can better keep the edge information.
Currently, the median value of median filter is the middle value of all the elements after sorting. But sorting needs to move a large number of elements and its efficient is low. We just try to find the middle value, so we do not really have to sort. Use the quick sort to sort, when sorting fulcrum is in the middle of the original array, we can end the cycle. The average time complexity of quick sort is O (n log2 n). Its space complexity is O (log2 n).
After filtering, the image compression ratio has increased significantly, compared to the average, the JPEG compression of 24-bit BMP images increased by about 1%.
The DCT fast algorithm: The same JPEG image compression test to a 320x240 image, in the case of Yh: Yv: Uh: Uv: Vh: Vv: = 2: 2: 1: 1: 1: 1, has six 8x8 information groups, corresponding to the sub-block of MCU is 16x16, the operation number of DCT and IDCT are 320x240x6 /(16x16) = 1800 (Abboud, 2006). Therefore, it is necessary to use fast DCT algorithm to do some other improvements: (1) Similar to the YUV and RGB conversion, convert floating-point operations to fixed-point operations and pre-calculate the cos() values to prepare for calls. (2) 8x8 2-D DCT are converted to two 8-point 1-dimensional DCT. The formula is follow:
One-dimensional fast DCT algorithms are many (Feig, 1990; Vetterli, 1985), we use a smaller computational Loeffler algorithm (Loeffler et al., 1989). The DCT algorithm for 16x16 blocks needs to do 31 times multiplications and 81 times additions. But the DCT algorithm for 8x8 blocks only needs to do 11 times multiplications and 29 times additions. The direct calculation requires 56 times multiplications, 56 times additions. Visibly fast algorithms save a lot of computation.
THE SERVER PRETREATMENT
The WEB server performance of monitoring system directly affects the speed of customer reading. To improve server performance, the system adds server page prediction modules.
The current algorithms are: referrer field method, PPM method, the prefetching method based on semantic understanding, Wcol method (Umapathi and Raja, 2006).
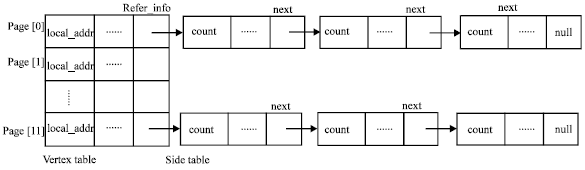 | |
| Fig. 2: | The adjacent table of web site |
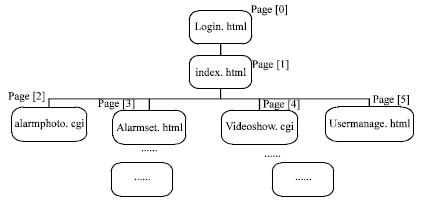 | |
| Fig. 3: | The corresponding Fig. of the pages and the vertex table |
Wcol method is very simple: if the URL user requested is a HTML document, the server will analyze the link above the embedded images and other HTML documents and then pre-fetch them and put them out to the cache.
In this system pages and links are simple. Therefore, we use Wcol intelligent prediction algorithm and do some improvements. The method considers the inter-linked pages as a graph and use adjacency list to store the graph.
Store the relevant pages of the site with a vertex table and then store the related links in the side table. When a user requests a URL, the server receives the request, parses the request URL, then pre-fetch module tries to find out from the adjacent list whether the page is in memory. If the page is not in memory, module goes to the disk to read the page and put it to memory. If the page is in memory, module directly read the page to user. At the same time, according to the information of this page which is found out from the adjacency table, the pre-fetch module finds the relevant links from side table and predicts the pages, images and other information that users may visit next, at last puts the information into memory to improve access speed.
Data structure: Pre-fetch works start around the adjacency list. All pages of the website constitute a vertex table. The reference links of a page include page information and picture information and all of them constitute a side table. Adjacency list is shown in Fig. 2. The data structure is defined as follow:
 |
The development of web site is divided into static pages module and CGI program module. The web site totally has 12 pages. The page structure is shown in Fig. 3. This structure can be viewed as a tree. Therefore, the vertex table array page [15] stores the information of the total 12 pages. The storage order of these pages is under the level priority shown in Fig. 3.
Workflow: When server starts, system builds the data structure of adjacency list. Page [2] and page [3] store image-related pages. Associated with the operation of the system, the pictures have been increasing.
