
June-Yule Lee
Department of Marine Engineering, National Kaohsiung Marine University, 482, Chung-Chou 3rd Road, Chi-Jin District, Kaohsiung 805, Taiwan
Information Technology Journal
Year: 2010 | Volume: 9 | Issue: 1 | Page No.: 61-66







ABSTRACT
An extended generalized Gaussian distribution which can describe a family of symmetric and asymmetric distributions is considered. Parameter estimation of this function using maximum likelihood scheme is proposed. By measured the tail length and skewness of the observed data, the method integrates a pre-calculated table of initial values for parameters estimation. This allows a fast convergence of the presented model for real-time applications. The simulation results also show that the proposed scheme is an asymptotically unbiased estimator in terms of Cramer- Rao lower bound criterion.
PDF Abstract XML References Citation
How to cite this article
June-Yule Lee, 2010. Parameter Estimation of the Extended Generalized Gaussian Family Distributions using Maximum Likelihood Scheme. Information Technology Journal, 9: 61-66.
DOI: 10.3923/itj.2010.61.66
URL: https://scialert.net/abstract/?doi=itj.2010.61.66
DOI: 10.3923/itj.2010.61.66
URL: https://scialert.net/abstract/?doi=itj.2010.61.66
INTRODUCTION
In the field of science and engineering, the family of the Generalized Gaussian Distributions (GGD) are applied to model and detect the Gaussian and non-Gaussian signals (Miller and Thomas, 1972; Kassam, 1988). For example, in natural environments, the performance of communication systems can significantly degrade due to the atmospheric noise caused by the lightning activity in local and distant storm, or the ambient noise in the ocean. In seismic research (Walden, 1985), the non-Gaussian distribution has been used to model the amplitude distribution of the primary reflection coefficients. The aim is to estimate the reflection coefficient sequences as accurately as possible. In image processing, the fundamental work is fitting the image intensity histogram data to gain underlying knowledge of data source. Fan and Lin (2009) developed an expectation maximization algorithm to estimate the parameter of the GGD mixture model that best fit the observed image intensity histogram data. Other useful applications of the GGD also include, video coding (Sharifi and Leon-Garcia, 1995), handwritten character identification (Solihin and Leedham, 1999), speech recognition (Gazor and Zhang, 2003), etc. Therefore, the choice between different families of distribution is important and the estimation of the designed probability density function from observed data is the major task.
In this study, the parameter estimator for the extended generalized Gaussian distribution to include asymmetry is applied. The parameter estimation is determined by the maximum likelihood scheme with iteration method. The key factor of the iteration method depends on the choice of the initial and step values. Soderlind (2006) presented and discussed the approaches to step size selection in control theory and signal processing. Tlelo-Cuautle et al. (2007) proposed a procedure to control the step-size, where the step size is determined by the eigenvalues of its state matrixes. For saving the computing cost and improving the accuracy, we proposed a table look-up method.
THE MODEL
The generalized Gaussian distribution to include asymmetry proposed by Nandi and Mampel (1995) is:
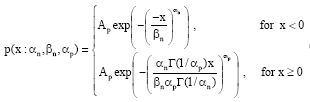 | (1) |
and
| (2) |
where, αn>0, αp>0, βn>0 and Γ is gamma function. By setting:
| (3) |
then the variance of Eq. 1 is chosen as one. By changing the parameters in Eq. 1, one can obtain symmetric (αn = αp) and asymmetric (αn ≠ αp) distributions. For symmetric cases, Fig. 1, (αn , αp) are (1,1) and (2,2) represent the Laplace distribution and Gaussian distribution, respectively. When αn tends to 0 the distribution tends to impulse and when αn tends to infinite the distribution tends to Uniform distribution. For asymmetric cases, (Fig. 2), the right skew distribution can be modeled by reducing the parameter αp and as αp decreases the tail length in the right side increases. Therefore, Eq. 1 provides a wide range of uni-modal distributions with symmetry and asymmetry.
