
Mehdi Karimi- Nasab
Department of Industrial Engineering, Iran University of Science and Technology, Narmak, Tehran, Iran
Hamidreza Haddad
Department of Industrial Engineering, Iran University of Science and Technology, Narmak, Tehran, Iran
Payam Ghanbari
Department of Industrial Engineering, Iran University of Science and Technology, Narmak, Tehran, Iran
Asian Journal of Industrial Engineering
Year: 2012 | Volume: 4 | Issue: 1 | Page No.: 1-16







ABSTRACT
This research studied the problem of minimizing the total tardiness and maximizing the job values in makespan on a single machine when the deteriorated jobs are delivered to each customer in various size batches and there are some priorities between the jobs. Under such circumstances, keeping completed jobs to be delivered in batches may result in reducing delivery costs. In addition, it may cause the job process to accelerate. In order to solve the proposed model, a simulation annealing meta-heuristic is used and its results are compared with the global optimal values that are generated by Lingo 10 software. Based on the effective factors of the problem, a number of sensitivity analyses are also implemented. In order to examine the efficiency of proposed Simulated Annealying (SA) for larger scales, a lower bound is also generated and is compared with the results of SA. Computational study validates the efficiency and accuracy of the presented model.
PDF Abstract XML References Citation
Received: November 05, 2011;
Accepted: January 24, 2012;
Published: February 29, 2012
How to cite this article
Mehdi Karimi- Nasab, Hamidreza Haddad and Payam Ghanbari, 2012. A Simulated Annealing for the Single Machine Batch Scheduling with Deterioration and Precedence Constraints. Asian Journal of Industrial Engineering, 4: 1-16.
DOI: 10.3923/ajie.2012.1.16
URL: https://scialert.net/abstract/?doi=ajie.2012.1.16
DOI: 10.3923/ajie.2012.1.16
URL: https://scialert.net/abstract/?doi=ajie.2012.1.16
INTRODUCTION
Production and manufacturing are two of the most important problems in real industries which is attendant more researches. Generally, the literature of manufacturing could be divided to two separate sub-groups which are qualitative and computational approaches. In qualitative approaches, firstly the effective factors on the performance of manufacturing are determined and then it is attempt to control them. On the other hand, computational efforts use the modeling procedure to describe the manufacturing environment and present some methods so as to solve the constructive models.
Feylizadeh and Bagherpour (2011) accomplished a comprehensive review related to the application of optimization techniques in production problems involving single machine scheduling.
Hemamalini et al. (2010) proposed a deep memory greedy search so as to solve the problem of minimizing makespan in a job shop scheduling environment.
Khurana et al. (2011) studied the effective factors on the performance of a supply chain and presented an AHP approach to analyze and compare the identified factors. Their factors could be categorized in six separate groups involving managerial, organizational, technological, individual, financial, social and cultural.
Iwarere and Lawal (2011) studied a case study related to maintenance of public facilities in Nigeria. They stated that government, management and employees are the main effective factors on the performance of public facilities.
Hammoud et al. (2011) presented a genetic model and an intelligent agent based system for analyzing the machine learning effect.
Rajarathinam and Parmar (2011) studied the using of parametric and nonparametric regression models to identify the effective factors on the production.
Nja and Udofia (2009) proposed a mixed integer goal programming approach for flour producing companies and presented an applicable example for a facility with three products. They also claimed that their model is cost effective and could be used in any factory or facility.
Taleizadeh et al. (2008) developed a new version of newspaper’s boy in which the assumptions of multiple products and multiple constraints were considered simultaneously. Furthermore, the orders were considered and some batches and sent to their customers. In order to solve the proposed model, they modified a genetic algorithm which its results were very effective.
Mahdavi and Shirazi (2010) reviewed the application of decision support systems to improve the performance of flexible manufacturing systems.
