
Tinghuai Ma
School of Computer and Software, Nanjing University of Information Science and Technology, China
Jiazhao Leng
School of Computer and Software, Nanjing University of Information Science and Technology, China
Mengmeng Cui
School of Computer and Software, Nanjing University of Information Science and Technology, China
Wei Tian
School of Computer and Software, Nanjing University of Information Science and Technology, China
Information Technology Journal
Year: 2009 | Volume: 8 | Issue: 7 | Page No.: 1039-1043







ABSTRACT
Traditional classification rules take the positive form as C→D. A new method of retrieving the negative ¬C→5D form is introduced in this paper. Negative rules can improve the classification quality in some case. We propose a classification algorithm named Rule Generation based on Classification Attribute (RGCA) to deduct negative and positive rules. The RGCA algorithm won’t need processing records item by item. The real dataset are used to verify the presented algorithm. The result shows the negative rules is more than positive rules based on RGCA algorithm, the classification accuracy of RGCA algorithm is better than traditional positive based algorithm.
PDF Abstract XML References Citation
How to cite this article
Tinghuai Ma, Jiazhao Leng, Mengmeng Cui and Wei Tian, 2009. Inducing Positive and Negative Rules Based on Rough Set. Information Technology Journal, 8: 1039-1043.
DOI: 10.3923/itj.2009.1039.1043
URL: https://scialert.net/abstract/?doi=itj.2009.1039.1043
DOI: 10.3923/itj.2009.1039.1043
URL: https://scialert.net/abstract/?doi=itj.2009.1039.1043
INTRODUCTION
Classification is one of the most important techniques for data mining and machine learning. There are two factors, accuracy and efficiency, needing to be carefully considered. For example, it’s very difficult to improve calculation efficiency due to high data dimension. The core of classification algorithm is to select the right attribute, which is used to find the least subset of condition attribute without violating the accuracy requirement. The rule with least condition attribute pairs, it only needs to match less condition attribute and thus improve the match efficiency, while a new case is classified.
Increasing classification’s precision is the target of algorithm. Effective and efficient are very important for data mining. Classification was formerly improved by designing different algorithms to obtain rules in the form of C→D. But this form as rules couldn’t improve classification accuracy sharply because it is not easy to improve the matured algorithms. New rules in the form of ¬C→5D are introduced into data mining. Wu et al. (2004) discussed how to use negative association rule and designed constraints to reduce the search space. Ji and Tan (2004) studied how to inducing negative and positive rules for gene expression, which is also based on association rules. Tsumoto (2001) used positive and negative rules to predict clinical case, which is based on rough set.
As a new technique of data mining, the rough set has been thought as a suitable method for attribute reduction (Pawlak and Skowron, 2007). It is a new mathematical method to deal with vague and uncertain knowledge. It provides a satisfied way to deal with classification based on mathematics (Pawlak and Skowron, 2007; Hu et al., 2006). Nowadays, there are many rough set applications, such as process control, KDD (data mining), pattern recognition, classification, medical reasoning and fault diagnosis (Hu et al., 2006). With rough set, rules can be described as either positive or negative Tsumoto (2001). It can remedy the low accuracy caused by the singleness of positive rules reasoning.
To obtain rules based on rough set, records are processed item-by-item. For the rule reduction that based on classification attribute, it does not need to deal with records one by one so that to improve calculation efficiency. Negative rules can be generated along with positive rules. It can improve the classification accuracy. Sometimes, reasoning can be done based on negative rules and it reduces the classification time.
BASIC CONCEPTS
The classic knowledge system can be represented as: S = <U, C, D, V, f>. The complete domain U is a finite set of objects and the elements in U are objects/instances. C is a condition attribute set D is a decision attribute set. A is set of attribute and equals to C∪D. V is the set of attribute values and Va is a domain of attribute a. f: UxA→V is a function such that f (xi, a) ∈Va for every a∈A, xi∈U.
In Table 1, C = {a, b, c}, D = {d,e), Vb = {0, 1, 2}, Vc = {0, 2}, Vd,e {0, 1, 2}.
| Table 1: | Decision Table |
 | |
The binary relation of indiscernibility is ![]() . The attribute value of a for object x is a(x). ind (a (x)) is an equivalence class that including x and marked as [Va = a (x)]a. For example, if a (x) = 1, the equivalence class is [Va = 1]a = {x1, x4, x5}.
