
Z. Razak
Faculty of Computer Science and Information Technology, University of Malaya, Kuala Lumpur, Malaysia
N.A. Ghani
Faculty of Computer Science and Information Technology, University of Malaya, Kuala Lumpur, Malaysia
E.M. Tamil
Faculty of Computer Science and Information Technology, University of Malaya, Kuala Lumpur, Malaysia
M.Y.I. Idris
Faculty of Computer Science and Information Technology, University of Malaya, Kuala Lumpur, Malaysia
N.M. Noor
Faculty of Computer Science and Information Technology, University of Malaya, Kuala Lumpur, Malaysia
R. Salleh
Faculty of Computer Science and Information Technology, University of Malaya, Kuala Lumpur, Malaysia
M. Yaacob
Faculty of Computer Science and Information Technology, University of Malaya, Kuala Lumpur, Malaysia
M. Yakub
Department of Al-Quran and Al-Hadith, Academy of Islamic Studies, University of Malaya, Kuala Lumpur, Malaysia
Z.B.M. Yusoff
Department of Al-Quran and Al-Hadith, Academy of Islamic Studies, University of Malaya, Kuala Lumpur, Malaysia
Information Technology Journal
Year: 2009 | Volume: 8 | Issue: 7 | Page No.: 971-981







ABSTRACT
This study is focusing on off-line character recognition. The algorithm of pre-processing such as line and character segmentation is studied and determined so that the design can give a good result and can be implemented in hardware. A process of transformation towards the characters is done using discrete wavelet transform since, it will show the details of the pixels. After that, a process to generate a sequence of binary that using a value of threshold (threshold value is determine by experiment) is done so that it can be use for recognition process. This sequence of binary will be classified using Hamming distance which can trace bit changes in the two sequence of binary and the bit value distinction will be used to recognize the character.
PDF Abstract XML References Citation
How to cite this article
Z. Razak, N.A. Ghani, E.M. Tamil, M.Y.I. Idris, N.M. Noor, R. Salleh, M. Yaacob, M. Yakub and Z.B.M. Yusoff, 2009. Off-Line Jawi Handwriting Recognition using Hamming Classification. Information Technology Journal, 8: 971-981.
DOI: 10.3923/itj.2009.971.981
URL: https://scialert.net/abstract/?doi=itj.2009.971.981
DOI: 10.3923/itj.2009.971.981
URL: https://scialert.net/abstract/?doi=itj.2009.971.981
INTRODUCTION
Character recognition is a process that identifies non-digital characters from printed scripts and interprets the collections of the character shapes in a digital format. Jawi script contains 36 characters that can be classified into two categories: grouped form and individual form. Every Jawi character also has three different shape based on their position in a connected Jawi word which are at the beginning, middle or at the end of the word. The character recognition research will be put more emphasis on the writing styles, since there are some of the Jawi characters have similar shapes at the middle and end of the word.
The widely usage of Jawi scripts in inscription, religion text about Islam, petition, newspaper and magazine has encourage this research to be conducted. This research will create a system that efficient, cheap, flexible and user friendly which can promote usage to retrieve, process and store Jawi manuscripts on computers that will facilitate the use of Jawi scripts in office automation and administration by shy Jawi literate IT users. The digitized Jawi scripts can also assist historians in studying old Jawi manuscripts and preserve their content for future research. Without the aid of information technology and full-fledge Jawi digitized system, the content of these old and yet invaluable manuscripts may be lost forever for the current IT literate generation. This study will present our approach by using Hamming distance classifier for off-line handwritten Jawi character recognition.
LINE AND CHARACTER SEGMENTATION
Segmentation process is to simplify or to change the representation of an image so that it can be easily analyze. It is typically used to locate objects and boundaries such as lines and curves in images. Line segmentation is important in analyzing the arrangement and separates the upper and lower lines, while character segmentation is the task of separating the words into its component characters. This two process should be done accurately to prevent any dissemination of rectification to others process such as in feature extraction.