This research studied the problem of single machine batch scheduling which depicts a two staged supply chain scheme and contains a manufacturer and a number of customers in which each job may be transmitted to its customer right after its completion or be held to batch with more jobs. Batching the jobs not only may cause the job process to accelerate, but also could decrease the delivery cost of job transmission to their customers.
Mazdeh et al. (2011a) mentioned that the problems that combines a scheduling function with delivery costs are rather complex and solving them by simple optimization methods is not commercial.
The literature of single machine batch scheduling can be classified by variant concepts. For example, based on how the batches are processed on the machine, the problem would contain serial or parallel batching categories. In serial batching, it is assumed that each batch is processed based on all the processing time of its jobs and the processing time of batch is equal to the completion time of last job assigned to it. Ng et al. (2002) studied the problem of single machine serial batch scheduling to minimize maximum lateness by considering the precedence constraints between the batches and presented an o(n2) polynomial time algorithm. Ng et al. (2003) also investigated the same problem by total completion time objective, release date and precedence constraints and presented an o(n5) polynomial algorithm.
Lu and Yuan (2007) considered the serial batch scheduling when each batch contained exactly k jobs and the objective was to minimize the total weighted completion time. They showed that the problem is NP-hard and proposed a polynomial algorithm with some simplified rules.
The other researches in the field of serial batching could be mentioned as: An o(n log n) algorithm for minimizing total completion time by Coffman et al. (1990), an o(n2) algorithm for minimizing total weighted completion time with precedence constraint by Albers and Bruker (1993) and an o(n14) algorithm for minimizing total completion time by Baptiste (2000). On the other hand, the processing time of a parallel batch is calculated by the maximum processing time of jobs that are apparent to that batch. Nong et al. (2008) investigated the problem of single machine parallel batching to minimize makespan by considering family setups and release date. They developed a polynomial approximation scheme for their problem by some simplifications the model that yielded an algorithm with worst case ratio of 2.5.
Potts and kovalyov (2000) accomplished an extensive review in the field of parallel batching literature and gave details of basic solution methods.
In recent years, researchers have considered the delivery cost as a secondary objective called “combined optimization batch delivery problem”. Mazdeh et al. (2011a, b) studied the problem of minimizing the number of weighted tardy jobs by considering delivery cost and used a simulation annealing approach to solve the problem. Tian et al. (2007) investigated the problem of minimizing the sum of total weighted flow times with delivery cost. They indicated that the problem is NP-hard and proposed an optimal algorithm. Mazdeh et al. (2011b) proposed a branch and bound approach to solve the problem of minimizing the weighted sum of flow times with delivery cost. Another research related to Mazdeh et al. (2007) presented a branch and bound to minimize flow time and delivery cost simultaneously.
One of the most important problems considered in scheduling problem is job deterioration, where there are wide applications in many real-world situations. Deterioration means that the processing time of jobs increases over time.
Browne and Yechiali (1990) introduced a job deterioration scheduling problem in which the processing time of a job was a function of its starting time. Mosheiov (1994), who was the first to apply simple linear deteriorating for single machine scheduling problem, considered this problem to minimize the makespan, total completion time, total weighted completion time, total weighted waiting time and total tardiness, number of tardy jobs, maximum lateness and maximum tardiness.
Wu et al. (2009) solved a single-machine problem by a branch-and-bound scheme and two heuristic algorithms to minimize the makespan. Wang et al. (2009) solved the single machine scheduling problems with learning effect and deteriorating jobs simultaneously to minimize the total weighted completion time and the maximum lateness. Wang and Wang (2010) considered a single machine scheduling problem with deteriorating jobs in which the processing time of a job was defined as a simple linear function of its starting time to minimize the total weighted earliness penalty subject to no tardy jobs. Husang et al. (2010) considered a single machine scheduling problem with deteriorating jobs by a linear function of time to minimize the total weighted earliness penalty subject to no tardy jobs. Ji and Cheng (2010) proposed a single machine scheduling problem in which the jobs were processed in batches and the processing time of each job was a simple linear function of its waiting time to minimize the makespan. Al-Anzi et al. (2007) studied the combination of deteriorating and scheduling objectives with application in computer communication and reverse logistics.