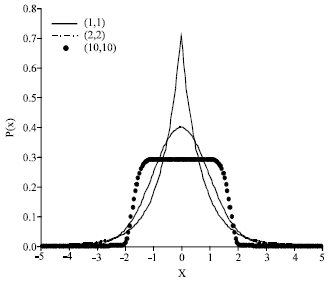 | |
| Fig. 1: | Symmetric model for varying the parameters of (αn = αp) |
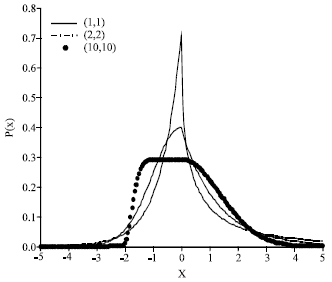 | |
| Fig. 2: | Asymmetric model for varying the parameters of (αn = αp) |
THE ESTIMATOR
Given a series samples xi, where i = 1,2,3,...,N, the likelihood function of Eq. 1 is:
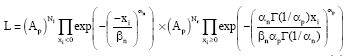 | (4) |
where, N1 (Nr) is the number of xi samples <0 (≥0). Taking the logarithm of Eq. 4, one gets:
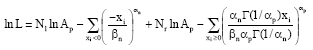 | (5) |
If ∂ InL/∂αn, ∂InL/∂βn and ∂InL/∂αp are equate to zero, then the maximum likelihood estimates αn, βn and αp are obtained, i.e.,
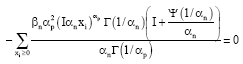 | (6) |
| (7) |
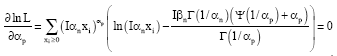 | (8) |
Where,
| (9) |
and Ψ(•) is digamma function defined as:
| (10) |
To fit the observed data and approximate the solutions αn, βn and αn, one need to solve (Eq. 6-8). In the following two iterated methods are developed.
Iterated method 1: Given a reasonable initial values αn0, βn and αp, (Eq. 6-8) can be solved iteratively for αn, βn and αp. First step, compute Eq. 6 with (αn0±Δαn) by fixed βn0 and αp0, then αn1 is selected by the value of (αn0±Δαn) or (αn0-Δαn) so that the likelihood function of Eq. 6 approaches zero. Second step, compute Eq. 7 with (βn0±Δβn) by fixed αn1 and αp0, then βn1 can be updated by the value of (βn0±Δβn) or (βn0-Δβn) so that Eq. 7 approaches zero. Third step, compute Eq. 8 with (αn0±Δαn) by fixed αn1 and βn1, then αp1 can be updated by the value of (αn0+Δαn) or (αn0-Δαn) so that Eq. 8 approaches zero. Thus, one iteration is completed for updating αn1, βn1 and αn1. This process continues until Eq. 6-8 simultaneously approach zero with some error tolerances. The accuracy of the estimation of this method depends on the choice of the step values Δαn, Δβn and Δαp. Therefore, small step value leads to accuracy of the estimation but requires more computing cost.
Iterated method 2: In this section the gradient method for iteration is developed. In the j-th iteration the Taylor series of Eq. 11 is applied to update the parameters αnj, βnj and αpj.
| (11) |
where, θ = (αn, βn, αp)T, grad In L = (∂In L/∂αn, ∂In L/∂βn, ∂In L/∂αp)T and:
 | (12) |
is a Fisher information matrix. The inverse of the Fisher information matrix plays a key role for the iteration of Eq. 11. Given N samples of the observed data, the Fisher matrix can be obtained from Eq. 12. For each iteration, the expected value of the information matrix is calculated with updating parameters αnj, βnj and αpj. The estimation of the parameter is obtained as the value V(θ(j))-1 converge to zero with some error tolerances.
Cramer-Rao lower bound: It is important to understand the unbiasedness of an estimator. The most common way to decide whether or not an estimator’s distribution is unbiased is by looking at its expected value. The Cramer-Rao Lower Bound (CRLB) for the standard deviation of every unbiased estimator is defined as (Hogg and Tanis, 1989):
| (13) |
| (14) |
| (15) |
where, N is the samples of the every realizations and the E[•] is the expected value. Note that Eq. 13-15 are equivalence to the inverse of the square root of the diagonal elements in Eq. 12.
