
Khairul Anuar Ishak
Department of Electrical, Electronic and System Engineering, Faculty of Engineering, Universiti Kebangsaan Malaysia,
43600 UKM Bangi, Selangor Darul Ehsan, Malaysia
Salina Abdul Samad
Department of Electrical, Electronic and System Engineering, Faculty of Engineering, Universiti Kebangsaan Malaysia,
43600 UKM Bangi, Selangor Darul Ehsan, Malaysia
Aini Hussain
Department of Electrical, Electronic and System Engineering, Faculty of Engineering, Universiti Kebangsaan Malaysia,
43600 UKM Bangi, Selangor Darul Ehsan, Malaysia
Information Technology Journal
Year: 2006 | Volume: 5 | Issue: 3 | Page No.: 507-515







ABSTRACT
Face recognition is one of the key components for future intelligent vehicle applications such as determining whether a person is authorized to operate the vehicle. This study describes the development and implementation of an automatic face recognition system in the car environment. The challenge is to build a fast and accurate system that is able to detect, recognize and verify a driver`s identity with the constraint introduced in the car environment in daylight lighting conditions. A further constraint is to use a low-cost web camera to capture the frontal images. The system consists of two parts. The first is face detection, which is based on combining fast and classical Neural Networks (NN) methods. The second is face recognition and verification, which is based on combining Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA) techniques. Lighting correction techniques are applied to improve the overall performance. The proposed system has been tested in the car environment and has a recognition rate of 91.4% with 0.75% false acceptance rate. Face detection is achieved in 3.7 sec while face recognition for a car with two persons authorized to operate the vehicle is 1.4 sec.
PDF Abstract XML References Citation
How to cite this article
Khairul Anuar Ishak, Salina Abdul Samad and Aini Hussain, 2006. A Face Detection and Recognition System for Intelligent Vehicles. Information Technology Journal, 5: 507-515.
DOI: 10.3923/itj.2006.507.515
URL: https://scialert.net/abstract/?doi=itj.2006.507.515
DOI: 10.3923/itj.2006.507.515
URL: https://scialert.net/abstract/?doi=itj.2006.507.515
INTRODUCTION
Intelligent vehicles have many interesting advantages in real world transportation (Gosh and Lee 2000; Masaki, 2004). In the future, an intelligent vehicle is equipped with cameras, microphones and other sensors installed to perform different functions such as tracking and recognizing occupants and interpreting their behaviors by extracting and processing the required data. One commonly used method for measuring human factor information is the biometric solution. Luxury car manufacturers such Lexus, BMW and Mercedes have been using fingerprint authentication that allows keyless access to the vehicles (TAC, 2000). More recently, the automotive developers have started to conduct research on applying face recognition in the car environment.
To our knowledge, no complete face recognition system tailored to the car environment has been reported. A face recognition system in a car environment must take into considerations the face detection aspect prior to the recognition task. Preliminary work on face recognition application in the car environment has been conducted using PCA, also called Eigenface (Craig, 1999). This work excludes the face detection task. A face detection system for in-car environment, without the recognition phase, is described by Wu and Trivedi (2005) using edge density descriptors and skin-tone features. Most other in vehicle system uses face detection to perform tasks such as drowsiness detection (Smith et al., 2003).
This study describes the development, implementation and testing of a prototype face recognition system that tailors to the car environment. The goal is to develop an automatic face recognition system, which will locate the face of the driver, determine the driver’s identity and verify the driver’s authorization to operate the vehicle. The system has to operate as fast and accurate as possible and this is achieved using a combination of techniques. A further constraint imposed on the system is that the capturing device used is a low-cost web camera and that the system is able to operate at different daylight lighting conditions.
The system can be divided into two parts: face detection and face recognition. For face detection, a combination of fast and classical NN is proposed to deal with variations in scale and lighting conditions likely to appear in the car environment. First, face detection based on cross correlation of NN weights, which is known as a Fast Neural Networks (FNN) (Yacoub et al., 1998; 1999), is applied. To improve accuracy, we propose the use of another network, termed Classical Neural Networks (CNN), to verify the face regions thus reducing misclassification rates.
