
J.O. Olaomi
Department of Statistics, University of Ibadan, Ibadan, Nigeria
A. Ifederu
Department of Statistics, University of Ibadan, Ibadan, Nigeria
Asian Journal of Mathematics & Statistics
Year: 2008 | Volume: 1 | Issue: 1 | Page No.: 14-23







ABSTRACT
Assumptions in the classical normal linear regression model include that of lack of autocorrelation of the error terms and the zero covariance between the explanatory variable and the error terms. This study is channeled towards the estimation of the parameters of the linear regression models when the above two assumptions are violated. The study used the Monte-Carlo method to investigate the performance of five estimators: Ordinary Least Squares (OLS), Cochrane Orcutt (CORC), Hildreth Lu (HILU), Maximum Likelihood (ML) and Maximum Likelihood Grid (MLGRID) in estimating the parameters of a single linear regression model in which` the exponential explanatory variable is also correlated with the autoregressive error terms. The simulation results, under the finite sampling properties of bias, Variance and Root Mean Squared Error (RMSE), show that all estimators are adversely affected as autocorrelation coefficient (ρ) is close to unity. In this regard, the estimators rank as follows in descending order of performance: OLS, MLGRID, ML, CORC and HILU. The estimators conform to the asymptotic properties of estimates considered. This is seen at all levels of autocorrelation and at all significant levels. The estimators rank in decreasing order in conformity with the observed asymptotic behaviour as follows: OLS, ML, MLGRID, HILU and CORC. The results suggest that OLS should be preferred when autocorrelation level is relatively mild (ρ = 0.4) and the exponential regressor is significantly correlated at 5% with the autocorrelated error terms.
PDF Abstract XML References Citation
How to cite this article
J.O. Olaomi and A. Ifederu, 2008. Understanding Estimators of Linear Regression Model with AR(1) Error Which are Correlated with Exponential Regressor. Asian Journal of Mathematics & Statistics, 1: 14-23.
DOI: 10.3923/ajms.2008.14.23
URL: https://scialert.net/abstract/?doi=ajms.2008.14.23
DOI: 10.3923/ajms.2008.14.23
URL: https://scialert.net/abstract/?doi=ajms.2008.14.23
INTRODUCTION
In the classical statistical linear model,
(1) |
Where:
| Y | = Tx1 vector |
| X | = (Txk) matrix of rank k |
| β | = (kx1) vector of parameters |
| U | = (Tx1) vector of disturbance terms |
In using the Ordinary Least Squares (OLS) method to estimate the parameters and also to enable inferences to be made about these estimators, certain underlying assumptions are made. Two of them are the absence of autocorrelation of the error terms and that X is a matrix with nonstochastic elements and has rank k < T, hence Ui and Xj are independent for all i and j.
This research is channeled towards the estimation of the parameters of the linear models when the above two assumptions are violated using exponential trended regressor. This would help researchers and practitioners in the choice of estimator in empirical work when the regressor and the error terms are not well behaved. It would also allow correct inferences in linear models plagued by autocorrelated disturbances, which are also significantly correlated with the exponential trended explanatory variable.
Example of this situation is seen in widespread applications in Operations Research, like in Queuing theory and Econometrics where the usual assumption of independent error terms may not be plausible in most cases. Also, when using time-series data on a number of micro-economic units, such as households and service oriented channels, where the stochastic disturbance terms in part reflect variables which are not included explicitly in the model and which may change slowly over time. (Nwabueze, 2000).
Under the underlying assumptions, the statistical model (1) can be estimated for the unknown β vector and the unknown scalar σ2, because the observed random variable Y contains all of the information about them. This estimate of the parameters can be obtained using the least squares or the maximum likelihood method. The ordinary least squares estimator had been found to be a Best Linear And Unbiased (BLUE), as shown by the Gauss-Markov theorem, in Johnston (1984). When the disturbance term U satisfies the basic assumptions, we say that U is well behaved and all the theorems on OLS relating to estimation and hypotheses testing apply to the parameters of the model of (1).