In this study we propose a mathematical model for the issue of serial batch scheduling problem, where the objective is to minimize the total tardiness and delivery costs and maximizing the job values in makespan simultaneously that based on our knowledge, is less considered in the literature.
Afterwards, a simulation annealing approach is used to get to near optimal solutions. In order to check the verification of SA, some data sets of problem are solved optimally using Lingo software and the results are compared with each other. For larger scales of problem, a lower bound is also generated and the comparison accomplished based on it.
PROBLEM FORMULATION
Consider there is a machine that processes in jobs with no preemption and all of the jobs are available for processing at time zero. The completed jobs can be delivered to the customer immediately after completion or be awaited next jobs to be delivered as a batch. According to number of jobs, N batches are considered and the jobs are assigned to the batches. Clearly any batch that does not have any jobs will be omitted and then the sequence of batches is determined so that the proposed objective function is minimized. As mentioned, the serial batching assumption is considered in this paper, therefore, the processing time of each batch is calculated as sum of the all processing jobs located on it and the due date of batch is the maximum value of due date of jobs which are assigned to it.
The decision variables and parameters of the problem are listed below:
| N | = | Number of jobs ready to be scheduled |
| pi | = | The normal processing time of job I |
| di | = | The due date of ith job |
| Oi | = | The priority of job I |
| pbat(k) | = | The processing time of batch k |
| Dbat(k) | = | The due date of batch k |
| Obat(k) | = | The priority of batch k |
| nk | = | Number of jobs assigned to batch k |
| tj | = | The tardiness of job where scheduled on jth position |
| ci | = | The completion time of job where scheduled on jth position |
| α | = | The rate of deterioration |
| β | = | The decreasing rate of job value |
| Sk | = | The value of shipping cost of batch k |
| = | If job I is assigned to batch k | |
| otherwise | ||
| = | If batch k is located in jth position in the sequence | |
| otherwise | ||
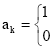 | = | If there is at least one job assigned to batch k |
| otherwise |
and the proposed model is presented as follows:
| (1) |
St:
| (2) |
| (3) |
| (4) |
| (5) |
| (6) |
| (7) |
| (8) |
| (9) |
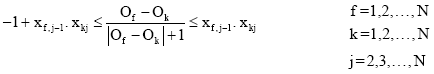 | (10) |
| (11) |
| (12) |
| (13) |
| (14) |
| (15) |
Equation 1 introduces the objective function where the first term corresponds to the delivery cost, the second term corresponds to the sum of tardiness and the third term is related to the sum of job values in makespan. Constraint (2) states that the completion time of each batch is equal to the completion time of prior batches plus the sum of processing times of jobs assigned to it. Constraint (3) mentions that the machine and all the jobs are available at time zero. Constraint (4) declares that the completion time of each batch is equal to the sum of processing times of jobs assigned to it. Constraint (5) determines how many jobs are located on each batch. Constraint (6) states that whether batch k is empty or not. Constraint (7) clarifies that the tardiness of each batch is equal to the gap between the time that the processing of that batch has been completed and its due date. Clearly, the value of tardiness must be positive. Equation 8 shows how the due date of each batch is calculated and Eq. 9 demonstrates how the order of each batch is considered. Constraint (10) is related to the precedence constraint. Constraint (11) states that each batch is processed only once at each sequence and constraint (12) determines each position can be assigned to just one batch. Constraint (13) mentions if a job can be assigned to exactly one batch to be processed and constraint (14), (15) shows that x and y are binary variables.
SOLUTION APPROACH
As mentioned, the considered problem is NP-hard; hence it is not reasonable to use ordinary optimization methods. In this case, a simulation annealing meta- heuristic (SA) is implicated to reach the near optimal solutions in suitable run times.
