
A. Al-Radaideh
Dipartimento di Scienze Pedagogiche, Psicologiche e Didattiche, Decorate Course in Sciences of the Mind and Human Relations, Universit� del Salento, Lecce, Italia
A. Al-Nasser
Department of Statistics, Science Faculty, Yarmouk University, Irbid, Jordan
E. Ciavolino
Dipartimento di Filosofia e Scienze Sciali, Universit� del Salento, Lecce, Italia
Asian Journal of Mathematics & Statistics
Year: 2010 | Volume: 3 | Issue: 2 | Page No.: 82-92







ABSTRACT
In this study, a new sampling technique called L Ranked Set Sampling (LRSS) was used to estimate the Error in Variable Model (EIV) parameter using Wald-type estimators. The new estimators were made in order to reduce the cost and increase the efficiency of the estimators. The new formulas of the Wald type estimators are shown to be unbiased towards the EIV model and are evaluated by comparing LRSS with Simple Random Sampling (SRS) and Ranked Set Sampling (RSS). Two Monte Carlo experiments were considered to study the performance of Wald-type estimators with the three sampling techniques. It appears that the suggested estimators based on LRSS are more accurate and more efficient. Moreover, a real data set of student achievements is studied.
PDF Abstract XML References Citation
How to cite this article
A. Al-Radaideh, A. Al-Nasser and E. Ciavolino, 2010. Efficient Wald Type Estimators for Simple Linear Measurement Error Model. Asian Journal of Mathematics & Statistics, 3: 82-92.
DOI: 10.3923/ajms.2010.82.92
URL: https://scialert.net/abstract/?doi=ajms.2010.82.92
DOI: 10.3923/ajms.2010.82.92
URL: https://scialert.net/abstract/?doi=ajms.2010.82.92
INTRODUCTION
The ability to understand causes and predict outcomes of events is critical in business, medicine, education, government and in fact, nearly every facet of our lives. We intuitively have the ability to detect that variables are related. The concepts of regression, however, provide us with a means to establish concrete evidence of such relationships. Simple linear regression is a powerful tool that can be used in several ways. It can be used to describe populations or to make predictions about other subjects in the population or even to test causal hypotheses. However, it is important to note that in the simple linear regression model its assumed that the explanatory variable X is measured exactly without errors. However, in most regression problems, measurement errors affect the explanatory and the response variable (Fuller, 1987). To illustrate the effect of measurement errors on explanatory variables suppose that ξ and η are two variables having a relationship as in the following form:
| (1) |
These two variables (ξ and η) are measured with random errors, where the observed values (x, y) are given by:
| (2) |
| (3) |
The ε and δ are the random errors assumed to be mutually independent with known means and unknown variances (σ2, τ2), respectively. The model given in the equations is well known in the literature as Errors in Variables (EIV) model.
There are many methodologies to estimate the unknown parameters α and β for the EIV model suggested in the literatures, the easiest is the Grouping Methods (GMs) which were proposed by Wald (1940) and Bartlett (1949), also known from the name of the researchers, Wald type estimators.
Alternative EIV model estimation methods such as the least square, method of moment, maximum likelihood, instrumental variable and generalized maximum entropy, have been suggested by Madansky (1959), Kendall and Stuart (1979), Fuller (1987), Cheng and Van Ness (1999) and Al-Nasser et al. (2005).
In this study, we adopt the Wald-type estimators for the estimation of EIV model parameters, by combining with the new sampling technique called L Ranked Set Sampling (LRSS), proposed by Al-Nasser (2007) that can improve the efficiency of Wald type estimators.
As well as improving the efficiency, there are some practical situations that the combination of the EIV model and LRSS can help to solve.
For instance, Chen and Wang (2004), in their application showed that SRS cannot be used because of the high cost and time involved in SRS, so in these cases, they proposed RSS as a more suitable sampling scheme. Moreover, in this kind of application such as genetics, ecological and environmental studies, all the variables are affected by measurement errors so the use of EIV model will be appropriate for the estimation of the parameters.
WALD-TYPE ESTIMATORS
In order to fit a straight line when both variables are measured with error, the GMs is first proposed by Wald (1940), which is simpler than the other methods and hence or otherwise may easily be applied in many practical problems, especially in economics.
