
E. Logashanmugam
Sathyabama University, Chennai, India
R. Ramachandran
Sri Venkateshwara College of Engineering, Chennai, India
Information Technology Journal
Year: 2008 | Volume: 7 | Issue: 1 | Page No.: 180-184







ABSTRACT
Image compression is currently a prominent topic for both military and commercial researchers. Due to the rapid growth of digital media and the subsequent need for reduced storage and to transmit the image in an effective manner Image compression is needed. Image compression attempts to reduce the number of bits required to digitally represent an image while maintaining its perceived visual quality. This study concentrates on the compression of the image using the new sub-band coding algorithm of wavelet transform. This study also deals with a visually lossy contrast-based quantization algorithm for wavelet-based compression of natural image. The DWT is applied for various images and the compression ratios are obtained. The performance of this method is compared with the available compression technique, showing good agreements.
PDF Abstract XML References Citation
How to cite this article
E. Logashanmugam and R. Ramachandran, 2008. An Improved Algorithm for Image Compression Using Wavelets and Contrast Based Quantization Technique. Information Technology Journal, 7: 180-184.
DOI: 10.3923/itj.2008.180.184
URL: https://scialert.net/abstract/?doi=itj.2008.180.184
DOI: 10.3923/itj.2008.180.184
URL: https://scialert.net/abstract/?doi=itj.2008.180.184
INTRODUCTION
An increasing interest has been shown in image compression since the development of Digital computers and Communication. A lot of researchers are working on image compression (Subramanya, 2001; Welstead, 1999; Albanesi, 1996), still there is some scope of work in compression using wavelet transform. This study concentrates on the Discrete Wavelet Transform and its applications on image compression. In this study, a visually lossy contrast-based quantization algorithm for wavelet-based compression of natural image is considered. Image compression attempts to reduce the number of bits required to digitally represent an image while maintaining its perceived visual quality. The Discrete Wavelet Transform (DWT) (Goswami and Chan, 1999) which separates an image into spatial-frequency and orientation components. It approximately decorrelates the image and provides good energy compaction. The computational efficiency afforded by the DWT, makes it attractive particularly for image compression and analysis.
THEORY
Figure 1 shows the steps involved in wavelet-based image compression and Fig. 2 shows the sub-band coding technique of wavelet transform. The DWT is typically implemented via a filtering/lifting operation, in a separable fashion by successively processing the rows and the columns of the image. This operation results in a separation of the spatial frequency plane, where upon the image is represented as a series of spatial frequency bands (called sub bands).
| Fig. 1: | Key steps involved in wavelet-based image compression |
The N-level DWT will yield 3N+1 sub-bands; each level contains an LH band, an HL band and an HH band. LH sub-bands are low-pass filtered horizontally and high-pass filtered vertically and thus contain horizontal edge information. HL sub-bands are low-pass filtered vertically and high-pass filtered horizontally and thus contain vertical edge information. HH sub-bands are high-pass filtered in both directions and thus contain both 45° and 135° edge information.
The frequency content of each sub-band can be described by its center spatial frequency (given in cycles per pixel or cycles per degree of visual angle) and by its predominant orientation. The three sub-bands in a level are collectively referred to as a scale. The finer scales contains high-frequency information and coarser scales contains low-frequency information. The coarsest scale contains four sub-bands, in which the additional band is the LL band. After an image is transformed into its spatial-frequency representation, the coefficients within each sub-band are quantized. Quantization is a non-invertible process in which a continuous set of input values (e.g., sub band coefficients) are approximated by a discrete set of output levels (called reproduction values). Let c(s) denote a coefficient of sub-band s and let C = {Cn}. A scalar quantizer operates on each coefficient c(s) to produce C(S). The value of C(S) is calculated using the relation;
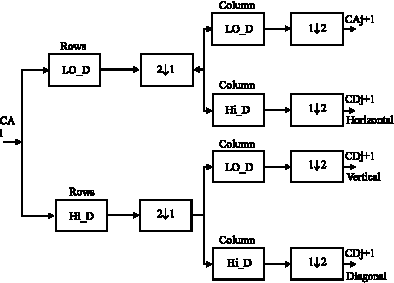 | |
| Fig. 2: | Suband coding of wavelet transform |
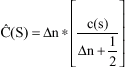 | (1) |
Where, Δn is the quantizer step size.