SA that have been applied widely to solve many combinatorial optimization problems is a class of optimization Meta heuristics and performs a stochastic neighborhood search through the solution space. It is proved that SA can be considered as a marcov chain (Van-Laarhoven and Aarts, 1988), so its sensitivity to the initial solution is much less than the other meta-heuristics and has a great ability to avoid getting in local optimum solutions.
In this study, the algorithm starts from an initial temperature termed as T0 in which, two random strings are generated as below.
The first string corresponds to assigning the jobs to batches and another is related to find a suitable scheduling of generated batches.
Based on this fact, consider there are five available jobs for processing on the machine. The first string shows that the first and the second jobs are assigned to batch 2, the third job is located on batch 1 and forth and fifth jobs are assigned to batches 3 and 4, respectively. Since, number 5 is not mentioned in this string, therefore, the fifth batch is remained empty and will be removed.
Afterwards, in second string, a random schedule of all the batches that contain at least one job is generated.
This procedure continues while the equilibrium condition in this temperature to be occurred. In this problem, the equilibrium condition is occurred when the gaps between proposed objective functions in consecutive iterations in a certain temperature, are as less as possible. This condition can be demonstrated by:
| (16) |
where, Z[i+1] is the value of objective function in I+1th iteration of algorithm, j is the number of objectives that are considered to calculate the total gap and ε is a very small number.
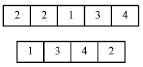 | |
| Fig. 1: | The coding scheme of proposed SA |
| Table 1: | The Taguchi experiment inputs |
 | |
 | |
| Fig. 2: | The pseudo-code of proposed SA |
By reaching the equilibrium in the temperature, the temperature is decreased and the procedure starts from the lower temperature and continues until the next equilibrium.
Neighborhood search is also implemented by swapping two randomly selected positions in the second string (batch string) in order to meet other nodes of solution space (Fig. 1).
The performance of the proposed SA is depicted in Fig. 2.
In order to calibrate the proposed SA, a Taguchi approach is presented in which attempts to identify controllable factors (control factors) that minimize the effect of the noise factors. During the experimentation, the noise factors are manipulated to force variability to occur and then to finding the optimal control factor settings that make the process or product robust, or resistant to variations from the noise factors.
In this study, the S/N ratio which is considered as nominal, is the best of the kind and is calculated by the following equation:
| (17) |
The effective factors and their levels are also described in Table 1.
The associated degree of freedom for these two factors is equal to 8. According to Taguchi standard table of orthogonal array, the L9 which fulfils all the minimum necessary requirements should be selected.
In order to analysis the Taguchi outputs, three important measures are considered as the S/N ratio (as robust measure), the average responses for each combination of control factor and the variability in the response due to the noise (standard deviation).
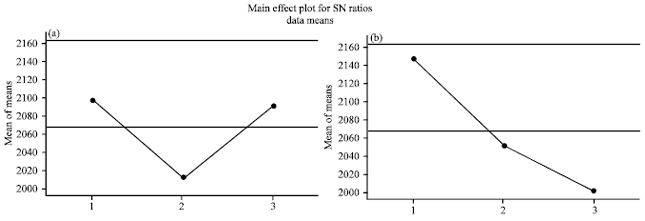
The results are depicted in Fig. 3-5. A measure of robustness is used to identify control factors that reduce variability in a product or process by minimizing the effects of uncontrollable factors. Figure 3 indicates the robustness of each combination of factors.