Line segmentation: In present research (Zaidi et al., 2007), old manuscripts (with many overlapped characters over the lines) is considered as the domain problem and it require planning and designing of a very accurate method in the first stage of segmentation i.e., line segmentation. There is no artificial intelligence is used in analysis since it can hardly be implemented in hardware or morphological tracing as has been used by Ymin and Aoki (1996), neither using the calculation of pixel averages as done by Cheung et al. (1997) and Amin (1991). Instead, this study uses histogram projection without taking into consideration of the character orientation and line skew. The false local minimum SP is omitted when normalization of the histogram is performed and this algorithm can improve accuracy and speed, while maintaining the quality of the segmented text lines. The full result of this process is shown in Fig. 1-5.
Louloudis et al. (2006) presented a text line detection technique for off-line unconstrained handwriting based on a three step strategy. The first step includes for image enhancing pre-processing, connected component extraction and average character height estimation. In the second step, a block-based Hough transform is applied for potential text lines detection while a third step is applied to correct possible false detections. The performance of the proposed strategy is based on an evaluation technique that compares the text line detection result and the corresponding ground truth annotation.
 | |
| Fig. 1: | Old Jawi manuscript with size 1277x774 pixels |
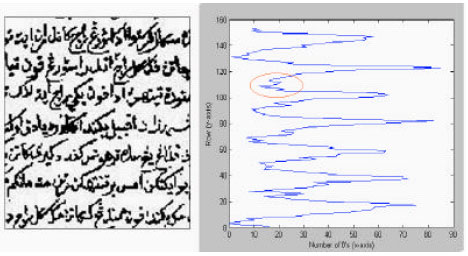 | |
| Fig. 2: | (a) Binary image of ROI of Old manuscript and (b) Graph row versus no of 0’s |
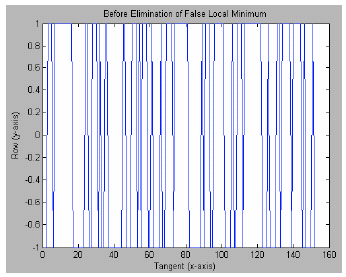 | |
| Fig. 3: | New representation of tangent versus row (before elimination of false local minimum) |
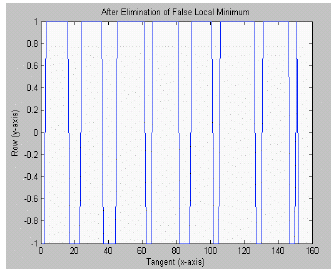 | |
| Fig. 4: | Tangent versus row (after elimination of false local minimum) |
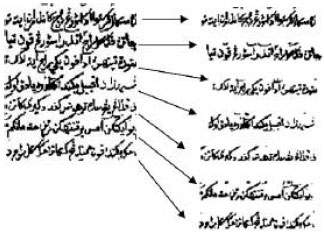 | |
| Fig. 5: | Result of line segmentation |
The method proposed by Likforman-Sulem et al. (1995) detected text lines on handwritten documents which may include either lines oriented in various directions, erasures, or annotations between main lines. The method consists of a hypothesis-validation strategy which is iteratively activated until the segmentation is completed. At each stage of the process, the best text-line hypothesis is generated in the Hough domain, considering the fluctuations of the text-line components. Then, the validity of the line is checked in the image domain using proximity criteria which analysis the context which is perceived as the alignment hypothesis. Ambiguous components belonging to several text lines are also marked.
Character segmentation: For character segmentation, it will be much more challenging, since handwritten Jawi text has cursive nature and various writing styles. For this study, histogram normalization and sliding windows is re used for character segmentation process.
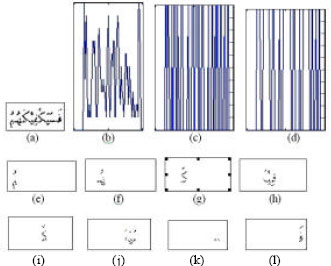 | |
| Fig. 6: | Character segmentation results |
This method has been used in many several of character recognition system to segment the words and character by horizontal or vertical (Casey and Lecolinent, 1996). The vertical projection histogram will segment the document vertically. It can detect the space between each character and also can specify the location of the vertical strokes in printed documents or any region of various line of handwriting.
