
J. Hua
College of Information Engineering, Zhejiang University of Technology, Hangzhou, 310032, China
W. Zhuge
College of Foreign Language, Hangzhou Dianzi University, Hangzhou, China
K. Zhou
College of Information Engineering, Zhejiang University of Technology, Hangzhou, 310032, China
L. Meng
College of Information Engineering, Zhejiang University of Technology, Hangzhou, 310032, China
Information Technology Journal
Year: 2010 | Volume: 9 | Issue: 6 | Page No.: 1226-1230







ABSTRACT
Due to the heavy employment pressure in china, the employment of the undergraduates attracts much attention in recent years. Accordingly, this study proposes a SPSS-based statistical method to study the employment issue, where thirteen parameters are carefully chosen to construct the employment database. The proposed method first performs the quantitative and the standardized operations and then calculates the correlated matrix of parameters. Moreover, after proving that the correlated matrix satisfies Kaiser-Meyer-Olkin (KMO) condition, we perform eigenvalue decomposition and compute the variance contribution rate through Principal Component Analysis (PCA) techniques. Both the eigenvalue and the variance contribution rate are used to study the importance of each parameter and finally lead to an importance sort. Therefore, we can quantificationally study the influence of each parameter thrown on the undergraduate employment and find three most important parameters affecting undergraduate employment: university, major and family location.
PDF Abstract XML References Citation
Received: January 09, 2010;
Accepted: April 20, 2010;
Published: June 23, 2010
How to cite this article
J. Hua, W. Zhuge, K. Zhou and L. Meng, 2010. Statistical Study on Principal Factors Affecting Employment of Chinese Undergraduates. Information Technology Journal, 9: 1226-1230.
DOI: 10.3923/itj.2010.1226.1230
URL: https://scialert.net/abstract/?doi=itj.2010.1226.1230
DOI: 10.3923/itj.2010.1226.1230
URL: https://scialert.net/abstract/?doi=itj.2010.1226.1230
INTRODUCTION
Recently, the number of Chinese undergraduate grows significantly, with 1.15 million in 2001, 3.30 million in 2003 and 5.59 million in 2009, which burdens the employment market. According to conservative estimation, employing ratio of 70% produces about 1.68 million unemployed undergraduates in 2009 (Wang et al., 2009; Dong and Yig, 2009; Rong et al., 2009). Moreover, the number of unemployed undergraduates may increase rapidly in the future, which will cause many social problems (Wang, 2007; Lin, 2008).
Chinese scientists had tried to find out some factors affecting employment and then instruct the job-hunting of undergraduates. However, till now there are no authoritative conclusions about these factors. In fact, conventional studies usually concern the data collection and the qualitative research (Gu, 2008), which is simple but cannot deal with complicated datas. In order to account for this problem, people should exploit mathematical tool to analyze the intricate employment data, such as Principal Component Analysis (PCA) (Blanchard et al., 2007).
As a popular tool in mathematical analysis, PCA is widely used in statistical study, such as medical signal processing (Castells et al., 2007; Lathauwer et al., 2000), working efficiency evaluation (Hu et al., 2007), biologic data analysis (Reich et al., 2008), soil analysis (Kooch et al., 2008) and machine learning (Hung and Liao, 2008) (Chinnasarn et al., 2006). However, no one had applied PCA to analyze the employment issues. Hence, we choose PCA as mathematic tool in this study. Moreover, the PCA tools have been integrated into SPSS software (Field, 2009; Miller and Acton, 2009), thus, our investigations will done in SPSS environments. Accordingly, this paper collects some samples about employment and then analyzes the influence of the possible factors affecting undergraduate employment by SPSS.
In this study, we choose thirteen indexes (factors): university, major, family location, academic degree, employer, political status, gender, residence classification, position, related experience, attitude toward employment, additional skill and approach for employment and our mission is to find which index is the most important factor affecting undergraduate employments. To realize this aim, we first perform the parameterization operation to the indexes to obtain the standardized numbers, which we call parameters now. Then, we calculate their correlation matrix and the corresponding eigenvalue. Moreover, variance contribution rates for these parameters are derived in SPSS and both eigenvalue and variance contribution rates are utilized as indicators of importance. Finally, with the help of importance information, we sort the thirteen indexes and find three most important indexes: university, major and family location.
