
S.K. Balasundram
Department of Agriculture Technology, Faculty of Agriculture, Universiti Putra Malaysia, 43400 Serdang, Selangor, Malaysia
D.J. Mulla
Department of Soil, Water and Climate, Precision Agriculture Center, University of Minnesota, St. Paul, MN 55108, USA
P.C. Robert
Department of Soil, Water and Climate, Precision Agriculture Center, University of Minnesota, St. Paul, MN 55108, USA
International Journal of Agricultural Research
Year: 2007 | Volume: 2 | Issue: 11 | Page No.: 888-899







ABSTRACT
Accounting for spatial variability of soil properties commonly requires intensive soil sampling, which inevitably involves a high cost. Geo-spatial statistical tools enable characterization of spatial variability and development of sampling strategies from limited data. This study outlines a simple approach of using classical and geo-spatial statistics to understand the spatial variability of soil Phosphorus (P) and discusses its relevance to sampling strategy and variable rate P application. The Bray (I) extractable-P data, obtained from a previous study, was first explored using descriptive statistics, box plot and normal quantile plot analyses. Spatial description of the data was performed using qualitative (data posting) and quantitative (variography) methods. Information derived from the fitted semivariogram was used to perform data interpolation (kriging). A management zone concept was used to delineate the Bray P test values. Results showed that Bray P exhibited a strong spatial dependence with 94% of its variability explained. The spatial correlation length was 177 m. Spatial attributes of the data appeared to justify the sampling design employed with regard to sample size, spacing and arrangement. To facilitate variable rate P application, three management zones were established so as to receive low, moderate and high P rates, respectively.
PDF Abstract XML References Citation
How to cite this article
S.K. Balasundram, D.J. Mulla and P.C. Robert, 2007. Spatial Data Calibration for Site-Specific Phosphorus Management. International Journal of Agricultural Research, 2: 888-899.
DOI: 10.3923/ijar.2007.888.899
URL: https://scialert.net/abstract/?doi=ijar.2007.888.899
DOI: 10.3923/ijar.2007.888.899
URL: https://scialert.net/abstract/?doi=ijar.2007.888.899
INTRODUCTION
Many complex interactions occur among crop, management and environmental factors. The dynamic nature of these interactions is further affected by substantial variability in soil properties. Soil samples are collected to understand this variability. Numerous studies have been conducted to determine the degree of spatial variability and the appropriate sampling size for determination of representative soil properties. The properties studied include soil bulk density, hydraulic conductivity, infiltration and pH (Russo and Bresler, 1981; Sisson and Wierenga, 1981; Es et al., 1991; Webster and Oliver, 1992; Pierce et al., 1995). The Coefficient of Variation (CV) of these properties, except for soil pH, were in the order of 100% or greater. Mulla and McBratney (1999) tabulated typical ranges of CV values for various soil properties from a collection of published investigations based on the classification scheme of Wilding (1985) in which CV values of 0-15, 16-35 and >36% indicate low, moderate and high variability, respectively. Commonly, properties such as pH and porosity rank low in variability while those pertaining to water or solute transport rank high in variability.
In order to understand soil spatial variability, it is common to collect extensive soil samples. Often this exercise poses a cost constraint. Depending on field variability, the number of samples per 1 ha ranges from 25 to 50 for hydraulic conductivity, 7 to 14 for infiltration rate and 24 to 55 for determining solute concentration (Hajrasuliha et al., 1980; Gajem et al., 1981; Vieira et al., 1981). Additionally, the large degree of spatial variation in the field necessitates collection of soil samples from closer spacing in order to obtain an accurate estimate of a soil property. Sampling intervals as small as 1 m for hydraulic conductivity, 0.05 to 2 m for infiltration rate and 0.2 to 80 m for electrical conductivity have been suggested (Russo and Bresler, 1981; Sisson and Wierenga, 1981). The spatial variability in soil properties inevitably affects fertilizer use efficiency within a field. Studies have shown that such variability often justifies variable fertilizer recommendation, which is based on the nutrient requirements of a specific site, rather than a uniform fertilizer recommendation for the entire field (Carr et al., 1991; Robert, 2002).