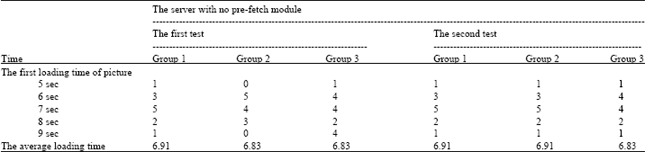
| Table 2: | The test results of the server with no pre-fetch module |
 | |
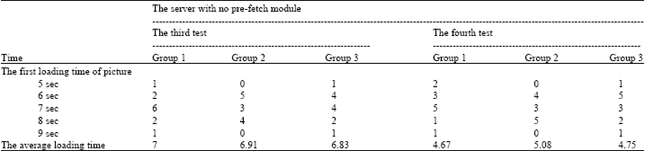
| Table 3: | The test results of the server with pre-fetch module |
 | |
The structure of side table needs to constantly update. System inserts the latest generated image information into the side table’s first node. When users access page [2] and page [3], pre-fetch procedure reads pictures from this side table into cache, waiting for the access of users, so as to achieve predication. For other common pages, their visit numbers always change, system uses count value to record visit numbers. When visit numbers plus one, system travels the whole adjacency list, the count values of all nodes of this page plus 1. At the same time, system re-links the nodes at this side table by the order of count values. Next time when user visits some node of the vertex list, the predicted page which will be read next into the cache is the first node of the vertex and also is the first node of the side table whose count value is the largest.
Performance test: In order to test the performance of this server, we compare the server with pre-fetch module to the server with no pre-fetch module, totally make four times test and each is divided into three groups.
First of all, let 12 computers on the LAN access alarmphoto.cgi the alarm image page in the server with no pre-fetch module at the first time and test its first loading time. The loading time is at about 5, 6, 7, 8 and 9 sec. In the first group we find that there is one computer whose loading time is 5 sec, three computers whose loading time is 6 sec, five computers whose loading time is 7 sec, two computers whose loading time is 8 sec, one computer whose loading time is 9 sec and the average loading time of the first group is 6.91 sec. The average loading time of the second group is 6.83 sec. The average loading time of the third group is 6.83 sec. Secondly, let 12 computers on the LAN access the next photo of alarm image page in the server with no pre-fetch module and test its second loading time. The average loading time of the first group is 6.91 sec. The average loading time of the second group is 6.91sec. The average loading time of the third group is 6.83 sec. It is shown in Table 2.
Thirdly, let 12 computers on the LAN access alarmphoto.cgi the alarm image page in the server with pre-fetch module and test its first loading time. The average loading time of the first group is 7 sec. The average loading time of the second group is 6.91 sec. The average loading time of the third group is 6.83 sec. Fourthly, let 12 computers on the LAN access the next photo of alarm image page in the server with pre-fetch module and test its second loading time. The average loading time of the first group is 4.67 sec. The average loading time of the second group is 5.08 sec. The average loading time of the third group is 4.75 sec. It is shown in Table 3.
The time of the first page download shows that: the first picture download time of the server with no pre-fetch module is between 5 and 9 sec, the average time is 6.85 sec and the first download time of the server with pre-fetch module is between 5 and 9 sec too, the average time is 6.91 sec. Experiment results show that the performances that the two servers visit the same page at the first time are the same.
The time of the second picture download shows that: the second picture download time of the server with no pre-fetch module is still between 5 and 9 sec, the average time is 6.88 sec and the second download time of the server with pre-fetch module is between 3 and 7 sec, the average time is 4.83 sec. Experiment results show that the performance that the server with pre-fetch module visits the next page at the second time is better than the performance that the server with no pre-fetch module visits the next page at the second time.
CONCLUSION
The study introduces a number of key technologies of the software architecture for video surveillance system, proposes a new motion detection algorithm, an improved image compression algorithm and an improved web server pre-fetch algorithm. The block-based fixed background difference image motion detection algorithm has a good effect. It greatly reduces the false alarm rate, avoids filtering, reduces the amount of computation, has certain adaptability to light changes, reduces or even eliminates the interference of the CCD jitter, can accurately extract the moving object location and in the course of each test only need take one frame. It is an ideal method for motion detection. The proposed improved image compression algorithm implements the adaptive quantization table compression which is based on motion detection. It converts floating-point calculations into a fixed-point calculation and uses sub-sampling and algorithm optimization to improve the performance. Test proves: the total time of compressing 100 BMP images and completing the USB storage is lower than 48 sec. This compression module in the whole system can complete the emergency compression storage function and does not affect the performance of the real-time image acquisition of the whole system. Compared with the no pre-fetch module web system, the system with improved pre-fetch algorithm has better real-time and efficiency. Experiments show that: compared with other monitoring systems, this system is lower cost, faster response and so on.