For the face recognition task, an algorithm used is based on the combination of PCA (Turk and Pentland 1991) and LDA (Belhumeur et al., 1997; Zhao et al., 1998) techniques. The algorithm combines the advantages of PCA by reducing the dimension of the feature vectors and of LDA by obtaining the best linear classifier. In addition, for both face detection and face recognition we use an illumination correction approach (Rowley et al., 1995) to improve the performance of the overall system.
OVERVIEW OF THE SYSTEM
Figure 1 shows the components of the in-car face recognition system. A low-cost web camera mounted on the dashboard on the driver’s side is used to capture the face image. During the authentication process, the driver is asked to look straight ahead at the camera. The computer is used as a platform for the face recognition system. The system processes the received data, compares them to the stored data in the template and sends control signals to the entry-components, which are the latch and ignition switch.
The face recognition system must do two major tasks: face detection and face recognition. Figure 2 presents a block diagram of the face recognition system. The face detection module is main engine of the system. It receives an input image and then examines each part of the image at several scales looking for locations that might contain a human face. Once a face has been localized and segmented within an image, it must be standardized or normalized to ensure good performance in the next module that performs the face recognition task. Normalization includes an adjustment of illumination and of image shape by rescaling to a standard size. To recognize the identity of the normalized face, the face recognition module is used to find the best match in a database of registered face models. Finally, a binary output decides whether to reject or to accept the subject as the person authorized to operate the car.
FACE DETECTION MODULE
Here, we will describe the development of face detection module. Before we carry on our discussion, it is necessary to mention the related work.
Related work: In recent years, many methods have been proposed to detect human faces from images with simple or complex backgrounds. A well-known method is neural network. Good performances have been obtained by classical (artificial) neural network based method where Rowley et al. (1998) have achieved a detection rate of 90.5% on their image database. Generally, CNN approaches achieve high detection rate because they are powerful in discriminating between face and non-face patterns when trained with a large number of samples (Sung and Poggio, 1998). However, the high computation cost induced by the need to process all possible positions of the face at different scales of the original image is the main drawback of these approaches. More recently, FNN for face detection have been presented (Yacoub et al., 1998). The speed up factor of these fast networks is obtained by using cross correlation in the frequency domain of the input image and the weights of the hidden layer. However, the system achieved detection rates of only in the range 70 to 75%. In addition, the FNN approach generates more false alarms compared to CNN.
For the in-car face recognition system, is it necessary to develop a fast and accurate method, which can detect and localize a face in an image. We propose using a FNN to detect possible face regions in an image. However, as this method always suffers from false alarms which is further worsen in the car environment due to variable lighting conditions, we suggest a verification procedure to check that the detected face region is actually a face. Non-linear image processing such as histogram equalization can be used to correct illumination problems. However, since this is a local process, it cannot be integrated into the global Fourier Transform framework.
Hence, an additional neural network, a CNN, is used as a face region verification procedure to reduce the number of false detections. A lighting normalization method using linear fit function and histogram equalization is used on the candidate regions before they are fed into the CNN.
Algorithm: The algorithm for the face detection module is shown in Fig. 3. The first step is to apply the FNN method to search for possible face regions in the test image. Post-processing strategies are applied to the detected regions using multi-scale face detection and elimination of overlapping detections. The extracted possible face regions at all scaling levels are sub-sampled and interpolated to a resolution of 25x25, the size of the training image. A lighting normalization technique is then applied. To verify the face regions, the data is then mapped onto CNN and the output examined. Any output that falls below a set threshold value is rejected, otherwise the face region is confirmed as containing a face.
Training networks: Table 1 shows the network properties of both the FNN and CNN. In order to train the networks, a large number of face and non-face images are needed.