Gouda and Rashwan (2004) segmented the word to many basic characters based on the baseline using vertical histogram. In Al-Youseffi and Udpa (1992), the character is segmented by horizontal and vertical projection histogram into primary and secondary parts, while Syiam et al. (2006) implemented a clustering technique (k-means algorithm) on the vertical histogram. This improved the performance of histogram technique with recognition of handwritten characters. The character is clustered to identify the similarities of the characters. By using this algorithm, the design will be simple and enables it to be implemented in hardware without requiring a large amount of resources. Below is the sample of character segmentation result. A pre-processing such as edge detection or contour tracing is not performed since 100% accuracy is not crucial in our approach.
The text line height is assumed as the sliding window width. In the histogram, the pixel counts where the negative sign gradients meet the positive sign gradients zare set as the character segmentation points (Fig. 6). If the length between neighboring segmentation points is less than the sliding window width then the particular segmentation points are used for segmentation. Otherwise, if the length between neighboring segmentation points is more than the sliding window width then the sliding window length is used for segmentation.
FEATURES EXTRACTION
The process of transformation using Discrete Wavelet Transform (DWT) is a process that using the pyramid algorithm which develops by Mallat (1989) for decomposition process of various efficiency resolutions. This decomposition process will be operating on signal (in this research it will be value of pixel) and it can also be applied to image processing.
A system for recognition of handwritten Farsi/Arabic characters and numerals was developed by Mowlaei et al. (2002). The discrete wavelet transform is utilized to produce wavelet coefficients, which are used for classification. Haar wavelet is used for feature extraction in Farsi/Arabic handwritten postal addresses containing the names and postal codes of cities from a database of 579 postal addresses in Iran.
Discrete Wavelet Transform (DWT) is chosen because it can provide the information that can describe the position of pixel and also the density of pixel in character representation which has been segmented (Zaidi et al., 2005). It also can synthesize pixels to DWT coefficient in short time. By using the Mallat algorithm (Mallat, 1999), DWT can decomposed sub band which signal (value of pixel) is divided into component with high frequency but low resolution. The locality of this frequency and structure of various resolutions is one of the DWT main traits which make it suitable for image compression and to get the best representation to represent the sowing of character pixel that will be process.
Unique code extraction process: The unique code is obtained by scanning rows and columns of DWT coefficient which represent a Jawi character. This scanning is done by using an Eq. 1 as shown below:
| (1) |
where, R is the unique code, b is row, l is column, k is DWT coefficient and t is the value of threshold.
If the threshold value is exceeded, then the value is set to one. Otherwise, it will be set to zero. Twenty two bit strings of values one or zero for both rows and columns will be obtained. Then, both of the 22 bit string will be combined to get 44 bit string of value which is now known as unique code of the character. From here, the Hamming distance will be calculated to get the reference value for the letter Alif.
There are two important matter that need to be consider in determine the value of threshold which is duplicate and class. Duplicate in this term meaning that the unique code which has been produced by using the threshold is similar to other character’s unique code while class means every character will be divided into their classes according to its shape. For an example, character ba ![]() , ta
, ta ![]() and tha
and tha ![]() are in the same class since they have a similar shape and can only be differentiate by the position of the dots. So, if the value of threshold causing a duplication of unique code and they are not from the same class then the value of threshold will be neglected. This process will continue until one value of threshold did make any duplication and if there are any duplication the character should be in the same class (Fig. 7).
are in the same class since they have a similar shape and can only be differentiate by the position of the dots. So, if the value of threshold causing a duplication of unique code and they are not from the same class then the value of threshold will be neglected. This process will continue until one value of threshold did make any duplication and if there are any duplication the character should be in the same class (Fig. 7).
