
I.A. Iwok
Department of Mathematics/Statistics, University of Port-Harcourt, P.M.B. 5323, Port-Harcourt, Rivers State, Nigeria
Asian Journal of Mathematics & Statistics
Year: 2016 | Volume: 9 | Issue: 1-3 | Page No.: 6-10







ABSTRACT
Background: This study proposed a method for the estimation of missing values in a stationary autoregressive (AR) process and proved the unbiasedness of the obtained estimate. Materials and Methods: Box and Jenkins autoregressive integrated moving average (ARIMA) was employed for order selection in the analysis. Absolute deviation of estimates from actual values was used as basis of comparisons with existing methods. Results: The result showed that the proposed method provides better estimates than the existing methods. Minimum mean square error of the estimate was also obtained theoretically and the estimate was found to be unbiased. Conclusion: Since the estimate obtained by this method is found to be unbiased, the method has offered another framework of with missing values in a stationary autoregressive (AR) process.
PDF Abstract XML References Citation
Received: May 11, 2016;
Accepted: May 27, 2016;
Published: June 15, 2016
How to cite this article
I.A. Iwok, 2016. Method of Estimating Missing Values in a Stationary Autoregressive (AR) Process. Asian Journal of Mathematics & Statistics, 9: 6-10.
DOI: 10.3923/ajms.2016.6.10
URL: https://scialert.net/abstract/?doi=ajms.2016.6.10
DOI: 10.3923/ajms.2016.6.10
URL: https://scialert.net/abstract/?doi=ajms.2016.6.10
INTRODUCTION
One of the serious problems faced in data collection and analysis is missing observations. Nature does not always provide a complete data set, hence, the mechanism for observing time series is often imperfect. Equipment failure, human error or the disregarding of inaccurate measurements can introduce missing values. In statistics, analysis is often carried out with complete observations. Where any observation is missing either by natural or human error, the missing value has to be estimated to complete the observations before an analysis is carried out.
According to Abraham and Thavaneswaran1, data that are known to have been observed erroneously can fairly be categorised as missing. By this classification, erroneous data is believed to wreak havoc with the estimation and forecasting of linear and non linear time series models. In their study, two methods for estimating missing observations; one using prediction and fixed point smoothing algorithms and the other using optimal estimating equation theory were identified. Recursive estimation of missing observations in an autoregressive conditionally heteroscedastic (ARCH) model and the estimation of missing observations in a linear time series were shown as special cases. Using these methods, construction of optimal estimates of missing observations was obtained.
Phong and Singh2 proposed modelling gene expression profiles as simple linear and Gaussian dynamical systems and applied the Kalman filter to estimate missing values. In their study, they discovered that while other current advanced estimation methods are either sensitive to parameters with no theoretical means of selection. Their approach was advantageous because it makes minimal assumptions that are consistent with the biology. The efficiency of the approach was demonstrated by evaluating its performance in estimating artificially introduced missing values in two different time series data set and was compared with a Bayesian approach dependent on the eigen vectors of the gene expression matrix as well as a gene wise average impartation for missing values.
Tight et al.3 established the applicability of time series and influence function techniques in the estimation of missing value and detection of outliers. They went further and made cooperative assessment of new techniques with those used by traffic engineers in practice for local, regional or national traffic count systems. Their result showed that the replacement values derived from the ARIMA model using residuals were found to be most accurate.
Maravall and Pena4 proposed the estimation of missing observations in possibly non stationary ARIMA models, where the models was assumed known and the structure of the interpolation filter was analysed using the inverse autocorrelation function, it was shown that the estimation of a missing observation is analogous to the removal of an outlier effect. Both were closely related with the signal plus noise decomposition of the series. The results were extended to the case of missing observation near the two extremes of the series, the case of a sequence of missing observations and finally to the general case of any number of sequences of any length of missing observations.
For a stationary series, the problem of interpolating missing values given an infinite realization of the stochastic process was solved by Grenander and Rosenblatt5 and Wei6. The interpolator was obtained as the expected value of the missing observation given the observed infinite realization of the series. For many years, however, their result was not extended to the more general problem of interpolation in a finite realization of a possibly non stationary time series generated by a model with unknown parameters4.