. The attribute value of a for object x is a(x). ind (a (x)) is an equivalence class that including x and marked as [Va = a (x)]a. For example, if a (x) = 1, the equivalence class is [Va = 1]a = {x1, x4, x5}.
The first record in Table 1 can be written as:
| (1) |
In order to describe the rule’s accuracy degree, the trust degree is adopted to estimate the quality of classification. In this study, we use classification accuracy ratio and coverage ratio to describe rule.
Definition 1: Let R denote the equivalent set of condition, D denote the equivalent set of conclusion. For rule r→d, two variables are defined as follow:
Accuracy ratio: aR (D) = |R∩D|/|R|, which means the probability of D occurrence can be denoted as P (D|R) for a rule that satisfies R.
Coverage ratio: KR (D) = |R∩D|/|D|, which means the probability of R occurrence can be denoted as P (R|D) for a rule that satisfiesD.
As shown in Table 1, let R equal [a = 1], D equal [d = 0, e = 2], then [Va = 1]a = {x1, x4, x5}, [d = 0, e = 2]d,e = {x3, x5}, aR (D) = 1/3, KR (D) = 1/2.
Thus, the rule r→d can be rewritten in the following form:
| (2) |
αR (D), κR (D) denote the rule’s accuracy ratio and coverage ratio respectively. The former rule can be expressed as:
| (3) |
Definition 2 (positive rule) R→d is positive rule if αR (D) = 1.0 and R = ∧j [aj = vk].
While αR (D) =1.0, the equivalence class of D is a subset of equivalence class of D, it means [R]⊆[D]. As we know, the positive domain of D, PosR (D) equals to ∪ {Y = U/R, Y⊆D}. |Y∩D|/|Y|, if αR (D) =1.0. Thus the positive rules are those coming from PosR (D).
In the above approximation of D relative to R, R¯ (D) = ∪{Y∈U/R; Y∩D≠Φ}, so |R¯ (D)∩D|*D| = 1.0 equals 1.0. This can be explained as R¯ (D) is a particular case that satisfies KR (D) 1.0.
In Table 1, let R = a, D is [d = 0, e = 2]. U/IND (R) = {{x1, x4, x5}, {x2, x3}}, [d = 2, e = 2]d,e = {x2, x5}, Thus R¯ (D) = {x1, x2, x3, x4, x5} and |R¯ (D) ∩ D/|D| = 1.0. To obtain [d = 0, e = 2], there are two choices [a = 1], [a = 2] for R = a. Thus,
| (4) |
Formalization: d→wj [aj = vk]
So, we get ∧j¬[aj = ak]→5d
Definition 3 (negative rule (Tsumoto, 2001)) ∧j¬[aj = ak]→5d is negative rule, while ∨j [aj = vk] (D) κ∨j[aj = vk] (D) = 1.0.
Consider Eq. 4, for the same attribute a, [a = 1] ∨[a = 2]→[d = 2, e = 2], κ = 1.0 and [a = 2]∨[b = 2]→[d = 2, e = 2], κ = 1.0. Also, we can get negative rule: ¬[a = 2]∧5 [b = 2]→5[d = 2, e = 2], where a, b are different attributes.
According to above analysis, we come to the conclusion that negative rule can be deducted from combination of different values for the same attribute, also can be deduced from combination of different attribute-value pair. And it will cost much time to generate all negative.
ALGORITHM OF RULE GENERATION
Positive and negative rules are the two forms for an equivalent class of D. The negative rule corresponds to the negative domain NegR (D) while the positive rule corresponds to the positive domain PosR (D). In rough set theory, each positive domain is with a negative domain. For a particular R and D, there are several rules in a positive domain but only one negative rule in a negative domain. The classic rule reduction is based on records in the decision table, where the records are serially processed. It is not suitable for negative rule generation. The rule generation based on classification attribute that we provide can generate positive and negative rules in parallel instead of serial process.
Positive and negative rules own the same feature as [aj = vk]a∩[d]D≠Φ. Thus it’s necessary to find out all the condition attribute-value pairs that satisfy [aj = vk]a∩[d]D≠Φ while D’s value equals d.