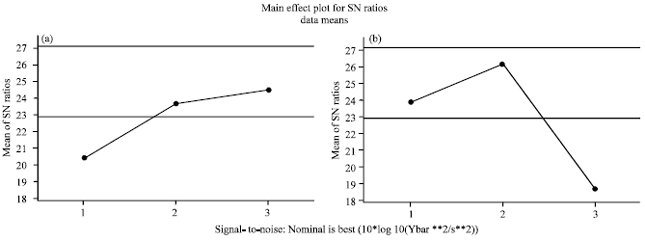 | |
| Fig. 3(a-b): | The results for response based on S/N ratio |
 | |
| Fig. 4(a-b): | The results for response based on means |
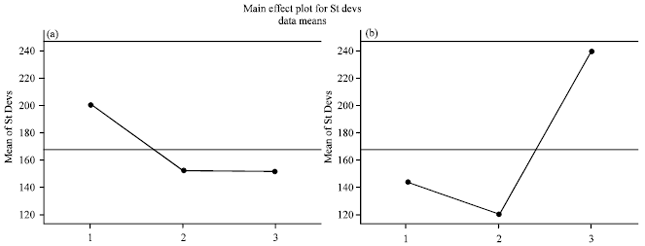 | |
| Fig. 5(a-b): | The results for response based on standard deviations |
Clearly, it is desired to select a pair of factors that generate the maximum robustness. Therefore, based on this, Fig. 3a and 2b are selected.
Figure 4 shows the average responses for each combination of control factors. Since, the objective of the function is minimization, the minimum value for this measure is desired, so 2a and 3b are selected.
Finally, Fig. 5 shows the variability in the response due to the noise that is desired to be minimal, hence, 3a and 2b are selected. Based on the mentioned measures, the most efficient combination of the proposed factors are 3a and 2b which better satisfies the response values.
COMPUTATIONAL EXPERIMENT
All the instances for this problem are coded by visual basic 6 and are run on personal computer with CORE I 7 processor and 4 GB of RAM. The required data were generated randomly based on below scheme:
| • | Processing time of jobs from uniform distribution [1-100] |
| • | Due date of jobs from uniform distribution [1-αΣP] where α is considered equal to 0.2 manually |
The instances are also solved using Lingo 10 software to determine the efficiency and capability of proposed SA to reach the global optimum.
To make the sensitivity analyze, some important factors including problem dimension (number of considered batches), rate of deterioration and decreasing rate of job values are considered.
Sensitivity analysis based on the problem dimension: In order to implement this analysis first, some instances with small dimensions are considered and the results are compared to equivalent Lingo results. But Lingo is incapable of solving the problem for jobs greater than 5 because of immense complexity of problem. Therefore, a lower bound is generated in order to examine the SA performance for larger scales of problem. Rate of deterioration and rate of job values are also considered as 0.2 and 0.002, respectively.
Table 2 depicts the comparison of the results of SA and Lingo based on the problem dimension. Where, the second column indicates the number of batches (jobs) and the third and forth columns show the performance of Lingo software including VOF (Value of Objective Function) and its run time in seconds.
For each instance, the SA was run 5 times and the best obtained solution was considered as the VOF which has been recorded in column 5.
The gap of results between SA and global optimum is calculated by:
| (18) |
Figure 6 and 7 depict the comparison of the results and run times, respectively.
Based on Table 2 and depicted figures, the run time of SA and Lingo increases with greater dimensions of problem and the run time of Lingo increases exponentially. For small dimensions of problem, the SA performs very efficient and offers the solutions with low error in a reasonable time.
In order to examine the capability of proposed SA in this field, a lower bound is generated.
| Table 2: | Sensitivity analyze based on small problem dimension |
 | |
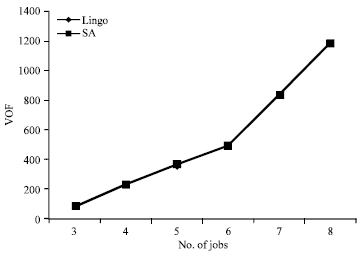 | |
| Fig. 6: | The VOF sensitivity analysis based on small problem dimensions |
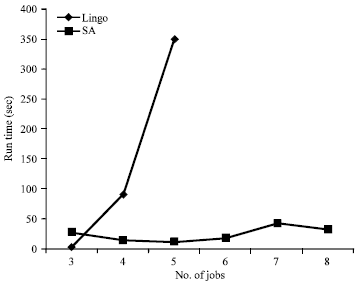 | |
| Fig. 7: | The run time sensitivity analysis based on small problem dimensions |
Theorem 1: Removing the deterioration yields a lower bound for the objective function of earliness and tardiness problems.