The list of unique code for each character after the threshold is shown in Table 1-4.
| Table 1: | List of unique code for isolated character |
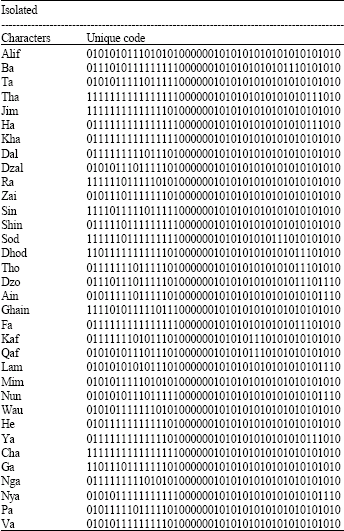 | |
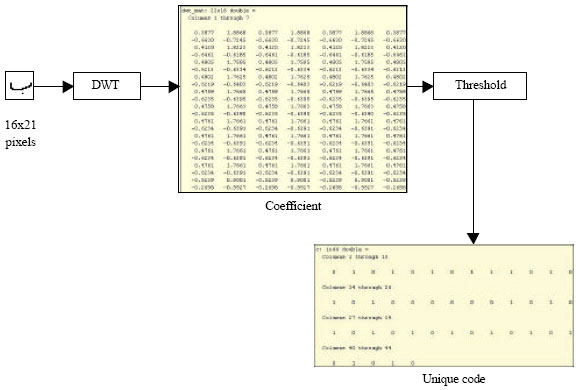 | |
| Fig. 7: | The summary of feature extraction and threshold process |
| Table 2: | List of unique code for character at the beginning of word |
 | |
| Table 3: | List of unique code for character at the middle of word |
 | |
| Table 4: | List of unique code for character at the end of word |
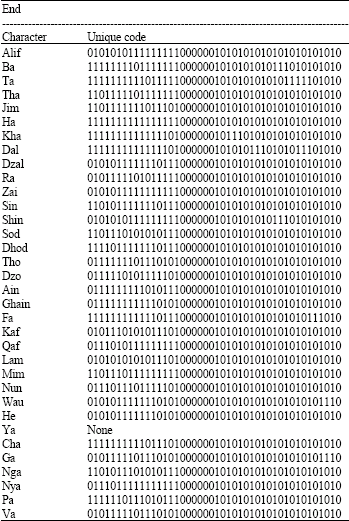 | |
CLASSIFICATION
The Hamming distance gives a measure of how many bits are different between two bit patterns. Using the Hamming distance of two bit patterns, a decision can be made as to whether the two patterns were generated from different Jawi characters or from the same one. For binary strings a and b the Hamming distance is equivalent to the number of ones in a xor b.
In comparing the bit patterns X and Y, the Hamming distance, HD, is defined as the sum of disagreeing bits (sum of the exclusive-OR between X and Y) over N, the total number of bits in the bit pattern.
| (2) |
The most favored distance measure for binary features is the Hamming distance. To further improve the performance, there are two approaches. First, weights can be applied to features (Yoon et al., 2005) and optimized using techniques such as genetic algorithms (Guoxing et al., 1998; Pouliquen et al., 1997). Another approach is to use a similarity measure that gives full credit to features present in both patterns, less credit to those not present in either pattern and no credit to those present in only one of the patterns to be matched (Guoxing et al., 1998). Both approaches have been reported to perform better than the simple Hamming distance approach. Yoon et al. (2005) produced a new measure that combines these two approaches where experimental results demonstrate its superiority over the other measures.
A compact smart current mode Hamming neural network for classifying complex patterns such as totally unconstrained handwritten digits. It is based on multi-threshold template matching, multi-stage matching and k-WTA (k-Winner-Takes-All), some different from general Hamming neural network. The neural classifier consists of two kinds of templates: one is binary template and another is multi-value programmable templates, each of them has its own threshold and realized in MOS current mirrors, the current mode k-WTA which is reconfigurable is put forward. The second stage matching templates are programmable from outside of the chip. This mixed analog-digital Hamming neural classifier can be fabricated in a standard digital CMOS technology.
Pouliquen et al. (1997) used the basic building blocks to design an associative processor for bit-pattern classification; a high-density memory based neuromorphic processor. Operating in parallel, the single chip system determines the closest match, based on the Hamming distance, between an input bit pattern and multiple stored bit templates; ties are broken arbitrarily.
