
M.B. Youssef
Agricultural Genetic Engineering Research Institute, Agricultural Research Center, Giza, Egypt
H.A. Nour El-Din
Agricultural Genetic Engineering Research Institute, Agricultural Research Center, Giza, Egypt
W.F. Abd EL-Wahed
Faculty of Computers and Information, Minoufiya University, Shebin El-Kom, Egypt
A.A. Hemeida
Genetic Engineering and Biotechnology Research Institute, Minoufiya University, Sadat City, Egypt
International Journal of Virology
Year: 2012 | Volume: 8 | Issue: 1 | Page No.: 121-127







ABSTRACT
Epitopes prediction plays a vital role in the development of antibodies production and immunodiagnostic tests. This paper is focused on building models for predicting linear B-cell epitopes based on Support Vector Machine (SVM) and subsequence string kernel. The obtained models were tested by 10 fold cross validation method. We applied the obtained models to potato Leaf Roll Virus (PLRV) as a case study using Epitopes Model Applier Software (EMAS) which was developed as an open source software and released under General Public License (GPL) to predict immunogenic peptides suitable for antibodies production. The thirty amino acids peptide which start from position 163 to position 192 got high score and match the previous laboratory studies which make it one of the best candidates to be immunogenic and capable of producing antibodies that cross react with PLRV. The peptide was chemically synthesized and injected into animal (mouse). The obtained antibodies were tested by using TAS-ELISA and Immuno dot-blot assay. The obtained antibodies were positively reacted against PLRV infected potato tissues.
PDF Abstract XML References Citation
Received: June 20, 2011;
Accepted: July 23, 2011;
Published: October 25, 2011
How to cite this article
M.B. Youssef, H.A. Nour El-Din, W.F. Abd EL-Wahed and A.A. Hemeida, 2012. Application of Epitopes Prediction for Antibodies Production against Potato Leaf Roll Virus. International Journal of Virology, 8: 121-127.
DOI: 10.3923/ijv.2012.121.127
URL: https://scialert.net/abstract/?doi=ijv.2012.121.127
DOI: 10.3923/ijv.2012.121.127
URL: https://scialert.net/abstract/?doi=ijv.2012.121.127
INTRODUCTION
Epitope refers to any region of an antigen biomacromolecule which is recognized, or bound, by another biomacromolecule. The meaning is more restricted and refers to particular structures recognized by the immune system in particular ways. Epitope can be defined as the minimal structure necessary to invoke an immune response (Flower, 2008).
Epitopes prediction plays an important role in enhancing immunodiagnostic tests, reverse vaccinology, predicting allergenicity and antibodies production. Epitope prediction can be fairly described as both the high frontier of immunoinformatic investigation and a grand scientific challenge (Flower, 2007).
B-cell epitopes are regions of a protein recognized by antibody molecules. B-cell epitopes divided in two categories conformational epitopes and continuous epitopes. Conformational epitopes are discontinuous determinants on a protein antigen formed from several separate regions in the primary sequence of a protein brought together by protein folding. Continuous epitopes are linear antigenic determinants on proteins that are contiguous in amino acid sequence and do not require folding of a protein into its native conformation for antibody to bind with it (Cruse and Lewis, 2003).
One of most important applications of predicting B-cell epitopes is computational design of immunogenic peptides to produce specific antibodies for specific protein.
The purposes of this study aimed to (1) Building datasets to train epitopes prediction models on it; (2) Building B-cell prediction Models (BM), (3) Develop tool to apply the models to any protein sequence; (4) Predicting the epitopes in the case study (Potato leaf roll virus); (5) Selecting the immunogenic peptide to be injected into animal to produce antibodies that cross react with the potato leaf roll virus and (6) Testing the obtained antibodies.
MATERIALS AND METHODS
Waikato Environment for Knowledge Analysis (WEKA): The Waikato Environment for Knowledge Analysis (WEKA) is the leading open-source project in machine learning. WEKA is a comprehensive collection of algorithms for data mining tasks written in Java and released under the GPL, containing tools for data pre-processing, classification, regression, clustering, association rules and visualization (Gewehr et al., 2007). WEKA is developed in University of Waikato in New Zealand and it consists of WEKA Explorer, WEKA Experimenter, WEKA Knowledge Flow and WEKA simple command line interface. WEKA Explorer was used in this work for applying machine learning algorithm to datasets of epitopes to build B-cell prediction Models (BM).
Datasets: The datasets used for building the epitopes prediction models are a set of the epitopes and non-epitopes peptides obtained from IEDB (Peters et al., 2005) and datasets used in other work (El-Manzalawy et al., 2008a). The datasets were built in ARFF format containing two class attributes (1) for positive peptides and (0) for negative peptide. We built four datasets LB01-dataset, LB02- dataset, LB03-dataset and LB04- dataset. Table 1 illustrated the datasets and the number of instances in each one.
BM models building: Support vector machine and subsequence string kernel were used to build models for predicting linear B-cell epitopes as described in El-Manzalawy et al. (2008a, b). Table 2 shows the BM models decay factor (λ) parameter that used for building BM models.