Collection of data for site-specific fertilization is not only expensive but also difficult to obtain under field conditions. For this reason, geo-spatial statistical tools can be used to characterize the spatial variability and to develop sampling strategies from limited data. This study explores the statistical (classical and geo-spatial) attributes of Bray (I) extractable-P from a watershed-scale data set and attempts to extract relevant information that could potentially address issues such as sampling strategy and variable rate application for P.
MATERIALS AND METHODS
Data Acquisition
The data set used for this study was obtained from a site-specific herbicide management study (Khakural et al., 1999) conducted on a 32 ha paired mini-watershed in Blue Earth County, Minnesota. A total of 243 soil samples at 0-15 cm depth were obtained from nine South to North-oriented parallel transects (806 m long and 45.7 m apart). Geo-referenced soil samples were obtained at 30.5 m intervals. The studied area was planted to corn (1996, 1998) in rotation with soybean (1997) and comprised a wide range of soil and landscape characteristics. The following soil types were reported: Lester (loamy, Mollic Hapludalf), Shorewood (silty clay loam, Aquic Argiudoll), Cordova (clay loam, Typic Argiaquoll), Waldorf (silty clay loam, Typic Haplaquoll), Lura (silty clay loam, Cumulic Haplaquoll) and Blue Earth (silty clay loam, Mollic Fluvaquent). The slope gradient ranged from 0 to 6%.
The Bray (I) extractable-P data from the above source were spatially characterized in June of 2001.
Data Analysis
Descriptive statistics were computed using Microsoft Excel. The 5-parameter summary consisting of the smallest observation, the first quartile, the median, the third quartile and the largest observation was graphed as a box plot. Supplementary to the box plot, a normal quantile plot was constructed to describe data distributions. Both plots were generated using Statistix Version 1.0. Outlier testing was performed using the Extreme Studentized Deviate (ESD) method, also known as Grubbs’ Test.
Spatial description of the data was performed in two stages, viz. 1) exploratory analysis and 2) spatial continuity analysis. Data posting was used as the exploratory tool. According to Isaaks and Srivastava (1989), data posting is a useful way to check for simple trends in the data i.e., with regard to location of minimum and maximum values. The data posting in the form of symbol map was created using Surfer Version 7.0 (Golden Software, Inc.). Exploratory analysis using data posting provides a qualitative spatial description. This tool, however, does not address spatial continuity as a function of distance and direction, which exists inherently in most earth science data sets. Isaaks and Srivastava (1989) suggested three methods that describe spatial continuity, viz. correlation function, covariance function and variogram. Among these, the variogram has often been the most exploited method. Variograms quantify and model spatial dependence of soil properties using semivariance (Burgess and Webster, 1980). The semivariogram, which basically measures the increase in variance between sample points as separation distance increases, can be estimated as follows:
| (1) |
where,
| h | = | Separation distance between location xi or xi+h, |
| zi or zi+h | = | Measured values for the regionalized variable at location xi or xi+h, |
| n (h) | = | No. of pairs at any separation distance h |
Theoretically, the semivariogram equals the population variance at large separation distance whereas at very small separation distance, the semivariogram approximates zero (Trangmar et al., 1985). In practice, the semivariogram is modeled using several authorized models (Oliver, 1987; Isaaks and Srivastava, 1989) such as linear, spherical and exponential. These models are then fitted to the semivariogram data. An exhaustive discussion on the characteristics of various models and how they are fitted to the semivariogram data can be found in the works of Trangmar et al. (1985), Isaaks and Srivastava (1989), Mulla and McBratney (1999) and McBratney and Pringle (1999). Key features of a semivariogram model are described by three parameters, namely nugget (C0), sill (C0 + C) and range (Ao). Definitions of these parameters, based on Trangmar et al. (1985) and Isaaks and Srivastava (1989), are summarized as follows: Nugget is a measure of the amount of variance imposed by errors in sampling, measurement and other unexplained source(s) of variance. Sill refers to the total vertical scale of the variogram whereby the semivariance becomes constant as distance between sample location increases. The sill approximates the sample variance at large separation distances for stationary data. Range is the separation distance that reflects a cutoff between spatial dependence and spatial independence. This implies that at separation distances greater than the range, sampled points cease to be spatially correlated (i.e., random). Semivariogram analysis was performed using GS+Version 5.1.1 (Gamma Design Software).