Proof: C1 and C2 are considered as the completion time of job with and without the deterioration, respectively. L1 and L2 are also considered as the lateness value of job with and without the deterioration.
| Table 3: | Sensitivity analyze based on medium and large problem dimension |
 | |
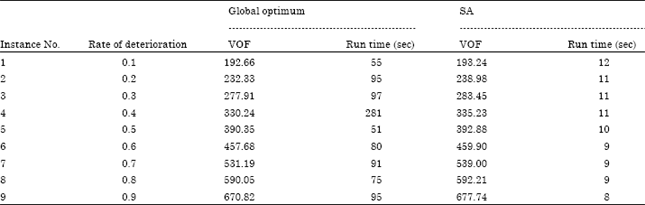
| Table 4: | Sensitivity analysis based on rate of deterioration for N = 4 |
 | |
It is obvious that c2 ≤ c1. We must show that L2 ≤ L1. The proof is straightforward since:
L2≤L1→c2-d≤c1-d≤c2≤c1 |
Table 3 presents the performance of proposed SA against the generated lower bound.
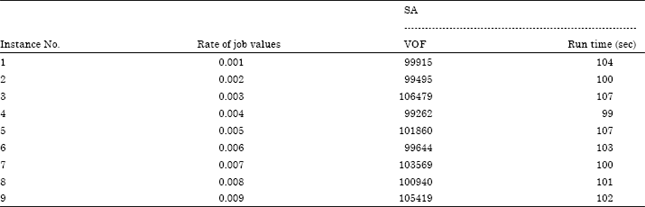
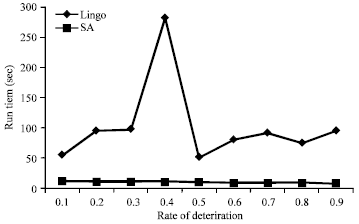
Sensitivity analysis based on the rate of deterioration: The effect of deterioration is evaluated by dimension of 4 jobs and value of 0.002 for the rate of job values. Table 4 illustrates the results of SA and lingo for several rates of deterioration.
According to depicted plots, the rate of deterioration is highly effective on the performance of Lingo and alters its run time clearly. But for SA it does not seem to have any sensitivity to rate of deterioration in the field of run time.
On the other hand, more rates increases the value of objective function in both of the global optimum and SA solution.
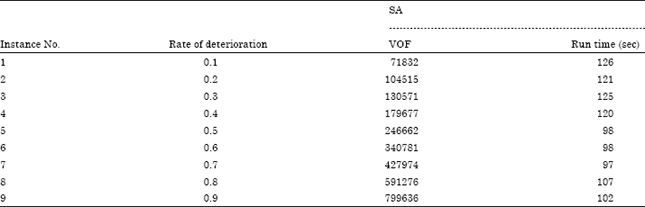
For larger number of jobs, the results are shown in Table 5.
Based on presented Fig. 8 and 9, more rate of deterioration causes the objective function value to increase, but does not affect the run time.
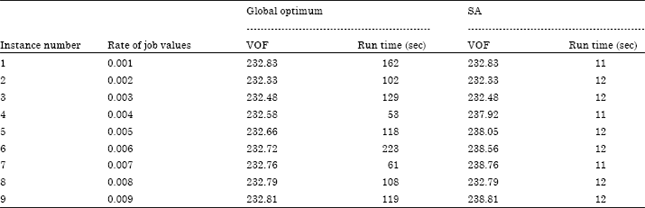
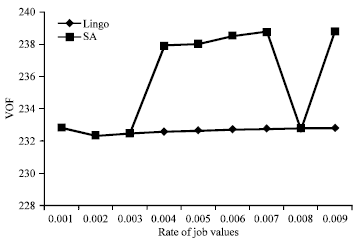
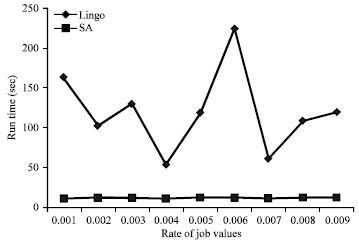
Sensitivity analysis based on the rate of job values: The effect of rate of job values is evaluated by dimension of 4 jobs and value of 0.2 for rate of deterioration. Table 6 illustrates the results of SA and Lingo for several rates of job values.