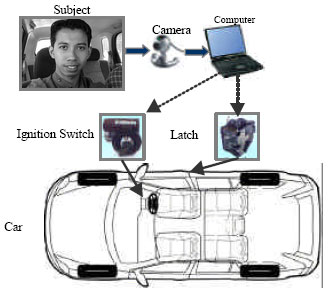 | |
| Fig. 1: | Overall system set-up |
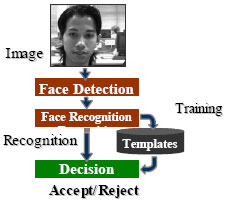 | |
| Fig. 2: | Block diagram of the face recognition system |
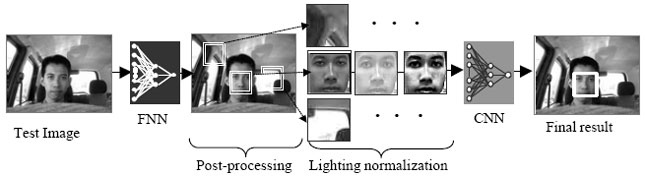 | |
| Fig. 3: | Face detection module |
 | |
| Fig. 4: | Example of training images |
| Table 1: | Network properties |
 | |
In our dataset of face images, we have collected 1,210 face images. The face images are all of up-right frontal position in various sizes, expressions and intensities. The face region is cropped and the eyes and center of the mouth are labeled in order to normalize each face to the same scale and position. All the training set images are resized to 25x25 pixels to keep the input layer of the network manageably small, but still large enough to preserve distinctive visual features of face patterns. In addition, three face images are generated from each original image to increase the size of the training set. This is done by randomly mirroring and rotating to a maximum of 5°about their center points.
The non-face images used for training are much more varied than the face images. Ideally, any image not containing a face can be a characterized as a non-face image. This makes the number of non-face images very large compared to the face images. The initial set of non-face images used for training consisted of about 5000 non-faces examples. Additional non-faces were introduced by applying the bootstrap (Sung and Poggio, 1998) algorithm. Figure 4 shows examples of face and non-face training samples.
Fast neural networks: In (Yacoub et al., 1999), a fast algorithm for face detection based on two-dimensional cross correlations of the image and a sliding window (25x25 pixels) was described. Such window is represented by the neural network weights situated between the input unit and the hidden layer.
During detection, a sub-image (sliding window), ω, of size M by N is extracted from the test image, of size A by B and fed to the network. Let Φi be the vector of weights between the input sub-image and the hidden layer. The output of the i-th hidden neurons, hi, can be calculated as follows:
| (1) |
where, f is the activation function and the bi is the bias of each hidden i-th neuron. For the whole image, χ, the output be obtained as follows:
| (2) |
Equation (2) represents a cross correlation operation. Given any two function g(x,y) and a template t(x,y), their cross correlation can be obtain by:
| (3) |
Therefore, Eq. (2) may be written as follows:
| (4) |
The above cross correlation can be expressed in terms of its Fourier Transform as:
| (5) |
where, ![]() is the complex conjugate of the Fourier Transform. By evaluating this cross correlation in the frequency domain, a speed up factor can be obtained over the CNN method. The output of the FNN can be evaluated as follows
is the complex conjugate of the Fourier Transform. By evaluating this cross correlation in the frequency domain, a speed up factor can be obtained over the CNN method. The output of the FNN can be evaluated as follows
| (6) |
where, NI and NH are the number of neuron in the input and hidden layers. In our system, a three-layer feed-forward neural network, or multi-layer perceptron (MLP) is used. Here, O is the output while WO, WH, ΦI refer to the weights of output, hidden and input layers, respectively. BO, BH, BI are the corresponding bias.
Multi-scale face detection: As the FNN is trained with images of size 25x25 pixels, it could only detect faces of this size. However, the size of the face in the real environment can be larger than this. To solve the problem, scaling pyramid is introduced where the input image is scaled by a factor of 1.2 for each step in the pyramid. Scanning an image at several resolutions can be done by sub-sampling the whole test image at several scales before using them as inputs to the neural network. The sub-sampling can be entirely performed using the following scaling property of the Fourier Transform.
| (7) |
Where, f(ax,by) is the original image and ![]() is its Fourier Transform with a and b scaling factor. Figure 5 shows the steps for multi-scale face detection.
is its Fourier Transform with a and b scaling factor. Figure 5 shows the steps for multi-scale face detection.