Classical and geo-spatial statistics can be used for more than just to describe the sample data. In addition, they can be used to predict values in areas that have not been sampled. This process is known as interpolation. Several interpolation methods are available and their appropriateness for use would depend on the estimation criteria. For univariate data sets, a common interpolation method is point kriging. Kriging has the characteristics of Best Linear Unbiased Estimator (BLUE). According to Isaaks and Srivastava (1989), kriging exhibits linearity because its estimates comprise weighted linear combinations of the available data. Meanwhile, it is unbiased since it tries to nullify the mean residual value (error) and it is best because it aims at minimizing the variance of the error. The latter serves as the distinguishing feature of kriging. Detail discussions on the use of kriging as an interpolation tool can be found in Trangmar et al. (1985), Isaaks and Srivastava (1989) and Mulla and McBratney (1999). Interpolated data, Z(xo), are obtained from the following expression:
| (2) |
where,
| N | = | No. of neighboring measured data points used for interpolation |
| Z(xi) | = | Measured data for Bray P at locations neigboring the interpolation point |
| λi | = | Weighting factor which depends on the semivariogram model |
The Bray P data were point-kriged based on properties of the semivariogram model using Surfer Version 7.0 (Golden Software, Inc.).
RESULTS AND DISCUSSION
Classical Statistics
The mean for Bray P is 19.27 while the standard deviation is 25.91 (Table 1). The Coefficient of Skewness (CS) is positive, indicating a distribution that has a long tail of high values to the right that makes the median less than the mean. The CV of 134% falls within the typical range reported by Mulla and McBratney (1999). The curve on the normal quantile plot shows a clear deviation from normality (Fig. 1), which suggests the presence of some erratic high sample values in the data. These values could potentially disrupt the final estimates. The box plot exhibits 8 probable outliers (Fig. 2). Based on the outlier test, 4 data points in the upper range tested significant at p = 0.05 and hence were omitted from the data set.
| Table 1: | Descriptive statistics for original data set |
 | |
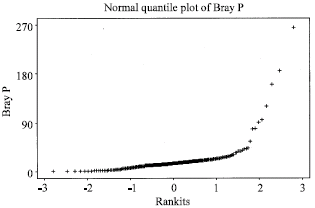 | |
| Fig. 1: | Normal quantile plot of original data set |
 | |
| Fig. 2: | Box plot of original data set |
As a result of trimming the Bray P data, descriptive statistics and normal quantile plot were re-computed (Table 2 and Fig. 3, respectively). Discarding the 4 outliers clearly reduces the numeric value of most statistical parameters. Notably, standard error, standard deviation, CV and CS were approximately halved, while sample variance was slashed 4-fold (Table 2). However, the trimmed data fails to show substantial improvement toward normality due to a few high values at the upper range (Fig. 3). The two options of dealing with such deviation from normality before proceeding to the next analytical step are: 1) to assume that the data are normal or 2) to perform data transformation. For the purpose of clarity, option 2 was explored.
Data transformation using the natural log was compared for normality with the original and the outlier-free data sets (Fig. 4). In comparison to Fig. 3, it appears that the natural log transformation, particularly without the outliers (Fig. 4b), renders reasonable improvement toward normality. As such, the transformed Bray P data with four discarded outliers were used for subsequent data analysis. The transformed data set registered the following statistics: mean (2.643), standard deviation (0.696) and sample variance (0.485).
The elements of classical statistics such as descriptive statistics, box plot and normal quantile plot, are among several ways of summarizing a univariate distribution. While the mean and variance are useful statistics that provide measures of the location and spread of the distribution, respectively, they do not describe the data from a spatial context. To capture spatial features of the data, geo-spatial statistics are commonly employed.