The grouping estimators, as we said, are also well known as Wald-type estimators. Suppose that we have two variables X, Y and n pairs {(xi, yi), I = 1, 2,…, n}, then the grouping methods can be described by the following steps:
| Step 1: | Order the n pairs (xi, yi), by the magnitude of xi; for all the n observations. |
| Step 2: | Select proportions P1 and P2 such that P1+P2≤1, place the first nP1 pairs in group one (G1) and the last nP2 pairs in another group (G3) and discarding G2 the middle group of observations; that is to say: |
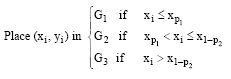 | (4) |
where, xpi is the pi percentile. The slope can be estimated or formulated as follows:
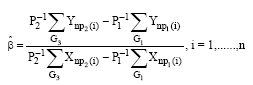 | (5) |
Consequently, the intercept estimator will be:
| (6) |
Noting that when P1=P2=1/2 then the grouping method is called two group (Wald, 1940) and when P1 = P2 = 1/3 then the method is called three group (Nair and Shrivastava, 1942; Bartlett, 1949).
L RANKED SET SAMPLING FOR BIVARIATE DATA
In the early 1950’s, McIntyre (1952) without mathematical proof introduced a sampling method known as Ranked Set Sampling (RSS). This technique was introduced as an efficient alternative method to simple random sampling for estimating expected pasture yields. In McIntyre’s case, measuring the plots of pasture yields requires moving and weighting crop yields which is time-consuming. However, a small number of plots can be sufficiently well ranked by eye without actual measurement. He suggested that using RSS to estimate population mean gives an unbiased estimator with smaller variance than the estimator produced by a simple random sample of the same size. Therefore, since the ranking could be done with negligible cost, he developed the RSS technique to implement this advantage.
Al-Nasser (2007) proposed a robust procedure based on L statistics, which is denoted by LRSS for detecting outliers, which a generalization for many types of RSS that introduced in the literature for estimation of the population mean. Based on the LRSS scheme, the estimator of the population mean when r = 1 is defined as:
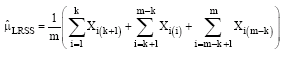 | (7) |
and its variance is given by:
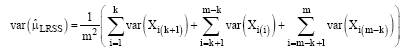 | (8) |
where, m is the set size, r is the number of cycles and k is the LRSS coefficient.
Al-Nasser (2007) proved that ![]() is an unbiased estimator of the population mean μ and has smaller variance than
is an unbiased estimator of the population mean μ and has smaller variance than ![]() if the underlying distribution is symmetric. Later, Al-Nasser and Al-Radaideh (2008) extend LRSS from an univariate sampling method to a bivariate sampling method in order to estimate the intercept and the slope for the simple linear regression model; they showed that the use of LRSS, especially with the data that have some outliers, gives more efficient estimates for the parameters. In this study, LRSS is combined with the Wald-type estimator in case the regression model considers that the error may have occurred on both dependent and independent variables.
if the underlying distribution is symmetric. Later, Al-Nasser and Al-Radaideh (2008) extend LRSS from an univariate sampling method to a bivariate sampling method in order to estimate the intercept and the slope for the simple linear regression model; they showed that the use of LRSS, especially with the data that have some outliers, gives more efficient estimates for the parameters. In this study, LRSS is combined with the Wald-type estimator in case the regression model considers that the error may have occurred on both dependent and independent variables.
The general idea of LRSS for choosing a bivariate sample from a population, where the response variable is too expensive to measure but the predictor variable can be measured easily, can be briefly shown in the following steps:
| Step 1: | Randomly draw m independent sets each of size m bivariate sampling units |
| Step 2: | Rank the units within each sample with respect to the X’s by visual inspection or any other cheap method |
| Step 3: | Select LRSS coefficient, K = [mp] such that 0 = p<0.5 and [z] is the largest integer value less than or equal to z |
| Step 4: | For each of the first (k+1) ranked samples, select the unit with rank k+1, x(k+1)i and select the corresponding Y, say y[k+1]i |
| Step 5: | For j = k+2,…, m-k-1, the unit with rank j in the jth ranked sample is selected |
| Step 6: | With respect to the first characteristic, the procedure continues until (m-k)th unit is selected from the each of the last (k+1) ranked samples and the corresponding y value is measured |
The steps can be repeated r times in order to choose the required sample size n = (r•m) and it can be noted that, for any set size when K = 0, the steps will lead to the novel RSS, McIntyre’s procedure, also for a set size m with K = [(n-1)/2], then the selected sample leads to the traditional MRSS. Moreover, PRSS can be also considered as a special case of LRSS.