On the other hand, when there is presence of autocorrelation or serial correlation of the error terms, the OLS estimate remains unbiased, but they are no longer minimum variance estimates. That is, they are inefficient, which implies that the standard errors will be based on the wrong expression σ2(X’X)-1. Thus the standard t and F tests will no longer be valid and inferences will be misleading.
In time-series applications, there are many structures of autocorrelation. Some of the simplified structures are: Autoregressive (AR) processes, Moving Average (MA) processes, or Joint Autoregressive Moving Average (ARMA) processes. There are specific approaches to handling each of these structures of the error term when they occur in a linear model. They therefore, need different methods of estimation and hypothesis testing. This study considers the first-order Autoregressive structure (AR(1)).
Approaches to dealing with estimation in autocorrelated linear models include overall maximum likelihood estimation, least squares and transformation of variables. When the autocorrelated errors are known, usually, the estimation poses no major problems as the underlying variables can be transformed to overcome this problem. Different forms of transformation techniques have been proposed by different researchers. Many researchers have different methods of estimating the autocorrelated parameters in situations where the variables are unknown. These error estimates are used as weights in estimating β.
Consider the model:
(2) |
If we multiply the model (2) by some TxT nonsingular transformation matrix P to obtain:
PY = PXβ +PU | (3) |
The variance matrix for the disturbance in Eq. 3 is:
E(PUU/P/) = σ2 PΩP’ since E(PU) = 0 |
Since we can specify P such that:
PΩP’ = I, |
then the resulting OLS estimates of the transformed variables PY and PX in Eq. 3 have all the optimal properties of OLS and could be validly subjected to the usual inference procedures. Applying OLS to Eq. 3 results in minimizing the quadratic form:
with optimal solutions as:
(4) |
which gives:
(5) |
with the variance-covariance matrix given by ![]() . This estimator is known as
. This estimator is known as ![]() the Aitken or Generalised Least Squares (GLS) estimator. If we assume normality for the error terms, the Us, the likelihood function is given by:
the Aitken or Generalised Least Squares (GLS) estimator. If we assume normality for the error terms, the Us, the likelihood function is given by:
(6) |
Where, ![]() is the determinant of Ω. Optimising this likelihood function with respect to β means maximizing the weighted sum of squares to obtain;
is the determinant of Ω. Optimising this likelihood function with respect to β means maximizing the weighted sum of squares to obtain;
(7) |
In obtaining ![]() (OLS) and
(OLS) and ![]() (GLS), we assume Ω is known. When Ω is not known, we resort to estimating Ω by
(GLS), we assume Ω is known. When Ω is not known, we resort to estimating Ω by ![]() in which case, we obtain an Estimated Generalized Least Squares (EGLS) or Estimated Generalized Maximum Likelihood (EGLM) estimator and therefore:
in which case, we obtain an Estimated Generalized Least Squares (EGLS) or Estimated Generalized Maximum Likelihood (EGLM) estimator and therefore:
(8) |
For this model, in Eq. 5, the TxT covariance matrix of the error vector is:
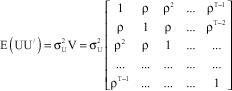 | (9) |
Where:
To search for a suitable transformation matrix P*, we consider the following (T-1)xT matrix P* defined by:
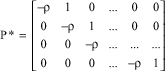 | (10) |
Where:
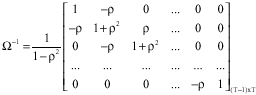 | (11) |
P*/ P* gives ![]() with ρ2 instead of 1 as the first element. Next, we consider another transformation matrix P(TXT) obtained by adding a new first row with
with ρ2 instead of 1 as the first element. Next, we consider another transformation matrix P(TXT) obtained by adding a new first row with ![]() in the first position and zero elsewhere:
in the first position and zero elsewhere:
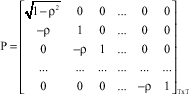 | (12) |
P* and P differ only in the treatment of the first observation. P* is much easier to use provided we are prepared to put up with its treatment of the first observation. It has been shown that when T is large, the difference is negligible but in small samples such as in this study, the difference is significant.