| Table 5: | Sensitivity analyze based on rate of deterioration for N = 50 |
 | |
| Table 6: | Sensitivity analysis based on rate of job values for N = 4 |
 | |
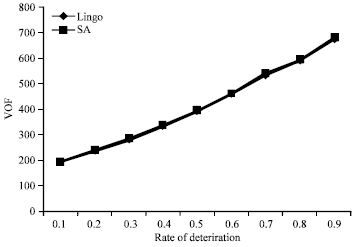 | |
| Fig. 8: | The VOF sensitivity analysis based on rate of deterioration for N = 4 |
According to Fig. 10 and 11, although the rate of job values does not seem an effective factor in field of objective function, but alters the run time clearly especially in the Lingo performance.
For larger number of jobs, the results are shown in Table 7.
Based on Table 7, the rate of job values does not show clear sensitivity in both fields of run time and objective function for large number of jobs.
| Table 7: | Sensitivity analysis based on rate of deterioration for N = 50 |
 | |
 | |
| Fig. 9: | The run time sensitivity analysis based on rate of deterioration for N = 4 |
 | |
| Fig. 10: | The VOF sensitivity analysis based on rate of job values for N = 4 |
CONCLUSION
This research studied the problem of single machine batch scheduling with the objective of minimizing the total tardiness and delivery costs and maximizing the job values in makespan simultaneously, in which a mathematical model was presented. The jobs were also considered deteriorated that their processing times were dependent on the sequence in which the process was accomplished and some precedence constraints were considered between the jobs.
 | |
| Fig. 11: | The run time sensitivity analysis based on rate of job values for N = 4 |
In order to solve the proposed model, a calibrated simulation annealing was used and its performance was compared to global optimum for small dimensions of problem. In addition, a lower bound was generated in order to examine the performance of SA for larger scales of problem.
Afterwards, a number of sensitivity analyses were implemented, based on effective factors of the problem, including problem dimension, rate of deterioration and decreasing rate of job values.
For future research, the solution method can be considered as the hybrid of meta-heuristics that may perform more powerfully than a single meta-heuristic.
On the other hand in batching phase, some clustering rules and algorithms can be used as suitable tools in order to assign the jobs to the batches.
REFERENCES
- Browne, S. and U. Yechiali, 1990. Scheduling deteriorating jobs on a single processor. Operations Res., 38: 495-498.
Direct Link - Ji, M. and T.C.E. Cheng, 2010. Batch scheduling of simple linear deteriorating jobs on a single machine to minimize makespan. European J. Operational Res., 202: 90-98.
Direct Link - Coffman, E.G., M. Yannakakis, M.J. Magazine and C. Santos, 1990. Batch sizing and sequencing on a single machine. Annals Operations Res., 26: 135-147.
Direct Link - Husang, X., J.B. Wang and X.R. Wang, 2010. A generalization for single-machine scheduling with deteriorating jobs to minimize earliness penalties. Int. J. Adv. Manuf. Technol., 47: 1225-1230.
Direct Link - Lu, L.F. and J.J. Yuan, 2007. The single machine batching problem with identical family setup times to minimize maximum lateness is strongly NP-hard. European J. Operational Res., 177: 1302-1309.
Direct Link - Mosheiov, G., 1994. Scheduling jobs under simple linear deterioration. Comput. Operat. Res., 21: 653-659.
Direct Link - Ng, C.T., T.C.E. Cheng, J.J. Yuan and Z.H. Liu, 2003. On the single machine serial batching scheduling problem to minimize total completion time with precedence constraints, release dates and identical processing times. Operations Res. Lett., 31: 323-326.