RESULTS AND DISCUSSION
In the following simulation, the digamma function of Eq. 10 is computed using the algorithm in Char et al. (1991) and for further details of the algorithms one can refer to Abramowitz and Stegun (1972). The step value for method 1 is 0.005 and the error tolerance for method 2 is 0.05. All simulation results are based on 50 Monte Carlo runs.
To obtain a good initial value, the tail length and skewness of the observed data are measured and indicated by Q0 (tailness) and Q2 (skewness) (Lee, 2003):
| (16) |
and
| (17) |
where, ![]() are the means of right αR and left αL intervals and m(α) is α-trimmed mean. The Q0 for Gaussian distribution is 2.58 and for Laplace distribution is 3.30, and Q2 is 1 for all symmetric cases. Distributions with Q2>1 have relatively longer right tail (right skewness), while those with 0<Q2<1 have relatively longer left tail (left skewness). By choosing the parameter values (with αn = αp for symmetry and αn ≠ αp for asymmetry), the Q0-Q2 plot (Fig. 3) for various tail length and skewness can be pre-calculated which corresponds to the parameters under the Eq. 1. For example, the values for Gaussian model the (Q0, Q2) is (2.58, 1) and the corresponding (αn, βn, αp) is (2, 1.14, 2). The results shown in Fig. 3 are various Q0-Q2 plots which cover the tailness up to 5.5 and right skewness up to 10. Using the table look-up of Q0-Q2 plots and the corresponding (αn, βn, αp), a reasonable initial value of estimated parameter can be interpolated.
are the means of right αR and left αL intervals and m(α) is α-trimmed mean. The Q0 for Gaussian distribution is 2.58 and for Laplace distribution is 3.30, and Q2 is 1 for all symmetric cases. Distributions with Q2>1 have relatively longer right tail (right skewness), while those with 0<Q2<1 have relatively longer left tail (left skewness). By choosing the parameter values (with αn = αp for symmetry and αn ≠ αp for asymmetry), the Q0-Q2 plot (Fig. 3) for various tail length and skewness can be pre-calculated which corresponds to the parameters under the Eq. 1. For example, the values for Gaussian model the (Q0, Q2) is (2.58, 1) and the corresponding (αn, βn, αp) is (2, 1.14, 2). The results shown in Fig. 3 are various Q0-Q2 plots which cover the tailness up to 5.5 and right skewness up to 10. Using the table look-up of Q0-Q2 plots and the corresponding (αn, βn, αp), a reasonable initial value of estimated parameter can be interpolated.
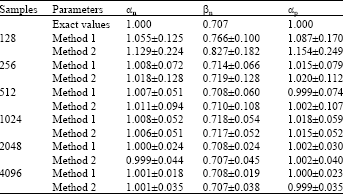
The samples applied in Table 1 are Gaussian distributions, the results shown both iterated methods are reach the exact values of the parameters with low bias. As the sample size increases the standard deviation of the estimation decreases. It appears that the estimation is asymptotically unbiased and satisfies the Cramer-Rao lower bound, where the standard deviations approach but greater than the CRLB (Fig. 4). The results are shown in Table 2 and Fig. 5 are for the samples of Laplace distributions. They are also in agreement with the theoretical values of the parameters.
 | |
| Fig. 3: | The Q0-Q2 plots |
The parameter estimation of extended GGD model include asymmetric distribution is achieved in this study. This differs from the previous study of GGD mode, where more data can be fitted in the proposed model. Furthermore, the pre-calculated table of the Q0-Q2 plots save the computing cost and improve the accuracy of the estimation. The key factor of the iteration method depends on the choice of the initial and step values, in this study a table look-up method is provided for fast and accuracy estimation.