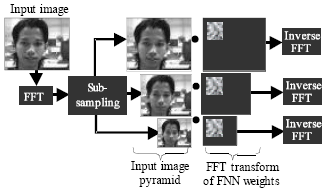 | |
| Fig. 5: | Multi-scale face detection steps |
FACE RECOGNITION MODULE
After completing the first module in our system design, then we proceed to develop the next step, which is face recognition module. Here, we will describe the development of face recognition module.
Related work: Face detection is about determining the locations and sizes of faces in an image, separating them from other non-face objects. Recognition, on the other hand, is about establishing the identity of the person given the image of his face. This is done with reference to a database of known faces.
Among face recognition algorithms, techniques based on PCA popularly called eigenfaces, have played a fundamental role in dimensionality reduction and demonstrated good performance. PCA based approaches typically include two phases: training and classification. In the training phase, face images are mapped onto the eigenspace. In the classification phase, the input face image is projected to the same eigenspace and classified by an appropriate method.
Unlike PCA, which encodes information in an orthogonal linear space, LDA encodes discriminatory information in a linear separable space of which bases are not necessarily orthogonal. Researchers have demonstrated that LDA based algorithms outperform the PCA algorithm in many tasks. However, the LDA algorithm has difficulty processing high dimensional image data. In practice, particularly in face recognition application, there are often a large number of pixel or features available, but the total number of training patterns is limited and commonly less than the dimension of the feature space. This implies that the within-class scatter matrix either will be singular if its rank is less than the number of features or might be unstable (or poorly estimated) if the total number of training patterns is not at least five to ten times the dimension of the feature space (Jain and Chandrasekaran, 1982).
In our implementation, the fusion of LDA and PCA is used. This method consists of two steps: the first step is to use PCA to project an image into a lower dimensional space and second, LDA is used to maximize the discrimination power. PCA plays a role of dimensionality reduction and form an optimal data to solve the singularity and instability problem of the LDA method. In addition, to improve performance, the images are subjected to lighting normalization.
Algorithm: The high dimensionality of the feature-space is a well-known problem in the design of face recognition algorithm. Therefore, a method for reducing the dimensionality of such feature space is required. These methods are described in the following sections.
For each of the two methods, the face recognition procedure consists of:
| 1. | A feature extraction step where feature vectors are extracted. The projection of face space will be the feature vectors for PCA-based method. For the PCA+LDA algorithm, the projection of LDA will be the feature vector. |
| 2. | A classification step in which the feature vector is fed to a simple nearest neighbor classifier. |
PCA: Let X = [x1, x2, ....., xi..., xn] represents the dxN data matrix, where each xi is a face vector of d-dimensional, concatenated from an image of size p by q. Here d represents the total number of pixels in the face image and N is the number of face images in the training set. The steps are as follows:
| 1. | Calculate the mean vector of the training images. |
| (8) |
| 2. | Subtract the mean from each of the data dimensions. This produces a dataset whose mean is zero. |
| (9) |
| 3. | Form a matrix, A= [Φ1, Φ2, ..... Φi, ...., ΦN] with a size of dxN, then compute the covariance matrix, C, which characterizes the scatter of the data. |
| (10) |
| 4. | Compute the eigenvectors, ui and eigenvalues, λi, of C satisfying the equation |
| (11) |
| 5. | Choose k eigenfaces, ui, to correspond to the k highest eigenvalues, λi, using the following criterion where |
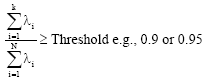 | (12) |
| 6. | Project original images onto the face subspace. |
| (13) |
In practice, the training set of face images will be relatively small, N<<d, hence the calculations become quite manageable. Using the PCA technique, a linear projection is obtained which maps the original data matrix, X, with d-dimensional of feature vector into the face subspace, Y, with k-dimension feature vector where k<<d.