WALD-TYPE ESTIMATORS BASED ON LRSS
Here, instead of using the regular SRS method to estimate the EIV model parameter, we introduce the two group and the three group estimators using the samples taken by using the LRSS method, which will be easier to use in the applications in cases where, the researcher has difficulty in measuring the study units and we also confirm that the proposed estimators based on LRSS are unbiased estimators. Now in order to fit the EIV model, let:
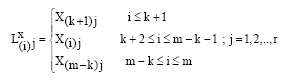 | (9) |
be LRSS of X variable and
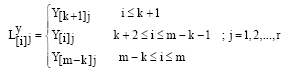 | (10) |
are the corresponding observed values obtained from the response variable Y. Then, using Eq. 4 and 5; the two group estimates can be identified as:
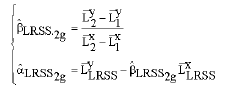 | (11) |
Similarly; the three group estimates can be formulated as:
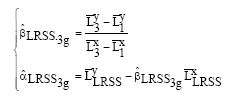 | (12) |
Theorem: Assuming that model in Eq. 1-3 is satisfied, then the grouping estimators based on LRSS given in Eq. 11 are unbiased.
Proof:
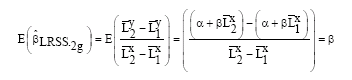 |
With associated variance given as:
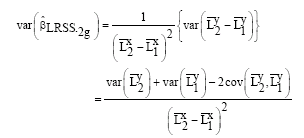 |
Also,
With
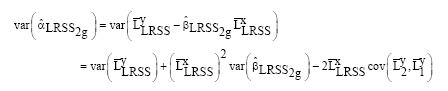 |
Theorem: Assuming model in Eq. 1-3 is satisfied, the LRSS based grouping estimators given in Eq. 12 are unbiased.
Proof:
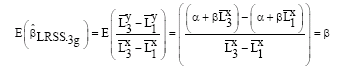 |
Where:
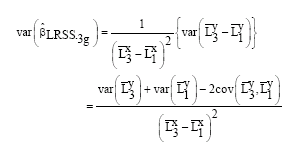 |
However,
And its variance is given as:
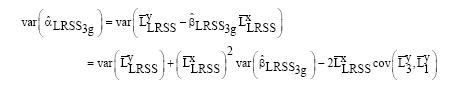 |
EMPIRICAL EXAMPLE
The proposed procedure is illustrated by using a real data set from Franklin and Hariharan (1994), in which the data that contains 2600 pairs of numbers (X, Y) where, Y is the score (in percentage) obtained by a student on a standardized calculus test administered at a certain university and X is the number of hours (recorded to the nearest hour) that the students spent studying for this test. It is obvious that these two variables are subject to errors. Therefore, the EIV is applicable to such data. A simple random sample of sizes n = 60, 80, 100 and 120 are chosen from the population. For the ranked data scheme, a set of size m = 3, 4, 5 and 6, that repeated r = 20 times (cycles) were used. The results based on these samples are shown in Table 1 and 2.
| Table 1: | Subpopulation counts, means and standard deviations |
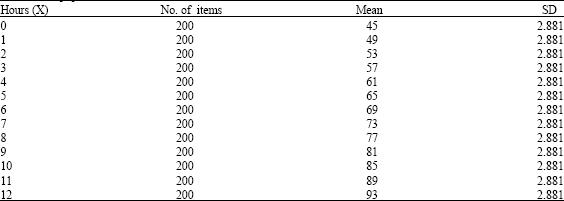 | |
| Table 2: | The estimated slope and intercept using wald-type estimator |
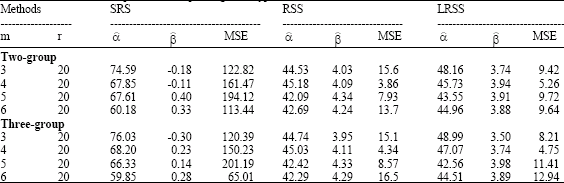 | |
Where:
| (11) |
It could be noted that, for a sample of size 60, SRS gives unreliable results and the slope values are negative, which means if the student studies his score will decrease. However, more reliable results were obtained by the ranked data schemes. This is an advantage in using LRSS and RSS over SRS, in this example. Moreover, the results showed that the estimators based on ranked data have a smaller MSE comparing to the estimators based on SRS. There is no effect of the sample size on reducing the value of MSE. Table 2 shows a good visual comparison among the three sampling methods. The results show that the ranked data are more efficient and more accurate estimators than SRS.