Geo-Spatial Statistics
Data posting for transformed Bray P, represented as a symbol map, is shown in Fig. 5. The symbol map is characterized by five classes of data values, which are arbitrarily referred to as low, somewhat low, moderate, somewhat high and high.
| Table 2: | Descriptive statistics for outlier-free data set |
 | |
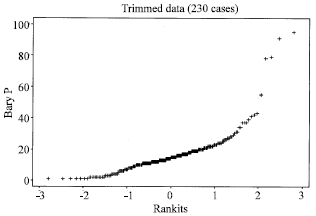 | |
| Fig. 3: | Normal quantile plot of outlier-free data set |
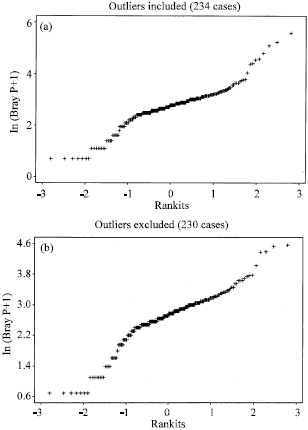 | |
| Fig. 4: | Transformed data sets compared: (a) original and (b) outlier-free |
These classes were generated using the equal interval binning method, which assigns the class ranges such that the interval between the minimum value and the maximum value is equal for each class. As a result, this method inevitably assigns different numbers of points for each class. The majority (54.3%) of data values were classed as moderate, followed by somewhat high (24.3%), somewhat low (10.4%), low (8.7%) and high (2.2%). The moderate values appear evenly distributed. In contrast, values ranging from low to somewhat low are clustered within the east central-northeast trough. Apparently, there are no isles of high values surrounded by low ones and vice-versa. The blank stretch along the western boundary is reflective of the four discarded high values. In general, there is no obvious data trend for transformed Bray P.
The semivariogram fitted for transformed Bray P is shown in Fig. 6 and its corresponding properties are given in Table 3. In constructing the semivariogram, several assumptions were adhered to. To begin with, the data were assumed to follow a normal distribution substantiated by Fig. 4b. As a result, the semivariances were also assumed to obey a normal distribution. Besides normality, the data were assumed to be stationary and free from any form of trend supported by Fig. 5. Stationarity of the data upholds the fact that the semivariance between any two locations in the study region depends only on the distance and direction of separation between the two locations and not on their geographic location. The semivariogram was assumed to be isotropic and omnidirectional, meaning that pairwise squared differences were averaged without regard to direction. Spatial structure of the data conformed to the exponential model, which is:
| (3) |
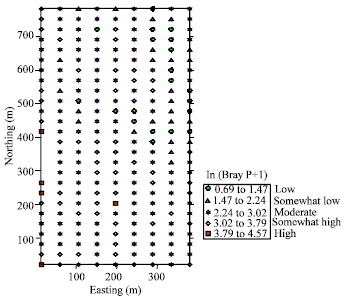 | |
| Fig. 5: | Classed data posting |
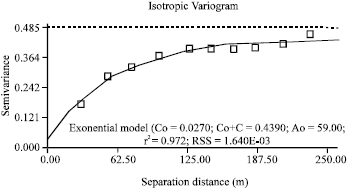 | |
| Fig. 6: | Semivariogram fitted with an active lag of 250 m and a lag class interval of 23.5 m |
| Table 3: | Semivariogram properties |
 | |
| a: Random variation, b: Total variation, c: Structural variation, d: Commonly defined as the point at which the model includes 95% of the sill | |
| where, | ||
| h | = | Lag class interval |
| C0 | = | Nugget variance (≥0) |
| C | = | Structural variance (≥C0) |
| A0 | = | Range |
Spatial dependence was defined using the nugget to sill ratio method of Cambardella et al. (1994) whereby:
 |
Based on the above definition, the Bray P data, which yielded a nugget to sill ratio of 0.06, is categorized as having strong spatial dependence. This physically means that 94% of the total variation in the Bray P data can be explained while the remaining 6% is attributable to random or unexplained sources of variation. The effective range of 177 m falls within the range tabulated by Mulla and McBratney (1999).
Implications for Sampling Design
Good statistics is often about making accurate and reliable inferences from the data, which are usually generated by sampling an unknown population. To derive a rigorous sampling protocol, it is necessary that the sampling points closely represent the population. To this end, the sample mean is assumed to provide a very good estimate of the population mean. Wollenhaupt et al. (1997) advocated that a sampling protocol should consider two important facts, viz. the optimal number of samples and the spatial arrangement of samples.