Combining PCA and LDA: LDA is a well-known feature extraction technique that maximizes between-class separability and minimizes within-class variability. However, direct LDA has difficulty processing high dimensional image data. This problem can be overcome by combining PCA with LDA. Let [y1, y2, ....., yi..., yN] represent the kxN data matrix, where each yi is a face vector of k-dimensional feature vector where k ≤ d. The steps are as follows:
| 1. | Calculate the mean vector of the within-class, |
| (14) |
where ni is the number of training data from class-i.
| 2. | Calculate the between-class scatter matrix, SB and the within-class scatter matrix, SW, define as: |
| (15) |
| (16) |
where, g is the number of classes.
| 3. | Compute the eigenvectors, pi, of |
| (17) |
| 4. | Choose g-1 nonzero eigenvectors corresponding eigenvalues. |
| 5. | Find a projection vector for each corresponding class. |
| (18) |
where, ![]() is the vector describing the i-th class.
is the vector describing the i-th class.
| 6. | For classification, calculate the Euclidean distance, εi of an input image, θi to the i-th class data. |
| (19) |
A face is classified as belonging to class i when the minimum εi is below a set threshold, θi. Otherwise the face is classified as unrecognized.
Lighting normalization: In order to reduce variability due to lighting and camera characteristics, lighting normalization steps as discussed in (Rowley et al., 1995) is used. The first step tries to equalize the intensity values of the face images using a linear function. If the intensity value at the pixel (x,y) is I(x,y), then it can be fitted to the parameters of the linear model a,b and c such that
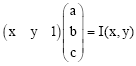 | (20) |
This linear function needs to be fitted into the whole image. The choice of this non-constant model is useful to the characterize brightness difference across the image. For all the pixels in the image, an over-constrained matrix equation is solved using the pseudo-inverse method as follows
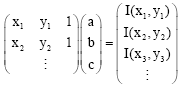 | (21) |
| (22) |
Thus,
| (23) |
 | |
| Fig. 6: | Steps in lighting normalization |
The histogram equalization step is performed in the next step. This is done by non-linearly transforming the intensity values in the image such that the histogram of the resulting image is flat. This enhances the contrast in the image and reduces the effect of variable camera gains. The steps of the lighting normalization procedure are shown in Fig. 6.
EXPERIMENTAL RESULTS
The experiments to evaluate the system are divided into two parts: face detection module and face recognition module. The experimental vehicle is a Malaysian made model Proton Satria 1.8. The capturing device is a web camera with a resolution of 480 by 640. All the processing is done on a computer with a processor speed of 1.5 GHz. Note that our current implementation is limited to the detection and recognition of frontal faces.
Face detection: The face detection module has been tested with Test Set 1, which consists of a total 400 face images of 40 subjects taken in the car environment. Each subject was asked to sit on the driver seat facing the camera while an image was acquired. Then the subject was asked to move his head forward and backward to obtain the face images at different scales. The image acquisition process was performed at different times. The images were captured in the morning, afternoon and evening to represent the different lighting conditions. In addition, images affected by shadows were obtained, for example by parking the car next to a building, hence casting shadows on the faces.
The performance of the proposed method FNN+CNN is compared to a purely FNN approach. The detection results are shown in Table 2. The detection rate of FNN+CNN method is 97.2%. It is noted that this detection rate does not significantly differ from a purely FNN approach. However, in terms of false detection rate the FNN+CNN approach outperforms the FNN technique.
| Table 2: | Results of face detection |
| Table 3: | Face recognition results |
| Table 4: | Face recognition results with lighting normalization |
Note that the average processing time of the FNN+CNN method is slightly higher than FNN method because of additional calculations required by the extra network. It takes the FNN+CNN 3.7 sec to locate a face.
The detection versus false detection tradeoff can be characterized by varying the detection threshold and generating a Receiver Operating Characteristics (ROC) curve. Figure 7 shows the ROC curve of for both methods. For any given detection rate, the FNN+CNN method outperforms the FNN in terms of false detections. For example, at a detection rate of 90%, the performance of FNN+CNN corresponds a false detection rate of 0.45% compared to FNN with a false detection rate of 1.8%.