Epitopes Model Applier Software (EMAS): Epitopes Model Applier Software (EMAS) was built on the top of Weka machine learning workbench (Frank et al., 2004), Epitopes Toolkit (EpiT) and BioJava (Holland et al., 2008). EMAS is available through this link (https://sites.google.com/site/epitopesprediction).
| Table 1: | Number of instances in LB-datasets |
 | |
| Table 2: | BM models parameters |
 | |
Case of study: Potato leaf roll virus: The case study was the coat protein sequence of the Egyptian isolates of potato leaf roll virus (El-Attar et al., 2010) obtained from NCBI with accessions No. ACU80557 (Fig. 1). The EMAS and BM models were used to predict most immunogenic peptide in this amino acids sequence of the coat protein of the Egyptian isolates of PLRV.
Synthetic peptide and immunization: Mice were injected five times with 50, 70, 150, 200 and 250 μg with one week interval between every injection with equal volume of complete Freund's adjuvant in first two injections and incomplete Freund's adjuvant for the rest injections. The blood was collected after one week from last injection then the antiserum was separated from blood and tested using immuno dot-blot analysis and Triple Antibody Sandwich ELISA (TAS-ELISA).
Serological detection of PLRV: PLRV-antiserum was tested using immuno dot-blot and TAS- ELISA according to the procedures described by Weidemann (1988), D’Arey et al. (1989) and El-Araby et al. (2009).
RESULTS
Epitope prediction models: We built eight models and they are available through the link (https://sites.google.com/site/epitopesprediction). Performance evaluation of BM models done by 10 fold cross validation test and area under the Receiver Operation Characteristic (ROC) curve was calculated to all BM models (Table 3).
Epitopes Model Applier Software (EMAS): EMAS which was developed as open source software and released under General Public License (GPL) is a tool to apply models to any protein sequence. After downloading EMAS from (https://sites.google.com/site/epitopesprediction) EMAS can be run as in Fig. 2 and steps to perform the prediction can be as follow:
| • | Upload model file |
| • | Upload test data |
| • | Adjust peptide or window length |
| • | Choose peptide based |
| • | Choose input format as fasta sequence |
| • | Make output file |
| • | Click predict button to start the prediction process |
Epitopes prediction to potato leaf roll virus coat protein using EMAS: The potato leaf roll virus coat protein sequence was retrieved from GenBank (accession No. ACU80557), then EMAS run seven times with each BM models using the PLRV coat protein sequence.
| Table 3: | BM models sorted by Area er ROC curve |
 | |
| Table 4: | The score of PLRV coat protein (163:192) peptide obtained by eight BM models |
 | |
| Table 5: | Comparison between PLRV predicted epitopes with those previously obtained by Torrance (1992) and Terradot et al. (2001) |
 | |
| Underlined sequences correspond to previously detected PLRV epitopes | |
The thirty amino acids peptide which starts from position 163 to position 192 (Table 5) got high score with most BM models.
The results were match with Torrance (1992) and Terradot et al. (2001) studies, which make it one of the best candidates to be immunogenic and capable of producing antibodies that cross react with PLRV.
Table 4 represent the results of eight models with the PLRV coat protein (163:192) peptide. (Table 5) illustrate the comparison between PLRV predicted epitopes with those previously obtained by Torrance (1992) and Terradot et al. (2001).
Antiserum production against PLRV-predicted epitopes: The PLRV coat protein peptide (ARMINGVEWHDSSEDQCRILW KGNGKSSDT) from position (163) to (192) was ordered from GenScript Corporation, NJ 08854, USA.
PLRV-antiserum raised against this synthetic peptide was produced using mice for immunization and was serologically tested as described below.
Serological detection of PLRV: The produced PLRV- antiserum was tested using immune dot-blot and TAS- ELISA. Two more antisera were used for comparison: Antiserum raised against PLRV virus particles (viral antiserum) and antiserum raised against PLRV coat protein (CP antiserum).
Immuno dot-blot test: Viral, CP and synthetic peptide antisera were strongly reacted against PLRV-infected potato samples (Fig. 2, samples 1, 3 and 5, respectively). However, the reaction against the synthetic peptide using the synthetic peptide-antiserum was higher than that of the viral and CP antisera (Fig. 3, samples 6, 2 and 4, respectively). No reaction was detected against the healthy potato sample using synthetic peptide-antiserum (Samples 7, 8).