Hamming distance algorithm applied for matching Jawi characters:
| • | For each pair of identity matrices A and B |
| • | For each matrix position |
If the matrix value in identity matrix A does not match the matrix value in identity matrix B increment the distance between identity matrices A and B by 1.
SYSTEM ARCHITECTURE
From the Fig. 8, we can see that there is one main controller that controls all the activities. The activity or process begins with data entry which the image will be scanned line by line and stored into a temporary memory. Next, line segmentation process will begin as shown above. The entity which is line segmenter will calculated the histogram projection whether it fulfill the conditions of line segmentation or not. After line segmentation process is succeeded, it will activate the word segmentation process.
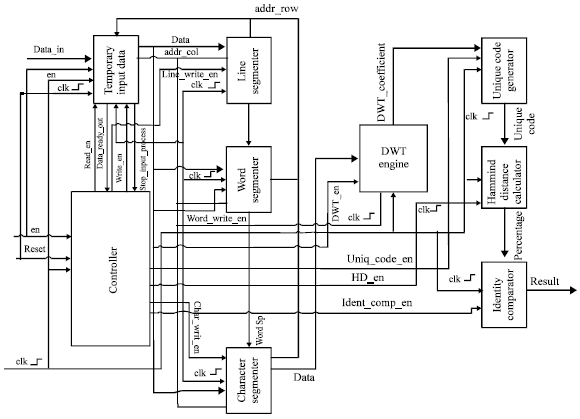 | |
| Fig. 8: | Combination all entities for jawi character recognition tool |
This entity is responsible for calculating the dots to segment the word. The first word which has been segmented will activated the character segmentation process. The character segmenter as shown in Fig. 8 will make a projection histogram for a character and this process will operate together with line and word segmentation process.
After the character has been segmented, the DWT engine will transform the character into wavelet coefficients and then the unique code generator will using the coefficients to produce the unique code by changing or normalized the coefficient so that comparison can be done correctly. Lastly, the unique code will be matched using Hamming distance algorithm and it will generate the Unicode for that character.
EXPERIMENTAL RESULT
Table 5 is the result of Hamming distance for all the isolated Jawi character. From Table 5, the lowest percentage is for character mim, ![]() which is 2.2727% and the value of HD is one.
which is 2.2727% and the value of HD is one.
Table 6 is the result of Hamming Distance and its difference percentage for character at begin of word. The lowest percentage is for character tha ![]() with Hamming distance equal to one.
with Hamming distance equal to one.
| Table 5: | Difference percentage of isolated Jawi character against character alif |
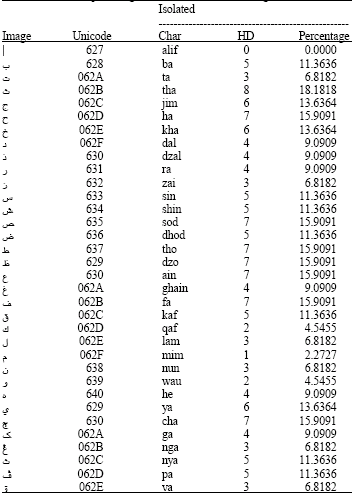 | |
| Table 6: | Difference percentage of Jawi character at begin of word |
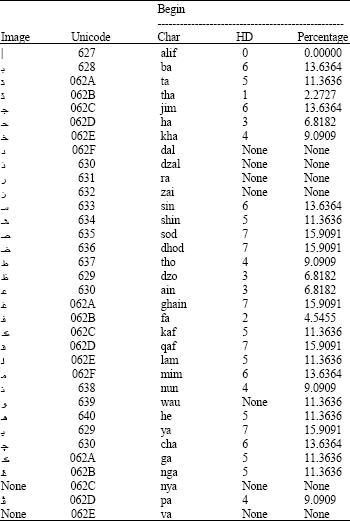 | |
| Table 7: | Difference percentage of Jawi character at middle of word |
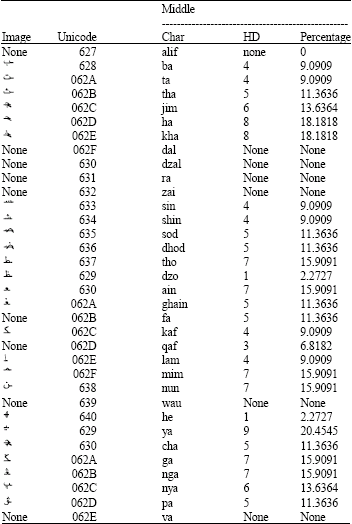 | |
| Table 8: | Difference percentage of Jawi character at end of word |
 | |
Table 7 shows the result for character at middle of word. The lowest percentage for Table 8 is dzo ![]() and he
and he ![]() with both has the same percentage which is 2.27%.