Figure 8 and 9 show examples of successfully detected faces using the proposed FNN+CNN method. In Fig. 8 the lighting condition is considered normal since there is no strong directional illumination. In Fig. 9, even with strong directional illumination that causes the face to be illuminated unevenly, the FNN+CNN is able to detect the faces. Figure 10 shows examples of false detection. We observed that most of the face images that are not detected have strong shadows or are largely rotated off plane.
Face recognition: The face recognition module has been evaluated using a subset of Test Set 1 used for the detection module, termed Test Set 2. It consists of cropped face images of 24 subjects each with 10 images. Five images of each subject are used to construct the training data and the remaining five for testing data. The PCA+LDA approach is compared with purely PCA method for face recognition. In addition, experiments on the effect of lighting normalization are performed.
Table 3 shows that PCA+LDA approach has a higher average recognition rate compared to the PCA method. Although with PCA+LDA, the average recognition rate is not significantly higher than the PCA-based method, the misclassification in terms of false acceptance rate (FAR) is lower.
Table 4 shows the results with lighting normalization. For both methods, the recognition rate is improved with lighting normalization.
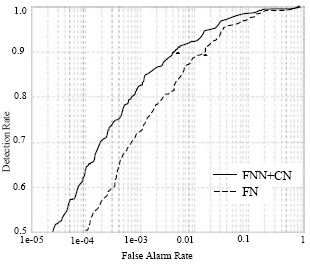 | |
| Fig. 7: | ROC generated by varying detection threshold |
 | |
| Fig. 8: | Examples of correct detection under normal illumination |
 | |
| Fig. 9: | Examples of correct detection under strong directional illumination |
 | |
| Fig. 10: | Examples of false detection |
Note that PCA+LDA have a higher average recognition rate of 91.43% and a lower misclassification rate of 0.75 % when compared to PCA.
For our system, the PCA+LDA technique is used along with lighting normalization for the face recognition module. The processing time is dependent on the number of subjects in the database. The average processing time for one person is approximately 0.7 sec. Hence for a car with two persons authorized to drive it, the processing time is 1.4 sec.
CONCLUSIONS
An automatic face recognition system for intelligent vehicles has been presented in two parts, the face detection module and the face recognition module. The face recognition module uses the output of the face detection module as the input signal. Experimental results have shown the system is able to produce fast and accurate results in the car environment. This is true even with a low cost capturing device and with variable daylight lighting conditions. We observe that the best overall system performance is obtained using FNN+CNN for face detection and PCA+LDA for face recognition with normalized lighting. This combination gives the highest recognition rate and the lowest misclassification rate. Although the face detection speed is fixed at 3.7 sec, the overall system speed is dependent on the number of persons authorized to use the vehicle. For a two-person system, it takes 1.4 sec to perform recognition resulting in a total processing time of 5.1 sec. We believe that is acceptable for this application although further improvement in speed is ideal. In addition, further improvement to the system will be to adapt the system to perform at night with in-car lighting and with variable head positions.
REFERENCES
- Belhumeur, P.N., J.P. Hespanha and D.J. Kriegman, 1997. Eigenfaces vs. fisherfaces: Recognition using class specific linear projection. IEEE Trans. Pattern Anal. Mach. Intell., 19: 711-720.
CrossRefDirect Link - Rowley, H.A., S. Baluja and T. Kanade, 1998. Neural network-based face detection. Pattern Anal. Mach. Intell., 20: 23-28.
CrossRef - Smith, P., M. Shah and N.V. Lobo, 2003. Determining driver visual attention with one camera. IEEE Trans. Intell. Transport. Syst., 4: 205-218.
CrossRef - Sung, K.K. and T. Poggio, 1998. Example-based learning for view-based human face detection. IEEE Trans. Pattern Anal. Mach. Intell., 20: 39-50.
Direct Link - Turk, M. and A. Pentland, 1991. Eigenfaces for recognition. J. Cognit. Neurosci., 3: 71-86.
CrossRefDirect Link - Zhao, W., R. Chellappa and A. Krishnaswamy, 1998. Discriminant analysis of principal components for face recognition. Proceedings of the 3rd Intelligent Conference on Automatic Face and Gesture Recognition, April 14-16, Nara, Japan, pp: 336-341.
CrossRef