For positive rules, we need to find out all attribute pairs’ conjunctions. Those attribute pairs should satisfy ∧j[aj = vk]⊆[d]D, where j is the maximum number of condition attribute. For negative rules,∨j[aj = vk]⊇[d]D needs to be satisfied.
 | |
| Fig. 1: | Algorithm RGCA (Rule Generation based on Classification Attribute) |
 | |
| Fig. 2: | Algorithms run window (RGCA) |
The algorithm is described as follow:
| • | Step 1: Select an equivalent class [d]D of classification attributes and find out all condition attribute-pair Lir, which overlaps with set [d]D |
| • | Step 2: Check condition attribute-pair R in L1= Lir and add those satisfy αR (D) = 1.0 to Pos set list and delete them from L1. Otherwise, these condition attribute-pairs will be kept in L1. The left pairs in L1 will be conjunct in the following phase |
| • | Step 3: Connect every two pairs in Lir , use LL1 represent connection result. If KR (D) = 1.0, add R to Neg set and delete it from LL1. Otherwise, these condition attribute-pair will go through next phase, where these pairs will be connected |
| • | Step 4: With Pos, Neg, d, the positive and negative rules are obtained |
It costs much more time to get negative rules than positive rules. Thus, we focus on achieving positive rules and negative rules act as supplements. At the same time we must reduce negative rules deduction time. Since, the negative rules deduction time increase when the negative condition dimension of is high, we ignore the negative rule with high condition dimensions. The algorithm pseudo code is as follow Fig. 1 and the GUI of algorithm is as Fig. 2.
EXPERIMENT RESULTS
We use datasets from UCI repository of machine learning databases and domain theories to verify the presented algorithm. Considering that rough set theory algorithms’ classification precision is affected by attribute’s discreteness forms, we select those datasets without need discrete.
It’s not necessary to obtain all the negative rules, since it takes time to deduce them and some of them may have only a little effect for classification or reasoning. A threshold is used to limit the time for negative rules.
As we know, negative rules as ∧j¬[aj = vk]→5d, where aj may come from the same attributes or different attributes. Assume μ is the number of aj which comes from different attributes, μ should satisfy the following equation, as our suggestion.
| (5) |
where, n is the number of dataset’s attribute. μ is a parameter decided by users and used to select relative simple formula for negative rules’ computation.
Table 2 summarizes our analysis results, which shows the number of positive rules and negative rules obtained by RGCA.
| Table 2: | Result of the RGCA |
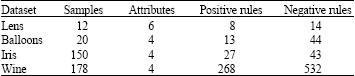 | |
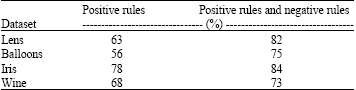
| Table 3: | The classification of positive rules and negative rules |
 | |
The number of negative rules is bigger than positive rules under the threshold μ. More redundant negative rules will be obtained by increasing μ.
In order to test the negative rules’ usage for classification and reasoning, each dataset was divided into two subsets equal in data number. One is for generating positive and negative rules (supervised learning) and the other is for reasoning. The samples were randomly selected for learning.
Based on RGCA, we can easily get the positive rules and perform classification experiment based only on positive rules. The classification precision is shown as follow.
Table 3 shows that the classification precision increases rapidly when samples used for learning are insufficiency. It means that negative rules have positive effect on classification and increase the reasoning precision. When samples are adequate, the classification mainly depends on positive rules while negative rules affect classification slightly.
It costs much more time to obtain negative rules than positive rules. The time will increase as the samples and attributes become larger. But for datasets with large samples and attributes, the positive rules are sufficient enough for classification and there is no need to deduce negative rules. The suggestion for such scenario is letting μ equal 1.
DISCUSSION
For the negative rules extraction, we don’t deduce all negative rules for classification. Tsumoto (2001) gave an algorithm to deduce all negative rules based on rough set, but he didn’t discuss the algorithm’s efficiency. Alatas and Akin (2006) did not discuss the efficiency either while they provided a method to deduce all negative rules based on association rules. The presented algorithm is restricted to extract all negative rules in order to not decrease the algorithm’s efficiency.