Such transformations give rise to different methods of estimation. These methods are broadly classified into those that use P* such as Cochrane-Orcutt (CORC) and Hildreth and Lu (HILU) methods and those that use P for transformation such as Prais-Winstein (PW), Maximum Likelihood (ML) method of Beach and Mackinnon (1978) and Maximum Likelihood Grid method (MLGRID). Nwabueze (2005a).
Many researchers have worked on autocorrelated errors. They include the early work of Cochran and Orcutt (1949), Durbin and Watson (1950, 1951, 1971), Hildreth and Lu (1960), Rao and Grilliches (1969), Beach and Mackinnon (1978), Kramer (1980), Busse et al. (1994) and Kramer and Hassler (1998), to the recent works of Kleiber (2001), Kramer and Marmol (2002), Butte (2002), Nwabueze (2000, 2005a, b), Olaomi (2004, 2006), Olaomi and Iyaniwura (2006) and Olaomi and Ifederu (2006). Tests for detecting the presence of autocorrelation and alternative consistent methods of estimating linear models with autocorrelated disturbance terms have been proposed.
When the covariance between the explanatory variable and the error terms is non-zero, β estimate is biased. The problem becomes near intractable by analytical procedure. Hence we resort to the Monte-Carlo simulation method for estimation. Olaomi (2004, 2006), Olaomi and Iyaniwura (2006) and Olaomi and Ifederu (2006) have done considerable work on this.
The effect of certain types of trends on explanatory variables on the relative performance of estimators has been recognised by Maeshiro (1976), Kramer (1998), Kramer and Marmol (2002), Nwabueze (2005b) and Ifederu (2006). However, some are mainly concerned with asymptotic properties. Asymptotically disregarding the first observation makes no difference but in small samples, it may make a substantial difference.
However, in spite of these tests and estimation methods, a number of questions in connection with the estimation of the classical regression linear model with autocorrelated error terms and non-zero covariance between the explanatory variable and the error terms remained unanswered. These include the most appropriate estimation method in the above named specification of the explanatory variable, the effect of the degree of correlation of the disturbance term, the effect of the degree of correlation of explanatory variable and the error terms, the effect of sample size and the sampling properties of the various estimation methods.
The answers to most of these questions would allow for correct inferences to be made in linear models plagued by the scenario depicted earlier.
MATERIALS AND METHODS
This study used the Monte-Carlo approach for the investigation due to the non-zero covariance between the explanatory variable and the error terms. The problem is near intractable by analytical procedure.
The following four Generalised Least Squares (GLS) estimators: CORC, HILU, ML and MLGRID and OLS estimation methods, chose in the light of the earlier study are used. These estimators are equivalent with identical asymptotic properties. Kramer and Hassler (1998). But in small samples, such as in this study, Park and Mitchell (1980) have argued that those that use the T transformation matrix (ML, MLGRID) are generally more efficient than those that use T* transformation matrix (CORC, HILU).
The degree of autocorrelation affects the efficiency of the estimators. Nwabueze (2000). Consequently, we investigated the sensitivity of the estimators to the degree of autocorrelation by varying rho ![]() from 0.4, to 0.8 and 0.9. We also found out the effect of the correlation of the explanatory variable and the error terms at significant level 1, 2 and 5% on the estimators. The effects of sample size on the estimators were also investigated by varying the sample size from 20, 40 to 60 each replicated 50 times. Evaluation of the estimators was then done using the finite sampling properties of Bias (BIAS), Minimum Variance (VAR) and Minimum Root Mean Squared Error (RMSE).
from 0.4, to 0.8 and 0.9. We also found out the effect of the correlation of the explanatory variable and the error terms at significant level 1, 2 and 5% on the estimators. The effects of sample size on the estimators were also investigated by varying the sample size from 20, 40 to 60 each replicated 50 times. Evaluation of the estimators was then done using the finite sampling properties of Bias (BIAS), Minimum Variance (VAR) and Minimum Root Mean Squared Error (RMSE).