Direct Link - Nong, Q., C.T. Ng and T.C.E. Cheng, 2008. The bounded single-machine parallel-batching scheduling problem with family jobs and release dates to minimize makespan. Operations Res. Lett., 36: 61-66.
Direct Link - Potts, C.N. and M.Y. Kovalyov, 2000. Scheduling with batching: A review. Eur. J. Operat. Res., 120: 228-249.
CrossRef - Tian, J., R. Fu and J. Yuan, 2007. On-line scheduling with delivery time on a single batch machine. Theoretical Computer Sci., 374: 49-57.
Direct Link - Wang, D. and J.B. Wang, 2010. Single-machine scheduling with simple linear deterioration to minimize earliness penalties. Int. J. Adv. Manuf. Technol., 46: 285-290.
CrossRef - Wang, J.B., X. Huang, X.Y. Wang, N. Yin and L. Wang, 2009. Learning effect and deteriorating jobs in the single machine scheduling problems. Applied Mathematical Modeling, 33: 3848-3853.
Direct Link - Wu, C.C., Y.R. Shiau, L.H. Lee and W.C. Lee, 2009. Scheduling deteriorating jobs to minimize the makespan on a single machine. Int. J. Adv. Manuf. Technol., 44: 1230-1236.
CrossRefDirect Link - Feylizadeh, M.R. and M. Bagherpour, 2011. Application of optimization techniques in production planning context: A review and extension. Int. J. Manufact. Syst., 1: 1-8.
CrossRefDirect Link - Hemamalini, T., A.N. Senthilvel and S. Somasundaram, 2010. Deep memory greedy search and allocation of job shop scheduling for optimizing shop floor performance. Asian J. Ind. Eng., 2: 9-16.
CrossRefDirect Link - Khurana, M.K., P.K. Mishra and A.R. Singh, 2011. Barriers to information sharing in supply chain of manufacturing industries. Int. J. Manufact. Syst., 1: 9-29.
CrossRefDirect Link - Iwarere, H.T. and K.O. Lawal, 2011. Performance measures of maintenance of public facilities in Nigeria. Res. J. Bus. Manage., 5: 16-25.
CrossRefDirect Link - Hammoud, D., R. Maamri and Z. Sahnoun, 2011. Machine learning in an agent: A generic model and an intelligent agent based on inductive decision learning. J. Artificial Intel., 4: 29-44.
CrossRefDirect Link - Rajarathinam, A. and R.S. Parmar, 2011. Application of parametric and nonparametric regression models for area, production and productivity trends of castor (Ricinus communis L.) crop. Asian J. Applied Sci., 4: 42-52.
CrossRefDirect Link - Nja, M. and G. Udofia, 2009. Formulation of the mixed integer Goal programming model for flour producing companies. Asian J. Mathematics Statistics, 2: 55-64.
Direct Link - Mahdavi, I. and B. Shirazi, 2010. A review of simulation based intelligent decision support system architecture for the adaptive control of flexible manufacturing systems. J. Artificial Intelligence, 4: 201-219.
Direct Link - Mazdeh, M.M., A. Hamidinia and A. Karamouzian, 2011. A mathematical model for weighted tardy jobs scheduling problem with a batched delivery system. Int. J. Ind. Eng. Comput., 2: 491-498.
CrossRefDirect Link - Mazdeh, M.M., S. Shashaani, A. Ashouri and K.S. Hindi, 2011. Single-machine batch scheduling minimizing weighted flow times and delivery costs. Applied Mathematical Modelling, 35: 563-570.
Direct Link - Mazdeh, M.M., M. Sarhadi and K.S. Hindi 2007. A branch-and-bound algorithm for single-machine scheduling with batch delivery minimizing flow times and delivery costs. Eur. J. Operat. Res., 183: 74-86.
Direct Link - Taleizadeh, A.A., S.T.A. Niaki and S.V. Hosseini, 2008. The multi-product multi-constraint problem with Incremental discount and batch order. Asian J. Applied Sci., 1: 110-112.
CrossRefDirect Link