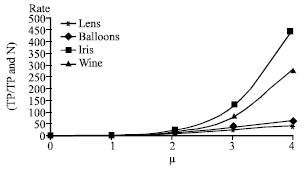 | |
| Fig. 3: | The rate of algorithm with different μ |
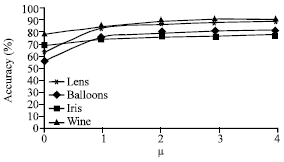 | |
| Fig. 4: | The accuracy of algorithm with different μ |
In this study, we discuss the negative rule form as: ∧j¬[aj = vk]→5d. The other form like ∧j¬[aj = vk]→d is not discussed. But Alatas and Akin (2006) got negative rules like ¬D∈[d1, d2]⇒C∈[c1, c2] based on association rule. We will present the RGCA in a later version later, which include the negative rule extraction like form ∧j¬[aj = vk]→d.
The negative rules extraction is much more complexity than positive rules. So, in order to balance the classification accuracy and efficiency, the negative rule’s attribution number should be restricted. For the negative rules as ∧j¬[aj = vk]→5d, the aj may come from the same attributes or different attributes. Intuitionally, the number of aj has relation with the number of attribute number and the record number. How to decide the number of aj is diverse with different dataset. We estimate the time of RGCA according to several values of μ (as shown in Eq. 5). We describe the efficiency of algorithm with rate = TP/TP&N, where the TP means the time of inducing positive rules, TP and N means the time of inducing positive and negative rules. In Fig. 3, it showed that rate of time cost is increased hundredfold while μ>2. While μ>2, the classification accuracy is not increased significantly, as shown in Fig. 4. This is the reason why we assigned μ = 1 in the presented algorithm. While we put forward the formulation (5), the μ should be decided according to its dataset’s attribute and sample numbers. This is another work we will do in the later.
CONCLUSIONS
Traditional algorithms treat consistent and inconsistent rules separately. The rule deduction based on classification attributes can deal with consistent and inconsistent rules in parallel. Assume there are inconsistent rules R→d1 and R→d2, traditional algorithms will not generate one rule that includes R. Thus the result of R is unknown. In RGCA, there exists a negative rule of d1 and d2, which condition part includes ¬R.
According to a decision attribute d, we assume there are conditions attributes C = {a1, a2.... an}Then we will get positive rule as ∧j[aj = vk]→d, i = 1, ...n through the rule deduction based on classification attributes. The inversion of these positive rules’ combination will lead to a negative rule ¬[∨[∧j[ai = vk]]]→5d, i = 1,...n. And the equivalent class of ∪[∧i[ai = vk]] is mapped to the d’s positive region.
For small samples and low dimension, the cost of deducing negative rules is not high but the effect of negative rules’ classification is noticeable.
ACKNOWLEDGMENTS
This study is partly supported by the oversea study scholarship of jiangsu government and jiangsu youth project, Natural Science Foundation of Nanjing University of Information and Science Technology (20080302).
REFERENCES
- Wu, X., C. Zhang and S. Zhang, 2004. Efficient mining of both positive and negative association rules. ACM Trans. Inform. Syst., 22: 381-405.
Direct Link - Ji, L. and K.L. Tan, 2004. Mining gene expression data for positive and negative co-regulated gene clusters. Bioinformatics, 20: 2711-2718.
CrossRefDirect Link - Tsumoto, S., 2001. Mining Positive and Negative Knowledge in Clinical Database Based on Rough Set Model. In: Principles of Data Mining and Knowledge Discovery, De Raedt, L. and A. Siebes (Eds.). Springer-Verlag, Berlin Heidelberg, pp: 460-471.
CrossRef - Pawlak, Z. and A. Skowron, 2007. Rudiments of rough sets. Inform. Sci., 177: 3-27.
CrossRefDirect Link - Hu, Q., X. Li and D. Yu, 2006. Analysis on Classification Performance of Rough Set Based Reducts. In: PRICAI 2006: Trends in Artificial Intelligence, Yang, Q. and G. Webb (Eds.). Springer-Verlag, Berlin Heidelberg, pp: 423-433.
CrossRef - Alataş, B. and E. Akin, 2006. An efficient genetic algorithm for automated mining of both positive and negative quantitative association rules. Soft Comput.-A Fusion Foundat. Methodol. Appl., 10: 230-237.
CrossRefDirect Link