The Model
We assume a simple linear regression model:
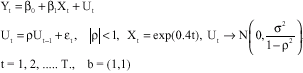 | (13) |
Where:
| Yt | = The dependent variable and the exponential trended |
| Xt | = The explanatory variable with Ut autoregressive of order one |
| εt | = Normally distributed with zero mean and constant variance σ2 |
| ρ | = Stationarity parameter while the model parameters are assumed to be unity |
Nwabueze (2005b) and Olaomi and Ifederu (2006) had used this explanatory variable specification. It is chosen to allow for comparison of results.
Data Generation
A total of 27 data sets spread over three sample sizes (20, 40 and 60) each replicated 50 times were used in generating the data for this study. Using model (13), a value Uo was generated by drawing a random value εo from N (0,1) and dividing by ![]() Successive values of εt drawn from N (0,1) were used to calculate Ut. Xt was generated as defined in (13). Correlation between Ut and Xt was then computed and its absolute value tested for significance at say 1, 2 or 5%. If this value is significant, it is chosen; otherwise it is discarded. This procedure is repeated as many times as are necessary to obtain 50 replications for a desired autocorrelation level, significance level and sample size. Olaomi (2004) had shown that in most Monte-Carlo studies, magnitudes such as bias, variance and root mean squared are not usually remarkably sensitive to the number of replications. Replication just shows the stability of estimates. Yt is thus computed for the chosen Ut and Xt. using Eq. 13. The computations are made using the Microsoft Office Excel package, different estimation methods are then applied to the data using the AR procedure of the TSP (2005) package.
Successive values of εt drawn from N (0,1) were used to calculate Ut. Xt was generated as defined in (13). Correlation between Ut and Xt was then computed and its absolute value tested for significance at say 1, 2 or 5%. If this value is significant, it is chosen; otherwise it is discarded. This procedure is repeated as many times as are necessary to obtain 50 replications for a desired autocorrelation level, significance level and sample size. Olaomi (2004) had shown that in most Monte-Carlo studies, magnitudes such as bias, variance and root mean squared are not usually remarkably sensitive to the number of replications. Replication just shows the stability of estimates. Yt is thus computed for the chosen Ut and Xt. using Eq. 13. The computations are made using the Microsoft Office Excel package, different estimation methods are then applied to the data using the AR procedure of the TSP (2005) package.
RESULTS
The finite sampling properties of estimators we used include the Bias (BIAS), Sum of Bias of intercept and slope coefficients (SBIAS), Variance (VAR), sum of variances of intercept and slope coefficients (SVAR) and the Root Mean Squared Error (RMSE). Sum of RMSE of intercept and slope coefficients (SRMSE).
The results are shown in Table 1 -3 for SBIAS, SVAR and SRMSE, respectively. It is observed that the slope coefficient is better estimated than the intercept coefficient.