Table 2 comparing MSE for the three proposed method RSS and LRSS with SRS, the results show that the ranked data are more efficient and more accurate estimators than SRS.
SIMULATION STUDY
Two different Monte Carlo experiments were performed to gain insight into the properties of the EIV model parameters estimate using ranked data. The simulation was performed for sample size n = 15, 20, 25, 30, 40 and 50 where, the set size was selected to be r = 5, 10 and cycle size was m = 3, 4, 5 for RSS and LRSS; with coefficient (k = 1). Then 100,000 random samples were generated, assuming that α = 1, β = 2. The error terms and ξ were generated from the standard Normal distribution. Then the bias, the mean square errors for the model parameters and for the overall model and the relative efficiency were computed for each method. The formulas used in our simulation are as follows:
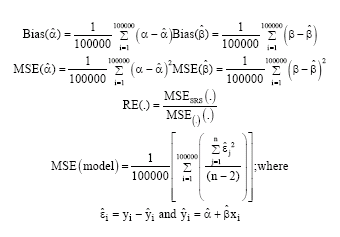 |
Experiment 1
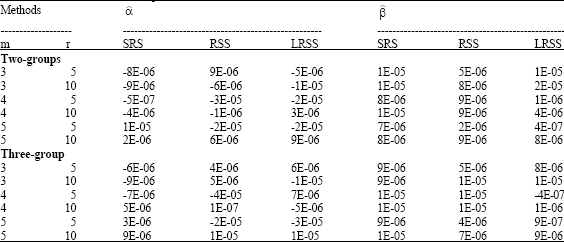
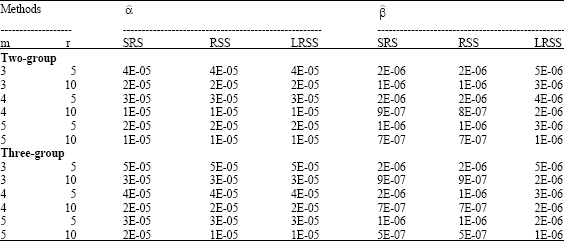
To study the performance of the EIV model parameters, the bias and the mean square error for the model under the simulation assumptions, we simulate ξ1, δ1 and ε1 from normal (0, 1) as symmetric distribution. The simulation results, bias, MSE and relative efficiencies are shown in Table 3-5, respectively. From the result Table 3-5, it appears that the use of grouping methods gives unbiased estimated parameter values for all-sampling methods.
| Table 3: | Bias for estimated EIV parameters |
 | |
| Table 4: | MSE for estimated EIV parameters |
 | |
| Table 5: | RE for EIV parameters |
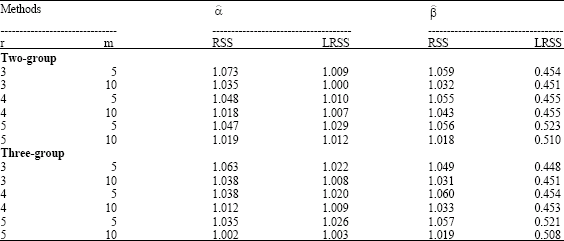 | |
The bias using all-methods are around (.)*10-5 and (.)*10-7. The values for the estimated parameter decrease when the sample size increases. Moreover, in the case of the estimated intercept, the LRSS scheme is more accurate than the SRS scheme. LRSS is more efficient than SRS, while in all situations RSS is more efficient than other schemes. However, in estimating the slope RSS is more efficient for the slope t than SRS and LRSS.
Experiment 2
Here, the performance of the proposed grouping estimators in the presence of the outliers is investigated under the same simulation assumptions. Then one random outlier in each case is generated according to the sample size.