Sample Size
Optimal number of samples can be estimated using the inference concept (Moore and McCabe, 1999). It follows that:
| (4) |
where,
| n | = | The estimated sample size, |
| z* | = | The critical value which depends on the confidence level, |
| σ | = | The estimated Standard Deviation (SD) of the population and D is the desired margin of error. |
Since the population variance is often an unknown parameter, the sample standard deviation is assumed as the best estimate. With reference to Table 2, the standard deviation for Bray P (with four outliers removed) is 12.7. Based on Eq. 4, if the desired margin of error is set at D = 1, the sample size (n) required to estimate the mean of Bray P at 95% Confidence Interval (CI) would be 620. When D = 3, n would be 49 and when D = 10, n would be 4. This indicates that to achieve a small margin of error, a large sample size would be required. Typically, the D that corresponds to a 95% CI for a given data set is an acceptable compromise. For the 230 sample Bray P data, the values of D at varying confidence intervals are as follows:
 |
As such, it is reasonable to consider the 230 samples collected to characterize the population mean of Bray P as optimal. When spatial correlation is expected, estimation of sample size is modified to account for the fact that spatial correlation will entail a larger sample size to estimate the population mean (Mulla and McBratney, 1999).
Sample Spacing
The effective range, also referred to as the correlation length (Webster, 1985), derived from semivariogram analysis is 177 m. The practical significance of this value is that sample points separated at distances greater than 177 m will no longer exhibit spatial correlation. At this juncture, it is worth noting that the semivariogram does not provide any information for distances shorter than the minimum spacing between samples. Sampling designs that are aimed at delineating spatial structures usually employ separation distances that are lesser than the effective range. Flatman and Yfantis (1984) recommended that samples be spaced between 0.25 and 0.5 of the effective range. In the Bray P data, samples were spaced 45.7 m apart in the x direction and 30.5 m apart in the y direction. This sample spacing corresponds to 0.26 and 0.17 of the effective range for the x and y direction, respectively. The high CV (77%) probably justifies the close spacing in the Bray P data. Close spacing is also a way to minimize the nugget effect. Due to the assumption that the semivariogram was isotropic, the difference in spatial variation as affected by direction (x or y) was not explored.
Sample Arrangement
The sampled plot, as shown in Fig. 5 (data posting), is rectangular in shape. To accommodate the optimal sample size and required spacing, sampling points appeared as regular rectangular grid cells with a marginally greater dimension on the x direction. Clearly, the sample arrangement reflected a systematic sampling scheme. Each sample point is a composite of several subsamples, which were obtained in a randomized manner within each grid cell. The optimum number of subsamples would depend on the CV and the shape of the semivariogram. Rectangular grid cells are usually prescribed in situations where the sampled variable is believed to exhibit anisotropy as a result of topographic, tillage or other types of influences (Mulla and McBratney, 1999). The symbol map of Bray P (Fig. 5a) indicates a clear short range variability in north-south direction of the eastern region, which probably justifies the use of a rectangular grid cell instead of the more frequently used square grid cell.
Interpolation
Distribution and pattern of Bray P values (both measured and interpolated) are illustrated as a contour map with an accompanying color gradation scheme in Fig. 7. Back-transformation of Bray P values was performed using an exponential function as follows:
| (5) |
Features noticed in the preceding symbol map (Fig. 5) appear clearer in the contour map. For instance, the east central–northeast trough is readily apparent in the contour map. An additional feature, undetected in the symbol map, is the proximity of contour lines along the trough that indicates a relatively steep gradient in data values. This gradient approximately corresponds to the close distance between low and moderate values, suggesting short-range variability. The dotted line represents the stretch that exhibits minimum continuity.
Variable Rate Application
From Fig. 7, it is clear that soil test values for Bray P are variable across the field. In such a situation, P fertilization using a homogeneous rate for the whole field does not make sense. A plausible option would be to vary the P rates as a function of soil test value. To perform variable rate application, firstly, the field has to be divided into zones that are relatively homogeneous in soil test P. Then, each of these zones should be fertilized with P at specific rates that correspond to the test values.