with both has the same percentage which is 2.27%.
Lastly, Table 8 shows the result for Jawi character at end of words. Three characters which is alif ![]() dzal
dzal ![]() and kaf
and kaf ![]() has the lowest percentage which is 6.82% with three Hamming Distanc.
has the lowest percentage which is 6.82% with three Hamming Distanc.
Table 9 shows the example result of classification using Hamming Distance after the character segmentation process as shown in Fig. 9a-f.
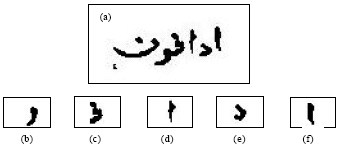 | |
| Fig. 9: | (a) Image before segmentation process and (b-f) image after character segmentation process |
| Table 9: | Result of hamming distance and its percentage of error for image in Fig. 9 |
 | |
| Table 10: | Benchmarking result for Jawi character recognition |
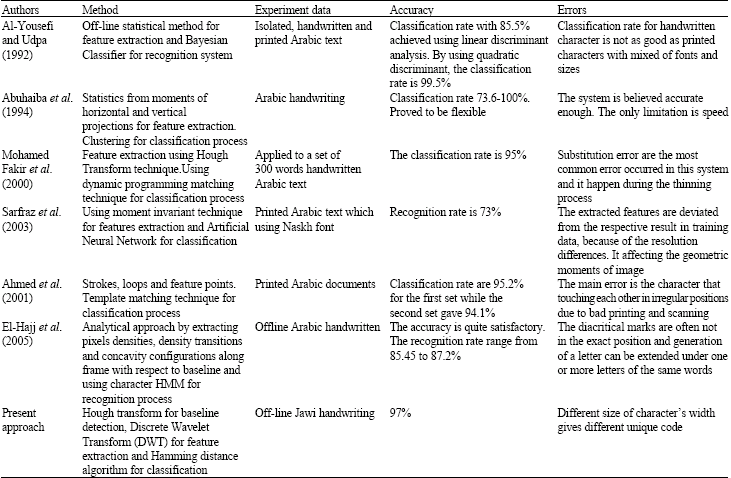 | |
BENCHMARKING RESULT
Benchmarking result for Jawi character recognition are compared with earlier data as shown in Table 10.
CONCLUSION AND FUTURE WORK
A system using histogram projection for line segmentation, histogram normalization for character segmentation, Discrete Wavelet Transform (DWT) for feature extraction and Hamming distance algorithm for classification of Jawi characters has been presented in this study. Different width of character could effecting the result and process of fitting the character to same width need to be done to overcome this problem.
REFERENCES
- Gouda, A.M. and M.A. Rashwan, 2004. Segmentation of connected arabic character using hidden markov models. Procedings of the International Conference of Computational Intelligent for Measurement Systemsand Applications, July 14-16, 2004, USA., pp: 115-119.
CrossRefDirect Link - Ahmed, M. and A. Elgammal Mohamed Ismail, 2001. A graph-based segmentation and feature extraction framework for arabic text. Proceedings of the 6th International Conference on Document Analysis and Recognition, September 10-13, 2001, IEEE Computer Society, Washington, DC., USA., pp: 622-626.