Furthermore, if the intervals are equi-spaced (i.e., Δn = Δn), the quantizer is said to be uniform quantizer. Quantization is modeled by the addition of distortions to the original image. Specifically, quantization of a sub-band coefficient c(s) induces an error d(s) = Ĉ (s) – c(s), which manifests itself in the reconstructed image as a wavelet basis function (distortion). The amplitude is proportional to d(s) x | Ψ(s)|, where Ψ(s) represents the wavelet basis function associated with sub-band s. When all coefficients of sub-bands are quantized, the resulting distortions constitute a superposition of scaled wavelet basis functions (Ramos and Hemami, 2001). The (mean-offset) distortions, E, are given by:
(2) |
Where, m and ![]() denote the original and reconstructed images, respectively and μm corresponds to the mean pixel-value of m. Thus, quantization is modeled as the addition of e to m; i.e., an image reconstructed from quantized sub-bands is given by:
denote the original and reconstructed images, respectively and μm corresponds to the mean pixel-value of m. Thus, quantization is modeled as the addition of e to m; i.e., an image reconstructed from quantized sub-bands is given by:
(3) |
During compression, the quantizer step size (Δn) for each sub-band is typically selected based on rate-distortion criteria using Mean-Squared Error (MSE) as the distortion metric. However, to achieve maximum compression of an image in a visually lossless scheme, the step size is selected in order to keep the resulting distortions just below the threshold of visual detection. Furthermore, when rate constraints necessitate the generation of super threshold distortions, the step sizes must be selected so as to preserve the visual quality of the compressed image. These goals are attained by understanding both the visual detectability of the distortions and the masking effects imposed upon this detectability when the distortions are viewed within an image.
Entropy coding, which constitutes the final stage of most compression algorithms, serves to encode the quantizer`s output into fixed- or variable-length code words. Unlike quantization, entropy coding is a lossless process which is entirely reversible. The basic strategy of an entropy coder is to assign shorter-length code words to symbols (or groups of symbols) that appear more frequently and longer-length code words to symbols (or groups of symbols) that occur less frequently. Huffman coding is a predominant entropy-coding scheme used in this image compression. A dynamic contrast-based quantization algorithm (DCQ-LS) for visually lossy compression of natural images is described in the next section.
DYNAMIC CONTRAST-BASED QUANTIZATION (DCQ-LS)
The dynamic contrast-based quantization algorithm (DCQ-LS) (Webster and Miyahara, 1997; Bex and Makous, 2002) for visually lossy compression of natural images is described here. DCQ-LS operates by quantizing each sub-band, such that the distortions in the reconstructed image exhibit the specified summation-adjusted threshold contrasts (Georgeson and Sullivan, 1975). Let C(ts) denotes the RMS contrast of the mean-offset distortions ts induced via quantization of sub-band s. For visually lossy compression, C(ts) = CT(ts|m, t). Then, {C(ts)} is mapped to a corresponding {D(s)}, where D(s) represents the mean-squared error (MSE) in sub-band s and then the sub-bands are quantized. Finally, the quantized coefficients are entropy encoded (Antonini et al., 1992) to generate the compressed stream. The DCQ algorithm is summarized, as follows:
Initially the selection of Global Visual Distortion (GVD) is done based on the desired bit-rate. From the given GVD, the Visual Distortion (VD) is computed and then RMS contrast C(ts) is computed for each sub-band s. Then from {C(ts)}, the corresponding {D(s)} is computed and the sub-bands are encoded. By adjusting the GVD, the above said procedure is repeated until the target rate is met with desired accuracy.
The Computation of GV D based on a Target Bit-Rate is explained as follows:
Given a target bit-rate R, GVD should be selected to yield a compressed image at the rate R. Assuming that the rate-distortion function of each sub-band s is given by:
(4) |
The rate R is obtained from:
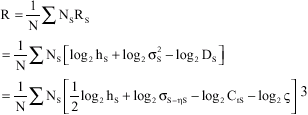 | (5) |
Where, N denotes the total number of coefficients, Ns denotes the number of coefficients in sub-band s and the factor hs depends on the probability density function g¯s of the normalized sub-band g¯s = s/os; e.g., assuming high-resolution quantization, hs is given by
(6) |
(7) |
(8) |
Where, A0 and A1 are defined as follows
(9) |
(10) |
RESULTS AND DISCUSSION
The image compression has been carried out using wavelet. A new technique called DCQ quantization is also dealt with. Figure 3 shows the PSNR value versus bits/pixel for one sub-band at a time for the first level decomposed image. Figure 4 shows the PSNR value versus bits/pixel for two sub-band at a time for the first level decomposed image. Figure 5 shows the PSNR value versus bits/pixel for all sub-bands at a time, for the first level decomposed image.
Figure 6 shows the graph of the PSNR value versus bits/pixel for one sub-band at a time for the second level decomposed image.