The simulated bias and MSE are summarized in Table 6-8, the results indicate that the proposed estimators based on RSS and SRS when the data contain some outliers give inaccurate estimators for the EIV parameters. However, in case of LRSS the proposed estimators are more accurate and more efficient than the other schemes. MSE is also much better for LRSS. Moreover, the estimated parameters decrease as the sample size increases. The result indicates that LRSS is more efficient than RSS and SRS, also with two and three-group methods to estimate the EIV parameters. And it indicates that the RE for all methods increases when the number of cycles increases.
| Table 6: | Bias for the EIV parameters: outliers case |
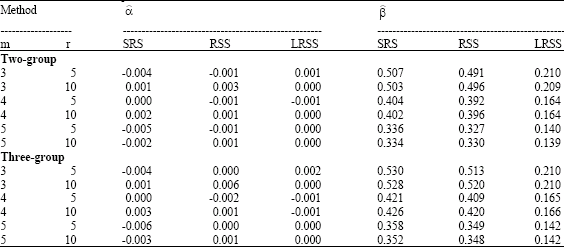 | |
| Table 7: | MSE for the EIV parameters: outliers case |
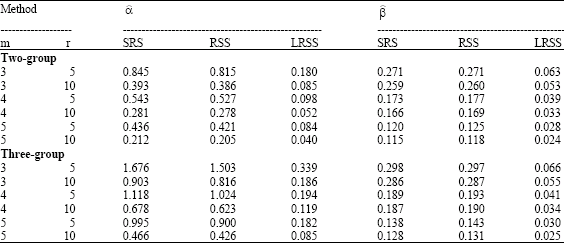 | |
| Table 8: | RE for EIV parameters: outliers case |
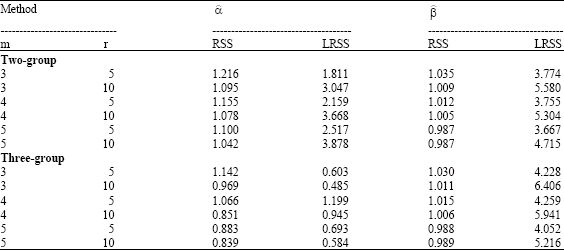 | |
CONCLUSIONS
Wald-type estimators for the Error in Variable Model (EIV) were made based on the new sampling technique called L Ranked Set Sampling (LRSS). The proposed procedure was exemplified by a real data set from Franklin and Hariharan (1994), in order to reduce the cost and increase the efficiency of the estimators. The data contained bivariate data (X, Y). Where, Y was the score (in percentage) obtained by a student on a standardized calculus test administered at a certain university and X was the number of hours (recorded to the nearest hour) that the students spent studying for this test. The results of the statistical analysis recognized the robustness of the LRSS scheme over SRS by giving more reliable estimates. Moreover, it has been seen that the proposed Wald type estimators are unbiased toward the EIV model. Two Monte Carlo experiments were considered in order to study the performance of the estimators with the three sampling techniques, LRSS, RSS and SRS. It appears that the suggested estimators based on LRSS are more accurate and more efficient. The simulation confirmed that estimating both the slope and the intercept of the EIV model using LRSS is in general more efficient than using SRS. Note that the experiments show that the relative precision of the proposed estimators decreases as the set size or the cycle size increase. It seems that, for moderate or large sample size, the performance of parameter estimation of the EIV model was affected by the sampling scheme used. However, using LRSS is still more efficient than using SRS or RSS for the analysis.
REFERENCES
- Al-Nasser, A.D. and A. Al-Radaideh, 2008. Estimation of simple linear regression model using L ranked set sampling. Int. J. Open Problems Comput. Sci. Math., 1: 18-33.
Direct Link - Al-Nasser, A., 2007. L ranked set sampling: A generalization procedure for robust visual sampling. Commun. Stat. Simul. Comput., 36: 33-43.
CrossRefDirect Link - Bartlett, M.S., 1949. Fitting straight line when both variables are subject to error. Biometrics, 5: 207-212.
Direct Link - Cheng, C.L. and J.W. Van Ness, 1999. Statistical Regression with Measurement Error. Arnold, New York, USA.,.
Direct Link - Chen, Z. and Y.G. Wang, 2004. Efficient regression analysis with ranked-set sampling. Biometrics, 60: 997-1004.
CrossRef - Nair, R.K. and P.M. Shrivastava, 1942. On a simple method of curve fitting. Sanynkhya, 6: 121-132.
Direct Link - Wald, A., 1940. The fitting of straight lines if both variables are subject to error. Ann. Math. Stat., 11: 284-300.
Direct Link