| Table 1: | Sum of absolute BIAS for estimators of β |
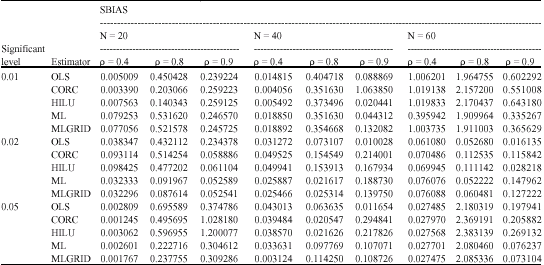 | |
| Table 2: | Sum of variance for estimators of β |
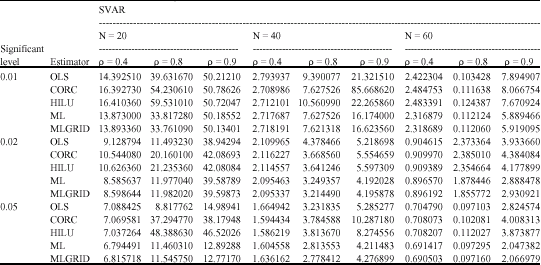 | |
| Table 3: | Sum of root mean squared error for estimators of β |
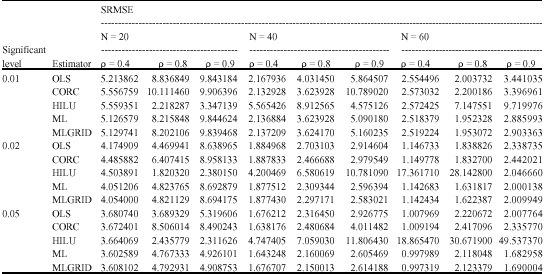 | |
| Table 4: | Summary of ranks of estimators based on optimum trend of bias, variance and root mean squared error for ρ keeping α constant |
 | |
| Table 5: | Summary of ranks of estimators based on optimum trend of bias, variance and root mean squared error for ρ keeping α constant |
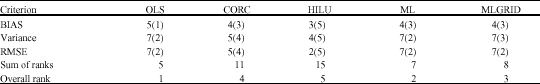 | |
All estimators compare favourably with one another in all the criteria used, except HILU estimator using the RMSE which performed best at the sample sizes 40 and 60. It is also noticed that as the sample size N increases, the estimates become better (consistent). As autocorrelation coefficient (ρ) increases, the estimates become worse (it increased for both SVAR and SRMSE). Also as the correlation (α) value decreases, the estimates become better.
The results also show that all estimators are adversely affected as autocorrelation coefficient (ρ) is close to unity when the regressor is significantly correlated with the error terms. This is evidenced by the optimum (ρ, α) combinations of (0.4, 0.05) as ρ increases and also as α decreases using both the variance and the RMSE criteria. There is absence of the combinations of high levels of ρ and α, such as, (0.9, 0.01), (0.9, 0.02), (0.9, 0.05), (0.8, 0.01), (0.8, 0.02), (0.8, 0.05), (0.4, 0.01) and (0.4, 0.02).
The estimators rank as follows in descending order based on combinations of the optimum trends of Bias, Variance and RMSE: OLS, MLGRID, ML, CORC and HILU as ρ increases. Table 4 and 5 shows the ranking as α decreases as; OLS, ML, MLGRID, CORC and HILU.
We also investigated the asymptotic behaviour of the estimators in present experiment. The five estimators rank as follows in decreasing order of conformity with the observed asymptotic behaviour of bias, variance and RMSE: OLS, ML, MLGRID, HILU and CORC (Table 6).
| Table 6: | Optimum trend ranking of asymptotic behaviour of the estimators |
 | |
DISCUSSION
The simulation results, under all the finite sampling properties of Bias, Variance and RMSE considered show that all estimators are consistent and are adversely affected as autocorrelation coefficient (ρ) is close to unity when the trended regressor is significantly correlated with the autocorrelated error terms. This is similar to Olaomi (2006) results. This also conforms to literature when there is no correlation between the regressor and the error terms (Johnston and DiNardo, 1997; Nwabueze, 2000). In this regard, the estimators rank as follows in descending order: OLS, MLGRID, ML, CORC and HILU.
The results suggest that OLS should be preferred when autocorrelation level is relatively mild (ρ = 0.4) and the regressor is significantly correlated at 5% with the autocorrelated error term. This seems reasonable because the corrective measures incorporated into the GLS estimators make use of the ‘badly behaved regressor` and these may adversely affect the performance of these estimators. Also if there is low or insignificant autocorrelation and the regressor and the error terms are mildly correlated, OLS should be preferred since there may not be any need for any GLS estimator.
We found that the estimators conform to the asymptotic properties of estimates considered. This is seen at all levels of autocorrelation and at all significant levels. The estimators` rank in decreasing order of conformity with the observed asymptotic behaviour as follows: OLS, ML, MLGRID, HILU and CORC. This ranking is contrary to that of Olaomi (2006).