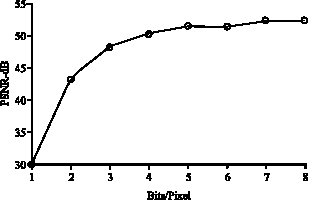 | |
| Fig. 3: | One sub-band at a time (first level) |
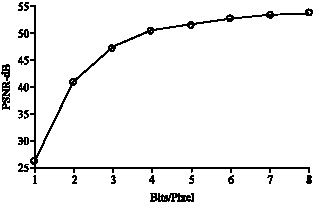 | |
| Fig. 4: | Two sub-band at a time (first level) |
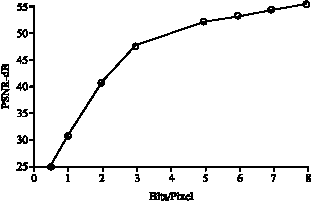 | |
| Fig. 5: | Quantize all sub-bands (first level) |
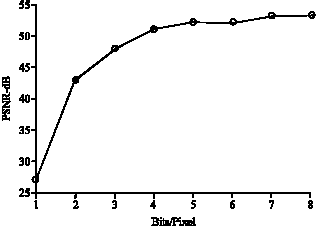 | |
| Fig. 6: | One sub-band at a time (second level) |
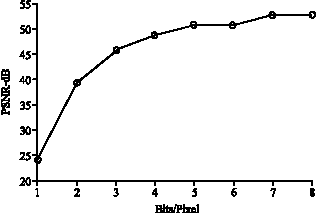 | |
| Fig. 7: | Two sub-band at a time (second level) |
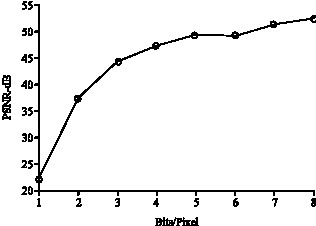
Figure 7 shows the PSNR value versus bits/pixel for two sub-band at a time for the second level decomposed image. Figure 8 shows the PSNR value versus bits/pixel for all sub-bands at a time, for the second level decomposed image.
Figure 9 shows the PSNR value versus bits/pixel for one sub-band at a time for the five level decomposed image. Figure 10 shows the PSNR value versus bits/pixel for two sub-band at a time for the five level decomposed image.
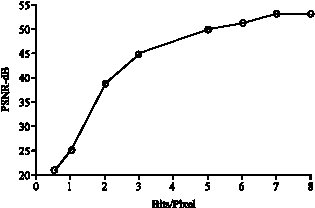 | |
| Fig. 8: | Quantize all sub-bands (second level) |
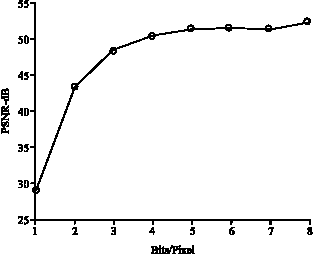 | |
| Fig. 9: | Five level decomposition (one sub-band) |
 | |
| Fig. 10: | Five level decomposition (two sub-band) |
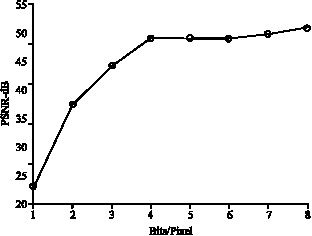
Figure 11 shows the PSNR value versus bits/pixel for all sub-bands at a time, for the five level decomposed image.
Figure 12 shows the PSNR value versus compression ratio for two sub-bands at a time, for the second level decomposed image.
 | |
| Fig. 11: | Bits/Pixel vs PSNR (all sub-band) |
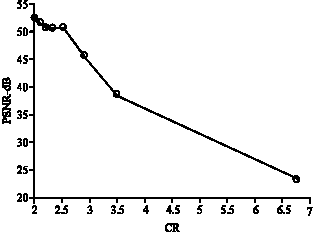 | |
| Fig. 12: | PSNR vs CR (two sub-bands) |
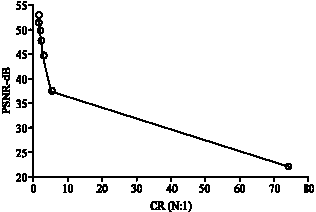 | |
| Fig. 13: | PSNR vs CR (all sub-bands) |
Figure 13 shows the PSNR value versus compression ratio for all sub-bands at a time, for the second level decomposed image. Table 1 shows the comparison of first level decomposition for various sub-bands and various bits per pixel. It also shows the comparison of the compression ratios.
| Table 1: | Comparison results and discussions first level decomposition |
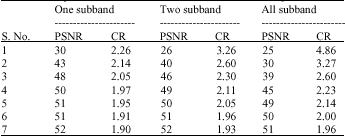 | |
CONCLUSION
A detailed study of the image compression using the DWT and DCQ algorithm is done. Two different images have considered for the analysis. The PSNR value versus bits/pixel graphs have been plotted for different sub-band levels. The PSNR value versus compression graphs have also been plotted for different sub-band levels. A detailed comparison of first level decomposition for various sub-bands and various bits per pixel has been done.
REFERENCES
- Albanesi, M.G., 1996. Wavelets and human visual perception in image compression. Proc. ICPR, 2: 859-863.
CrossRef - Antonini, M., M. Barlaud, P. Mathieu and I. Daubechies, 1992. Image coding using wavelet transform. IEEE Trans. Image Process., 1: 205-220.
CrossRefDirect Link - Bex, P.J. and W. Makous, 2002. Spatial frequency, phase and the contrast of natural images. J. Opt. Soc. Am. A, 19: 1096-1106.
Direct Link - Georgeson, M.A. and G.D. Sullivan, 1975. Contrast constancy: Deblurring in human vision by spatial. J. Physiol., 252: 627-656.
PubMed - Ramos, M.G. and S.S. Hemami, 2001. Suprathreshold wavelet coefficient quantization in complex stimuli: Psychophysical evaluation and analysis. J. Opt. Soc. Am. A, 18: 2385-2397.
Direct Link