Xia et al.7 examined 6 methods for estimating missing climatological data for different time scales at 6 German weather stations and 3 Bavarian forest climate stations. It was discovered that the multiple regression technique predominantly gave the best estimation under different topographical conditions.
Anava et al.8 studied the problem of time series prediction using AR model in the presence of missing data. The signal and missing data were set to be arbitrary. The problem was cast as an online learning problem in which the goal of the learner was to minimize prediction error. An efficient algorithm for the problem was devised which was based on autoregressive model and does not assume any structure on the missing data nor on the mechanism that generates the time series. The result showed that the algorithm’s performance asymptotically approaches the performance of the best AR predictor in hind right and corroborate the theoretic results with an empirical study on synthetic and real world data.
Ahmed and Al-Khazaleh9 proposed new method of estimating missing data using the filtering process. The filtering process involved substituting various correlations in the weights of moving average model. The results obtained were checked with Naïve test and were found to be good.
There are quite a number of methods for dealing with missing observations. The commonest ones are: (i) Replacing the missing observation with the mean of the series, (ii) Replacing it with the Naïve forecast which uses the current time periods value for the next time period, (iii) Replacing it with a simple trend forecast and (iv) Replacing it with an average of the last two known observations that bound the missing observation9. These methods are simple and most times provides better estimates than some of the complex methods outlined by some authors above.
MATERIALS AND METHODS
Stationarity: A time series is said be stationary if the statistical properties are essentially constant through time. In order words, a series Xt is said to be stationary if for any admissible time points t1, t2, ...., tn and any k, all the joint moments up to order 2 of ![]() exist and is equal to the corresponding joint moments up to order 2 of
exist and is equal to the corresponding joint moments up to order 2 of ![]()
Given an autoregressive process of order p [denoted AR (p)]:
![]()
The stationarity condition is that the roots of the characteristic equation:
![]()
must lie outside the unit circle.
Autocorrelation function (ACF) and partial autocorrelation (PACF): The order (p) of a model is identified by examining the behaviour of the autocorrelation and partial autocorrelation function for the values of a stationary time series. For an AR process, the pacf cut off after lag p, while its autocorrelation function is infinite in extent and consists of a mixture of damped exponentials and/or damped sine waves10.
Missing value approach: Suppose the data with the missing value is being generated by an autoregressive (AR) process of order p. That is:
![]()
where, ![]() are the AR parameters and B is the backward shift operator.
are the AR parameters and B is the backward shift operator.
Let us consider a time series Xt with n observations. Let the ith value of Xt be missing. Let the missing value xi be such that the values xi-1, xi-2, ..... , xi-p exist; where, p is the order of the series xi, xi+1, .... , xn.
This method proposes that an AR (p) model be fitted to the series xi, xi+1, .... , xn. Suppose the resulting model is:
![]()
Then the missing value is estimated at the first step as:
![]()
The value ![]() obtained is then substituted at the missing position in the data and the analysis is repeated using the entire data
obtained is then substituted at the missing position in the data and the analysis is repeated using the entire data ![]() to obtain a new model with different parameters:
to obtain a new model with different parameters:
![]()
The final value of xi is re-estimated as:
![]()
RESULTS
The above proposed method is illustrated using Blowfly time series data6. There are n = 82 number of observations. Now, suppose the 5th observation x5 = 4424 is missing. A time series model is first fitted to the series x6 = 2784 to x82 = 4066. Following the nature of the autocorrelation function and partial function (using Minitab software), the series is said to follow a AR (1) process giving the model:
Xt = 0.986430Xt-1+εt
This gives the first estimate of x5 to be:
![]()
The second step involves replacing this estimate in its missing position and re-applying the Box-Jenkins method to the entire data to obtain the new model:
Xt = 0.982933Xt-1+εt
This gives the final estimate of x5 to be:
![]()
| Table 1: | Estimates of the missing values and their errors |
 | |
Thus, any missing observation xi can be estimated using:
![]()
Stationarity of the AR (1) process: For this process, the root of auxiliary equation is:
(1-0.982933B) = 0
⇒ B = 1.01736334>1
Thus, the process is stationary.