| Table 1: | Index example (partial) |
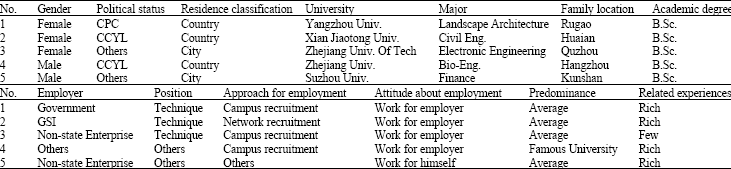 | |
| CCYL: Chinese Communist Youth League, CPC: Chinese Communist Party, GSI: Government Sponsored Institution | |
| Table 2: | Employment rate (partial) |
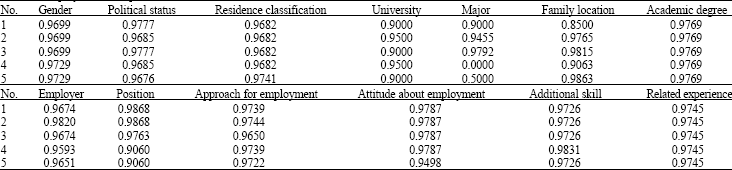 | |
PARAMETERIZATION PROCESS
The choice of indexes: Generally, there are three groups of factors influencing the employment of undergraduates: those related to individuals themselves, schools and the society. Taking all of the above into consideration, we pick up the 13 indexes mentioned in previous section. These indexes are: the employment rate of undergraduates with different genders (A1); the employment rate of undergraduates with different political status (A2); the employment rate of undergraduates with different residence classification (A3); the employment rate of undergraduates from different universities (A4); the employment rate of undergraduates with different majors (A5); the employment rate of undergraduates with different family location (A6); the employment rate of undergraduates with different academic degrees (A7); the employment rate of undergraduates with different employers (A8); the employment rate of undergraduates with different positions (A9); the employment rate of undergraduates with different approaches to the job (A10); the employment rate of undergraduates with different attitudes (A11); the employment rate of undergraduates with different additional superiority (A12); and the employment rate of undergraduates with different trainee experience (A13). With these indexes, we can extract data from database and build a sample database, which is composed of more than one thousand records. Hence, due to the limitation of space, we just give five records in Table 1 as examples. From Table 1, we explicitly see that each index (Ai) must take value from a certain finite alphabet and each possible value in such a alphabet is used for classification criterion of groups.
Parameterization of index: Each index can be parameterized as:
| (1) |
where, Bij, Cij and Sij represent the number of the undergraduates who have found a job, the total number of undergraduates and the employment rate of Group j in sample Ai respectively. By Eq. 1, Table 1 can modified as Table 2. For example, we take into account the Gender index, i.e., A1 index. There are two possible values for this index: male or female, which means that there are two groups for A1 index. Then we have:
| • | C11: number of the female undergraduate |
| • | C12: number of the male undergraduate |
| • | B11: number of the female undergraduate who have found a job |
| • | B12: number of the male undergraduate who have found a job |
Finally, we can calculate employment rates (S11, S12), i.e., 0.9669 for female and 0.9729 for male, which means that a man is easier to find a job than a woman.
PCA PROCESS
Based on the data matrix above, we can perform PCA operation in SPSS and get test result of KMO and Bartletts (Fig. 1).
 | (2) |
KMO stands for Kaiser-Meyer-Olkin measure of sampling adequacy (Field, 2009). A larger KMO means more common factors among variables, thus more suitable to perform PCA operation. According to Kaiser (Miller and Acton, 2009), if KMO falls below 0.5, its not suitable to do PCA. Here, with a KMO valuing 0.594, we can perform the operation. The correlation matrix can be represented in formula 2.
From matrix R, we can see that there is high correlation between A4 and A5, followed by that between A4 and A6. A5 also correlates with A6, so do A7 and A8. We cannot find such high correlation between other indexes. In fact, this is indeed the case.
We execute the variance analysis by SPSS and obtain Fig. 2, where the eigenvalue of correlation matrix (descending order), the contribution rate of variance as well as the Cumulative contribution rate of variance are shown in the left three columns. Moreover, in order to further study the variance variation, we extract the eigenvalue of correlation matrix, the contribution rate of variance and the Cumulative contribution rate of variance to construct Table 3, where Gi denotes the ith component.
According to Table 3, there are two ways to count the number of principle components. The first is to include all those quartiles with its eigenvalue larger than one. The second is to judge by their cumulative contribution rates. Here we adopt the first method, thus G1~G5 become the quartiles, which are, actually,synthetic indexes transformed from the original indexes. Generally, the value of first quartile can be used as the synthetic criteria to judge whether the scheme is good or not, while those of second and other quartiles represent other features waiting to be evaluated and can even serve as supplements when the contribution rate of the first quartiles cannot represent the information of the original index system.