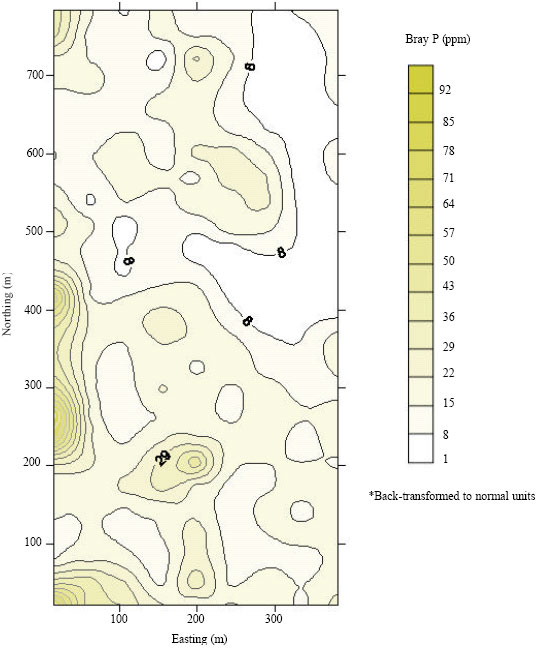 | |
| Fig. 7: | Contour map of P concentration |
Accurate and efficient aggregation of the field into management zones will require an open architecture Geographic Information System (GIS). The use of GIS to manage soil attribute(s) differently is a key component of Precision Agriculture (Larson and Robert, 1991; Robert, 2002), a technology-driven process that enables farm operators to adjust input use to match varying soil, crop and other field attributes.
Based on the contour map (Fig. 7), the eastern region of the field appears to be dominated by lower test values, while the reverse is true for much of the western region. Using the contour map, a cursory approach to aggregating the field is showen in Fig. 8. The field is aggregated into three P management zones where Zone B has the largest acreage followed by Zone C and Zone A. Fertilization of P could be carried using three different rates based on soil test values. Typically, zones A, B and C would receive the lowest, medium and the highest P rate, respectively.
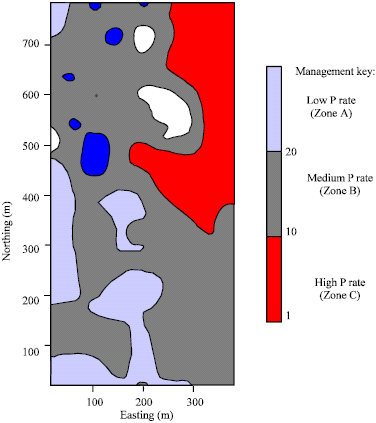 | |
| Fig. 8: | Proposed P management zones |
CONCLUSION
A simplified approach to quantifying and managing the spatial variability of soil P has been described. Soil test values ranged between 1 and 95 ppm with a CV of 77%. Soil P exhibited a strong spatial dependence with 94% of its variability explainable. This spatial dependence was characterized by a moderate range of 177 m. Generally, the sample size, spacing and arrangement were appropriate for the manifested variability. Site-specific P fertilization using three different rates is proposed.
ACKNOWLEDGMENTS
The authors are grateful to Dr. Bhairav R. Khakural and his co-workers for permission to use the Bray P data set. Their project was funded by USDA-CSREES Grant No. 95-37102-2174 and Minnesota Soybean Research and Promotion Council.
REFERENCES
- Burgess, T.M. and R. Webster, 1980. Optimal interpolation and isarithmic mapping of soil properties. I. The semivariogram and punctual kriging. J. Soil Sci., 31: 315-331.
CrossRef - Cambardella, C.A., T.B. Moorman, J.M. Novak, T.B. Parkin, D.L. Karlen, R.F. Turco and A.E. Konopka, 1994. Field-scale variability of soil properties in central Iowa soils. Soil Sci. Soc. Am. J., 58: 1501-1511.
CrossRefDirect Link - Flatman, G.T. and A.A. Yfantis, 1984. Geostatistical strategy for soil sampling: The survey and the census. Environ. Monit. Assess., 4: 335-349.
Direct Link - McBratney, A.B. and M.J. Pringle, 1999. Estimating average and proportional variograms of soil properties and their potential use in precision agriculture. Precision Agric., 1: 125-152.
CrossRefDirect Link - Oliver, M.A., 1987. Geostatistics and its application to soil science. Soil Use Manage., 7: 206-217.
Direct Link - Trangmar, B.B., R.S. Yost and G. Uehara, 1986. Application of geostatistics to spatial studies of soil properties. Adv. Agron., 38: 45-94.
CrossRefDirect Link - Webster, R. and M.A. Oliver, 1992. Sample adequately to estimate variograms of soil properties. J. Soil Sci., 43: 177-192.
Direct Link