| Table 1: | Gaussian distribution with 50 realizations |
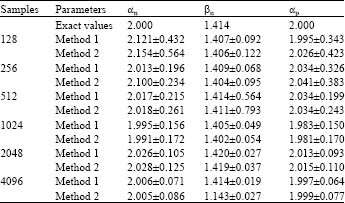 | |
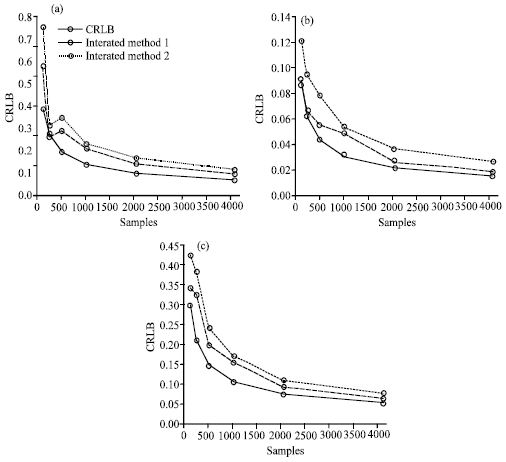 | |
| Fig. 4: | Standard deviation of the estimated parameters of Gaussian samples |
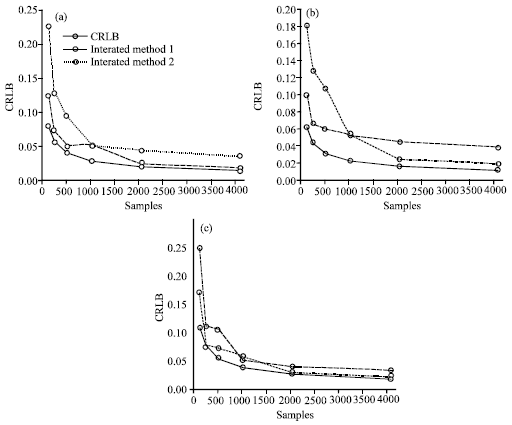 | |
| Fig. 5: | Standard deviation of the estimated parameters of Laplace samples |
| Table 2: | Laplace distribution with 50 realizations |
 | |
CONCLUSION
The maximum likelihood estimator is applied to fit three-parameter probability density function. The results showed that the proposed estimator is asymptotically unbiased for generalized Gaussian family distributions. They are useful for modeling and detecting of the observed data in real-time applications.
ACKNOWLEDGMENT
The author would like to acknowledge the valued comments made by Prof. A.K. Nandi.
REFERENCES
- Gazor S. and W. Zhang, 2003. Speech probability distribution. IEEE Signal Proc. Lett., 10: 204-207.
CrossRef - Fan, S.K. and Y. Lin, 2009. A fast estimation method for the generalized gaussian mixture distribution on complex images. Comput. Vision Image Understand., 113: 839-853.
CrossRef - Lee, J.Y., 2003. Low bias mean estimator for symmetric and asymmetric unimodal distributions. Comput. Method Programs Biomed., 72: 99-107.
CrossRefPubMedDirect Link - Miller, J.H. and J.B. Thomas, 1972. Detectors for discrete-time signals in non-gaussian noise. IEEE Tran. Inform. Theory, 18: 241-250.
Direct Link - Nandi, A.K. and D. Mampel, 1995. An extension of the generalised gaussian distribution to include asymmetry. J. Franklin Inst., 332: 67-75.
CrossRef - Sharifi K. and A. Leon-Garcia, 1995. Estimation of shape parameter for generalised Gaussian distributions in subband decompositions of video. IEEE Trans. Circuits Syst. Video Technol., 5: 52-56.
CrossRef - Soderlind, G., 2006. Time-step selection algorithms: Adaptivity, control and signal processing. Applied Numerical Mathematics, 56: 488-502.
CrossRef - Solihin, Y. and C.G. Leedham, 1999. Integral ratio: A new class of global thresholding techniques for handwriting images. IEEE Trans. Pattern Anal. Mach. Intell., 21: 761-768.
CrossRef - Tlelo-Cuautle, E., J.M. Munoz-Pacheco and J. Martinez-Carballido, 2007. Frequency scaling simulation of Chua's circuit by automatic determination and control of step-size. Applied Mathematics and Computation, 194: 486-491.
CrossRefDirect Link - Walden, A.T., 1985. Non-gaussian reflectivity, entropy and deconvolution. Geophysics, 50: 2862-2888.
CrossRef