Direct Link - Louloudis, G., K. Halatsis, B. Gatos and I. Pratikakis, 2006. A block-based hough transform mapping for text line detection in handwritten documents. Proceedings of the 10th International Workshop on Frontiers in Handwriting Recognition, October 23-26, 2006,, La Baule, France, pp: 515-520.
Direct Link - Al-Yousefi, H. and S.S. Udpa, 1992. Recognition of arabic characters. IEEE Trans. Pattern Anal. Mach. Intell., 14: 853-857.
CrossRefDirect Link - Likforman-Sulem, L., A. Hanimyan and C. Faure, 1995. A hough based algorithm for extracting text lines in handwritten documents. Proceedings of the 3rd International Conference on Document Analysis and Recognition, August 14-15, 1995, USA., pp: 774-774.
CrossRefDirect Link - Guoxing, L., S. Bingxue and L. Wei, 1998. A modified current mode hamming neural network for totally unconstrained handwritten numeral recognition. Proceedings of the 1998 International Joint Conference on Neural Networks, May 4-9, 1998, USA., pp: 1857-1860.
CrossRefDirect Link - Abuhaiba, I.S.I., S.A. Mahmoud and R.J. Green, 1994. Recognition of handwritten cursive arabic characters. IEEE Trans. Patt. Anal. Mach. Intell., 16: 664-672.
CrossRefDirect Link - Mohamed Fakir, M., M. Hassani and S. Chuichi, 2000. On the recognition of arabic characters using hough transform technique. Malaysian J. Comput. Sci., 13: 39-47.
Direct Link - Mowlaei, A., K. Faez and A.T. Haghighat, 2002. Feature extraction with wavelet transform for recognition of isolated handwritten farsi/arabic characters and numerals. Proceedings of the 14th International Conference on Digital Signal Processing, July 1-3, 2002, USA., pp: 923-926.
CrossRefDirect Link - Sarfraz, M., S. Nazim and A. Al-Khuraidly, 2003. Offline Arabic text recognition system. Proceeding of International Conference on Geometric Modeling and Graphics, July 16-18, 2003, IEEE Computer Society, pp: 30-35.
Direct Link - Pouliquen, P.O., A.G. Andreou and K. Strohbehn, 1997. Winner-takes-all associative memory: A hamming distance vector quantizer. J. Analog Integrat. Circ. Signal Process., 13: 211-222.
Direct Link - Zaidi, R., S. Rosli and Y. Mashkuri, 2005. Hardware design of on-line jawi character recognition chip using discrete wavelet transform. Proceedings of the 8th International Conference on Document Analysis and Recognition, August 29-September 1, 2005, IEEE Computer Society, Seoul, Korea, pp: 91-95.
Direct Link - El-Hajj, R., L. Likforman-Sulem and C. Mokbel, 2005. Arabic handwriting recognition using baseline dependant features and hidden markov modeling. Proceedings of the International Conference Document Analysis and Recognition, August 31-September 1, 2005, IEEE Computer Society, Washington, DC., USA., pp: 893-897.
CrossRefDirect Link - Yoon, S., S. Cha and C.C. Tappert, 2005. On binary similarity measures for handwritten character recognition. Proceedings of the 8th International Conference on Document Analysis and Recognition, August 29-September 1, 2005, Seoul, Korea, pp: 4-8.
CrossRefDirect Link - Syiam, M., T.M. Nazmy, A.E. Fahmy, H. Fathi and K. Ali, 2006. Histogram clustering and hybrid classifier for handwritten Arabic characters recognition. Proceedings of the 24th IASTED International Conference on Signal Processing, Pattern Recognition and Applications, February 15-17, 2006, Innsbruck, Austria, pp: 44-49.
Direct Link - Zaidi, R., Z. Khanza, S. Rosli, Y. Mashkuri and M. Emran Tamil, 2007. A real-time line segmentation algorithm for an offline overlapped handwritten jawi character recognition chip. Malaysian J. Comput. Sci., 20: 69-80.
Direct Link - Mallat, S.G., 1989. A theory for multiresolution signal decomposition: The wavelet representation. IEEE Trans. Pattern Anal. Mach. Intell., 11: 674-693.
CrossRefDirect Link