 | |
| Fig. 1: | Amino acid sequence for coat protein of PLRV in fasta format |
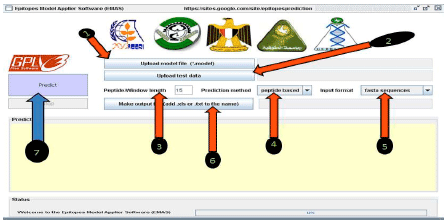 | |
| Fig. 2: | EMAS how to run |
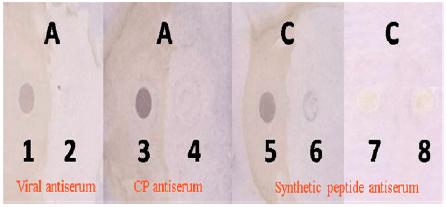 | |
| Fig. 3: | Dot-blot detection of PLRV using PLRV-antiserum produced against the synthetic peptide in comparison with two different PLRV-antisera. Dots 1, 3 and 5 are PLRV-infected potato sample. Dots 2, 4 and 6 are the synthetic peptide. Dot 7 and 8 are negative control. A, B and C are PLRV-antisera raised against the viral particles, the coat protein and the synthetic peptide, respectively |
TAS-ELISA: PLRV was specifically detected using the synthetic peptide, viral and CP antisera. No reaction was appeared with the negative control (Table 6).
| Table 6: | ELISA detection of PLRV-infected potato leaves using PLRV antiserum in comparison with two different PLRV antisera |
 | |
| 1and 2: Two different samples of PLRV- potato leaves, 3O.D. reading equal or greater than twice absorbance value of healthy controls was considered positive | |
DISCUSSION
Our approach for using computational methods for producing antibodies by predicting most immunogenic peptide in viral antigen agree with Saravanan et al. (2009), although they used another algorithm for epitopes prediction. They used antigenic index (residue-based predictors) which is calculated on a weighted scale by considering the presence of characters such as surface probability, hydrophilicity and flexibility of a given set of amino acids in the range of seven to eleven amino acids in a protein. So, Saravanan et al. (2009) method depend on physical and chemical properties only which was reported for its low performance according to Blythe and Flower (2005) but Saravanan et al. (2009) overcome the low performance of prediction method by immunization with multiple peptides.
Our method belongs to epitope-based predictors. We used machine learning algorithms (SVM and Subsequence string Kernel) which was reported for its high performance in predicting linear B- cell epitopes by El-Manzalawy et al. (2008a, b) which enable us to use single peptide in immunization but in more length (30 instead of 11) to produce more specific antibodies.
As a conclusion, results indicate that our bioinformatics strategy is a powerful tool for antibodies production. The use of epitopes prediction by computational methods has eliminated the need to obtain large amounts of viral expressed proteins or purified virus. Also, results indicate that using BM models with EMAS in the designing and choosing of immunogenic peptide are reliable and have advantages like: (1) Producing antibodies faster and cheaper; (2) Producing antibodies for any protein we have information about its sequence even we don’t have the protein itself physically. And (3) Commercialization of the produced antibodies faster and easier than antibodies produced by viral expressed proteins and cloning methods because of intellectual property rights issues related to cloning vectors.
REFERENCES
- El-Araby, W.S., I.A. Ibrahim, A.A. Hemeida, A. Mahmoud, A.M. Soliman, A.K. El-Attar and H.M. Mazyad, 2009. Biological, serological and molecular diagnosis of three major potato viruses in Egypt. Int. J. Virol., 5: 77-88.
CrossRefDirect Link - El-Manzalawy,Y., D. Dobbs and V. Honavar, 2008. Predicting flexible length linear B-cell epitopes. Comput. Syst. Bioinf. Conf., 7: 121-132.
CrossRef - El-Manzalawy, Y., D. Dobbs and V. Honavar, 2008. . Predicting linear B-cell epitopes using string kernels. J. Mol. Recognit., 21: 243-255.
PubMed - Frank, E., M. Hall, L. Trigg, G. Holmes and I.H. Witten, 2004. Data mining in bioinformatics using Weka. Bioinformatics, 20: 2479-2481.
CrossRef - Gewehr, J.E., M. Szugat and R. Zimmer, 2007. BioWeka extending the Weka framework for bioinformatics. Bioinformatics, 23: 651-653.
PubMed - Weidemann, H.L., 1988. Rapid detection of potatoviruses by dot-ELISA. Potato Res., 31: 485-492.
CrossRef - Holland, R.C., T.A. Down, M. Pocock, A. Prlic and D. Huen et al., 2008. BioJava: An open-source framework for bioinformatics. Bioinformatics, 24: 2096-2097.
CrossRefDirect Link - Peters, B., J. Sidney, P. Bourne, H.H. Bui and S. Buus et al., 2005. The immune epitope database and analysis resource: From vision to blueprint. PLoS Biol., 3: 91-91.
PubMedDirect Link - Saravanan, P., S. Shrivastava and S. Kumar, 2009. Synthesis of highly immunogenic multiple antigenic peptides for epitopes of viral antigen to use in ELISA. Int. J. Peptide Res. Therapeutics, 15: 313-321.
CrossRefDirect Link - Terradot, L., M. Souchet, V. Tran and D.G. Ducray-Bourdin, 2001. Analysis of a three-dimensional structure of Potato leafroll virus coat protein obtained by homology modeling. Virology, 286: 72-82.
PubMed - Torrance, L., 1992. Analysis of epitopes on potato leafroll virus capsid protein. Virology, 191: 485-489.
PubMed