For the convenience of explanation, we use SPSS to obtain the rotated component matrix and the corresponding variance contribution rate in Fig. 3 and 4.
 | |
| Fig. 1: | The test result of KMO and bartlett |
| Table 3: | Variance analysis table |
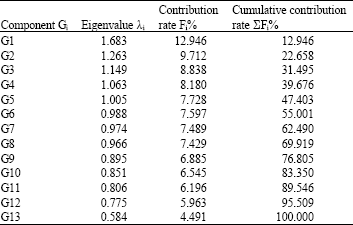 | |
From Fig. 3 and 4, we can see that A4, A5 and A6 compose the first quartile; A7, A8 and A2 are the second quartile; A1, A3 and A9 form the third quartile; A13 and A11make the fourth quartile and A12 and A10 are the fifth quartile. We can also define the major factor as A4, A5 andA6 and rank the thirteen parameters according to their importance as: A4, A5, A6, A7, A8, A2, A1, A3, A9, A13, A11, A12 and A10. That is to say, what affect the employment most are university, major and family location. And University influences undergrads employment most, with major, family location, academic degree, employer, political status, gender, residence classification, position, related experience, attitude toward employment, additional superiority and approach for employment following it.
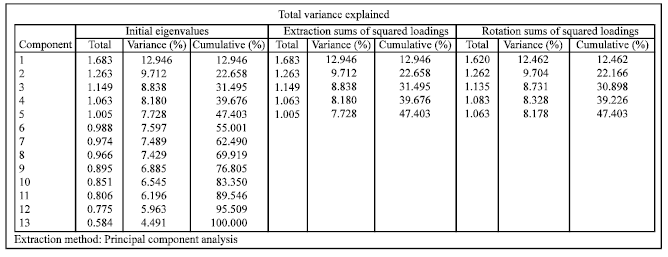 | |
| Fig. 2: | Variance analysis results |
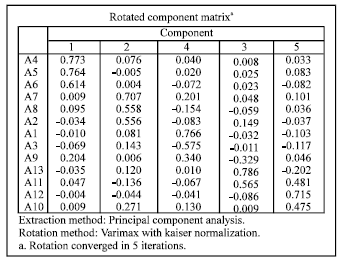 | |
| Fig. 3: | The rotated component matrix |
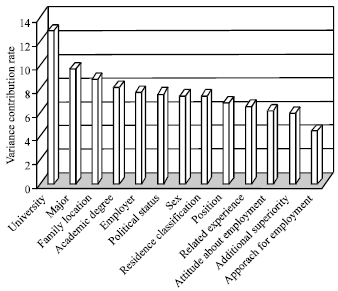 | |
| Fig. 4: | Variance contribution rate |
CONCLUSIONS
This study uses PCA to analyze thirteen indexes affecting employment, where we order them according to eigenvalues and contribution rates and find three most important indexes. The result contributes to employment studies and benefits certain decision making departments.
ACKNOWLEDGMENT
This study is sponsored by science foundation for the excellent youth scholars of Zhejiang province (2010) and Zhejiang provincial NSF of China under grant No.Y1090645 (2010-2011).
REFERENCES
- Blanchard, G., O. Bousquet and L. Zwald, 2007. Statistical properties of kernel principal component analysis. Machine Learning, 66: 259-294.
CrossRefDirect Link - Castells, F., P. Laguna, L. Sornmo, A. Bollmann and J. Roig, 2007. Principal component analysis in ECG signal processing. EURASIP J. Applied Signal Process., 2007: 98-98.
CrossRefDirect Link - Chinnasarn, K., S. Chinnasarn and D.L. Pyle, 2006. Identification of surimi gel strength classes using backpropagation neural network and principal component analysis. J. Applied Sci., 6: 1802-1807.
CrossRefDirect Link - Hung, Y.H. and Y.S. Liao, 2008. Applying PCA and fixed size LS-SVM method for large scale classification problems. Inform. Technol. J., 7: 890-896.
CrossRefDirect Link - Kooch, Y., H. Jalilvand, M.A. Bahmanyar and M.R. Pormajidian, 2008. The use of principal component analysis in studying physical, chemical and biological soil properties in Southern Caspian forests (North of Iran). Pak. J. Biol. Sci., 11: 366-372.
CrossRefPubMedDirect Link - Lathauwer, L., B. Moor and J. Vandewalle, 2000. SVD-based methodologies for fetal electrocardiogram extraction. Proc. Acoustics Speech Signal Process. 2000 IEEE Int. Conf., 6: 3771-3774.
CrossRefDirect Link - Lin, Z., 2008. The coutermeasure on employment of the graduates from the local normal colleges. J. Zhangzhou Normal Univ. (Philoso. Social Sci.), 3: 155-157.
Direct Link - Reich, D., A.L. Price and N. Patterson, 2008. Principal component analysis of genetic data. Nat. Genet., 40: 491-492.
CrossRefDirect Link