ACKNOWLEDGMENTS
The work was supported by major project fund of Ministry of Science (ECK2150A), Hunan Science and Technology Project Fund (2008GK3134) and Science Research Project Fund of Hunan Provincial Education Department (10C0202).
REFERENCES
- Wong, W.K., J.T.Y. Liew, C.K. Loo and W.K. Wong, 2009. Omnidirectional surveillance system for digital home security. Proceedings of the International Conference on Signal Acquisition and Processing, April 3-5, Kuala Lumpur, pp: 8-12.
CrossRef - Hapsari, G.C. and A.S. Prabuwono, 2010. Human motion recognition in real-time surveillance system: A review. J. Applied Sci., 10: 2793-2798.
CrossRef - Mecocci, A., M. Pannozzo and A. Fumarola, 2003. Automatic detection of anomalous behavioural events for advanced real-time video surveillance. Proceedings of the IEEE International Symposium on, Computational Intelligence for Measurement Systems and Applications, July 29-31, Siena University, Italy, pp: 187-192.
CrossRef - Ruichao, L., H. Jing and S. Lianfeng, 2009. Design and implementation of a video surveillance system based on 3G network. Proceedings of the International Conference on Wireless Communications and Signal Processing, Nov. 13-15, Nanjing, pp: 1-4.
CrossRef - Guo, H., Y. Liang Z. Yu and Z. Liu, 2010. Implementation and analysis of moving objects detection in Video Surveillance. Proceedings of the Information and Automation (ICIA), IEEE International Conference, June 20-23, Harbin, pp: 154-158.
CrossRef - Moon, H.M. and S.B. Pan, 2009. Implementation of the privacy protection in video surveillance system. Proceedings of the 3rd IEEE International Conference on Secure Software Integration and Reliability Improvement, July 8-10, Shanghai, China, pp: 291-292.
Direct Link - Xu, Z. and H.R. Wu, 2010. Smart video surveillance system. Proceedings of the IEEE International Conference on Industrial Technology, March 14-17, Australia, pp: 285-290.
CrossRef - Collins, R.T., A.J. Lipton and T. Kanade, 2000. Introduction to the special section on video surveillance. IEEE Trans. Pattern Anal. Mach. Intell., 22: 745-746.
CrossRef - Seferidis, V.E. and M. Ghanbari, 1993. General approach to block-matching motion estimation. Optical Eng., 32: 1464-1464.
CrossRef - Kim, M., J.G. Choi, D. Kim, H. Lee, M.H. Lee, C. Ahn and Y.S. Ho, 1999. A vop generation tool: Automatic segmentation of moving objects in image sequences based on spatio temporal information. IEEE Trans. Circuits Syst. Video Technol., 9: 1216-1226.
CrossRef - Hongjian, W., 2009. Vehicle flow measuring based on temporal difference image. Proceedings of the 2nd International Conference Intelligent Computation Technology and Automation, Oct. 10-11, Changsha, Hunan, pp: 717-720.
CrossRef - Logashanmugam, E. and R. Ramachandran, 2008. An improved algorithm for image compression using wavelets and contrast based quantization technique. Inform. Technol. J., 7: 180-184.
CrossRefDirect Link - Abboud, I., 2006. Deblocking in BDCT image and video coding using a simple and effective method. Inform. Technol. J., 5: 422-426.
CrossRefDirect Link - Haseeb, S. and O.O. Khalifa, 2006. Comparative performance analysis of image compression by JPEG 2000: A case study on medical images. Inform. Technol. J., 5: 35-39.
CrossRefDirect Link - Vetterli, M., 1985. Fast 2-D discrete cosine transform. Proceedings of the Acoustics, Speech and Signal Processing, (ICASSP`85), Tampa, Florida, pp: 1538-1541.
CrossRef - Loeffler, C., A. Ligtenberg, G.S. Moschytz and E.T.H. Zurich, 1989. Practical fast 1-D DCT algorithm with 11 multiplications. Proc. Int. Conf. Acoustics, Speech Signal Process., 2: 988-991.
CrossRef - Umapathi, C. and J. Raja, 2006. A prefetching algorithm for improving web cache performance. J. Applied Sci., 6: 3122-3127.
CrossRefDirect Link