Comparison of some old methods with the new method: A comparison of the various methods of estimating missing values in time series with the new proposed method is made. This is going to be assessed by the Absolute Deviations (AD) of the estimated values of the different methods from the actual values in the raw data. This absolute deviations will be called errors. However, few existing methods that are simple in computation and are within the reach of our software will be considered for comparison. The following methods with abbreviations will be compared: Kalman Filter (KF), Influence Function (IF), replacing with mean of the series (M), Naïve Forecast (NF), simple Trend Forecast (TF), average of the last two known observations that bound the missing observation (A), Interpolation (I) and the New Method (NM).
The missing values created at different positions in the Blowfly data set are presented in Table 1. The actual values removed at the different positions to create the missing observations were randomly selected. The estimates provided by the different estimation methods are also presented and the calculated errors (AD) are placed in brackets under each estimate.
In Table 1, it is clearly shown that the New Method (NM) has the smallest errors in all the estimates. This means that amongst all the estimation methods considered, the new method provides the best estimates. Next, the minimum mean square error of the estimate is obtained theoretically and the estimate is shown to be unbiased.
Minimum Mean Square Error (MMSE) and unbiasedness of the estimate: To obtain the MMSE, the variables are treated as random variables and the series Xt is assumed to be stationary with mean, μ = 0. It is already known that if {Xt} is stationary and follows an AR (p) process, then it can be converted to an infinite Moving Average (MA) process. That is an AR (p) series Xi can be written:
| (1) |
![]()
where, ![]() and ψ0 = 1.
and ψ0 = 1.
| (2) |
where, εi ∼NIID (0, ![]() ).
).
Since, Xi is a linear of the current and previous random shocks (the εi’s), then the estimate ![]() is also a linear of the current and previous shocks. Thus, it can be written:
is also a linear of the current and previous shocks. Thus, it can be written:
![]()
Using (2) and noting that E [εi εi] = ![]() and E [εi εj] = 0, the mean square error of the estimate can be obtained as:
and E [εi εj] = 0, the mean square error of the estimate can be obtained as:
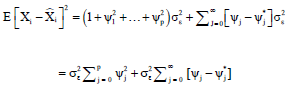
which is minimised by setting ![]()
Hence, from Wold’s decomposition11:
![]()
Which can be written as:
![]()
where, ei = εi+ψ1εi-1+…+ψpεi-p is the error of the estimate. Since E [ei] = 0, the estimate ![]() is unbiased.
is unbiased.
DISCUSSION
The study of Anava et al.8 clearly shows that their algorithm must have been applied to a wrong data. This is because they did not consider the underlying mechanism of the data before they cast an online learning problem in which the goal of the learner was to minimize prediction error. This study, however has determined the underlying structure of the data to be of ARIMA type before the application was made. Besides, the aforementioned researches of the subject matter in the review were based only on empirical methods. This study has substantiated its result with theoretical backings.
CONCLUSION
In essence, this study has proposed a method of estimating missing values in a stationary autoregressive (AR) process. Comparative study was carried out with other existing methods and the new method was found to provide the best estimates. To support this, a theoretical proof showed that the estimate obtained is unbiased. Hence there is no gain saying that this method offers another possibility of estimating missing values in a stationary autoregressive (AR) process.
REFERENCES
- Abraham, B. and A. Thavaneswaran, 1991. A nonlinear time series model and estimation of missing observations. Ann. Instit. Statist. Mathem., 43: 493-504.
CrossRefDirect Link - Xia, Y., P. Fabian, A. Stohl and M. Winterhalter, 1999. Forest climatology: Estimation of missing values for Bavaria, Germany. Agric. Forest Meteorol., 96: 131-144.
CrossRefDirect Link - Ahmad, M.R. and A.M.H. Al-Khazaleh, 2008. Estimation of missing data by using the filtering process in a time series modeling. Electron. J. Statist.
Direct Link