We also note that ML and MLGRID have very similar behavioural pattern, the same for CORC and HILU as observed in the finite sampling properties of Bias, Variance and the RMSE. ML and MLGRID are better than both CORC and HILU as also observed by Park and Mitchell (1980).
CONCLUSION
We have shown that when there is significant correlation between the exponential explanatory variable and the autocorrelated error terms in a classical single linear regression estimation problem, MLGRID or ML estimation method should be used based on the finite sampling criteria used in this experiment. It is also shown that all the estimators are still asymptotically behaved and consistent, all estimators are adversely affected as autocorrelation coefficient is close to unity and as the significant level of the correlation between the regressor and the autocorrelated error term (α) decreases, the estimates become better, with MLGRID and ML estimation methods preferred, followed by the CORC and HILU methods. Though OLS performed best in this experiment, it is disregarded because it does not correct for autocorrelation in its method. It is only recommended when the degree of autocorrelation is low and there is very mild correlation between the explanatory variable and the error terms.
REFERENCES
- Beach, C.M. and J.S. Mackinnon, 1978. A maximum likelihood procedure for regression with autocorrelated errors. Econometrica, 46: 51-58.
CrossRefDirect Link - Busse, R., R. Jeske and W. Kramer, 1994. Efficiency of least-squares-estimation of polynomial trend when residuals are autocorrelated. Econ. Lett., 45: 267-271.
CrossRefDirect Link - Butte, G., 2002. The Equality of OLS and GLS estimators in the linear regression model when the disturbances are spatially correlated. Stat. Papers, 42: 253-263.
CrossRefDirect Link - Cochrane, D. and G.H. Orcutt, 1949. Application of least squares regression to relationships containing auto-correlated error terms. J. Am. Stat. Assoc., 44: 32-61.
CrossRefDirect Link - Durbin, J. and G.S. Watson, 1950. Testing for serial correlation in least squares regression: I. Biometrika, 37: 409-428.
CrossRefDirect Link - Durbin, J. and G.J. Watson, 1951. Testing for serial correlation in least squares regression. II. Biometrika, 38: 159-177.
CrossRefDirect Link - Kleiber, C., 2001. Finite sample efficiency of OLS in linear regression models with long-memory disturbances. Econ. Lett., 72: 131-136.
Direct Link - Kramer, W., 1980. Finite sample efficiency of ordinary least squares in the linear regression model with autocorrelated errors. J. Am. Stat. Assoc., 75: 1005-1009.
CrossRefDirect Link - Kramer, W. and U. Hassler, 1998. Limiting efficiency of OLS vs. GLS when regressors are fractionally integrated. Econ. Lett., 60: 285-290.
CrossRefDirect Link - Kramer, W. and F. Marmol, 2002. OLS-based asymptotic inference in linear regression models with trending regressors and AR (P) disturbances. Commun. Stat. Theory Methods, 31: 261-270.
Direct Link - Maeshiro, A., 1976. Autoregressive transformation, trended independent variables and autocorrelated disturbance terms. Rev. Econ. Stat., 58: 497-500.
CrossRefDirect Link - Nwabueze, J.C., 2005. Performance of estimators of linear model with autocorrelated error terms when the independent variable is normal. J. Nig. Assoc. Math. Phys., 9: 379-384.
Direct Link - Nwabueze, J.C., 2005. Performance of estimators of linear model with autocorrelated error terms with exponential independent variable. J. Nig. Assoc. Math. Phys., 9: 385-388.
Direct Link - Olaomi, J.O., 2007. Estimation of the parameters of linear regression model with autocorrelated error terms which are also correlated with the regressor. Global J. Pure Applied Sci., 13: 237-242.
CrossRefDirect Link - Park, R.E. and B.M. Mitchell, 1980. Estimating the autocorrelated error model with trended data. J. Econometrics, 13: 185-201.
CrossRefDirect Link - Rao, P. and Z. Griliches, 1969. Small-sample properties of several two-stage regression methods in the context of auto-correlated errors. J. Am. Stat. Assoc., 64: 253-272.
CrossRefDirect Link