
M.A. Edriss
Department of Animal Science, Isfahan University of Technology, Isfahan, Iran
P. Hosseinnia
Department of Animal Science, Isfahan University of Technology, Isfahan, Iran
M. Edrisi
Departments of IT and Biomedical Eng., University of Isfahan, Isfahan, Iran
H.R. Rahmani
Department of Animal Science, Isfahan University of Technology, Isfahan, Iran
M.A. Nilforooshan
Department of Animal Breeding and Genetics, Swedish University of Agricultural Sciences, Uppsala, Sweden
Asian Journal of Animal and Veterinary Advances
Year: 2008 | Volume: 3 | Issue: 4 | Page No.: 222-229







ABSTRACT
A mathematical model for prediction of second parity milk yield and fat percentage, with the use of first parity information seems to be helpful in order to predict the performance of prospective productive cows. As a tool for this prediction, back propagation neural network and multiple linear regression methods were compared based on their prediction differences with observed values. While, multiple linear regressions are based on linear relationships between variables, artificial neural network system also considers non-linear relationships between parameters. Data was collected from 4 medium sized dairy herds in Isfahan, Iran, which was divided into three parts in order to train, verify and test the artificial neutral network system and estimation of regression coefficients, verify and test the multiple linear regression method. The results of the simulation showed that evaluations from both multiple linear regression and artificial neural network methods are good predictors for second parity production estimated from first parity information. However, artificial neural network predictions showed lower differences with the observed values and better quality parameters than multiple linear regression predictions, which made this assumption that artificial neural network system is more accurate in prediction.
PDF Abstract XML References Citation
How to cite this article
M.A. Edriss, P. Hosseinnia, M. Edrisi, H.R. Rahmani and M.A. Nilforooshan, 2008. Prediction of Second Parity Milk Performance of Dairy Cows from
First Parity Information Using Artificial Neural Network and Multiple
Linear Regression Methods. Asian Journal of Animal and Veterinary Advances, 3: 222-229.
DOI: 10.3923/ajava.2008.222.229
URL: https://scialert.net/abstract/?doi=ajava.2008.222.229
DOI: 10.3923/ajava.2008.222.229
URL: https://scialert.net/abstract/?doi=ajava.2008.222.229
INTRODUCTION
Production traits in dairy cattle are under the influence of many genetic and environmental factors and the interactions between them both linearly and non-linearly. Dairy production traits including milk yield and milk fat percentage are of the most important economic traits in Iran`s dairy industry. So, prediction of these traits is of importance to find prospective high yielding cows and improving the economic proficiency of dairy farms. Also, much of the selection of superior bulls is based on their ability to produce high yielding cows (Salehi et al., 1998). Accuracy rate of finding high producing cows is important, because feeding, breeding, maintenance, veterinary and other costs can be saved for superiors and also by mis-culling cows of high genetic value, good sources of gene pool will be lost.
In many countries, analysis of milk yield for 305 day lactation period is a foundation for dairy cattle genetic evaluations. So, implementing mathematical models for prediction of 305 day production in subsequent lactations from previous lactations or predicting total lactation yield from early records would be useful.
In comparison with regression methods or time-series analyses, Artificial Neural Network (ANN) represents a different new approach. The relationship between two or more independent variables on a dependent variable can be obtained applying Multiple Linear Regression (MLR) method. Regressions show the extent and direction of associations between characters in the units of measurements. A MLR explains the linear cause-consequence relationships between some independent variables (x1, x2, ..., xn) and a dependent variable (y). Artificial Neural Network (ANN), like biological neural network, is made up from some sets of neurons. These neurons process the presented input and matching output to input in a supervised manner and extract non-linear relationships between those input and output. ANN consists of a set of neurons which are connected by weighted links that pass signals from one neuron to another. During training, the weights become adjusted to reduce error between actual and desired output. This error is minimized until it reaches to a certain objective value (Md Saad et al., 2007).
ANN proposes an approach that is completely different from those offered by conventional methods. It solves particular problems through a learning system by typical inputs and specific desired outputs. (Grzesiak et al., 2003). The usefulness of any mathematical model depends on how well it can mimic the biological process of milk production and adjusts for factors affecting it (Olori et al., 1999). In ANN identifying patterns and relationships between the input and the corresponding output in a sample data set refers to the fact that optimal net performance depends on the recognition and extraction of non-linear relations through the training step which form the ANN structure (Lacroix et al., 1995). Using this relation in the simulation stage, ANN can anticipate the output of the problem in a complex biological system from known input. In practice, ANNs have been primarily used in engineering, economics, or even in detection of heart abnormalities (Md Saad et al., 2007). Recently, they also have been used in some areas of animal genetics and husbandry, such as detection of clinical disease (Yang et al., 1999), estimating meat quality (Brethour, 1994), prediction of slaughter value of bulls (Adamczyk et al., 2005), evaluation of physiological status of cows (Molenda et al., 2001), detection of mastitis in dairy cattle (López-Benavide et al., 2003), to predict swine daily gain in different ambient temperatures (Korthals et al., 1994), prediction and classification of dairy cows based on milk yield in one period (Salehi et al., 1998) and prediction of 305 day milk production from part lactation records (Lacroix et al., 1995).
The aim of this research was comparing the predictive ability and the accuracy of ANN and MLR methods for predicting 305 day adjusted kilogram Milk Yield (MY) and Milk Fat Percentage (%MF) of the second lactation using information from first lactation as a tool for recognition of more producer cows of high genetic merit as the parents of the next generation.
MATERIALS AND METHODS
The data was provided by the Animal Husbandry Division, Agricultural Organization of the Ministry of Agriculture in Isfahan, Iran, which was consisted of collected information from 32 Holstein dairy herds milked during 1995 to 2002. From the available herds, four medium sized herds were selected randomly for final investigations. Records were restricted to cows with completed second lactation. Followed by this restriction, a sample of 1880 cows with records was made available for further studies. The sample data was consisted of cows` registration number, purity (% Holstein blood which was 65.5±19.43 in the sample), first and second parities milk yield and fat percentage, corrected for 305 days in milk and some other information on the first parity of cows. Then, the data structure was rechecked and the data was introduced to MATLAB (2006) software for further processing.
Ten variables of the first parity (as inputs) plus two variables of 305 day MY and %MF from the second parity (as outputs) were assigned to each cow for both ANN and MLR (Table 1). In order to achieve a better learning for ANN, first lactation 305 day MY was classified into 9 production levels including milk production <2000 kg as the first and >9000 kg as the ninth level and the middle levels of 1000 kg difference. Salehi et al. (1998) concluded that data classification would lead to a better network learning.
| Table 1: | Variables used in the experimental data sets |
 | |
| *: %Holstein blood | |
Normality distribution of each set was tested using Statistical Analysis Software (SAS, 1997). For ANN, the minimum and maximum values of each variable (Table 1) were mapped to the mean and standard deviation of 0 and 1, respectively. In order to construct the network, the neural network toolbox of MATLAB (2006) was used. The constructed network was a back propagation artificial neural network which had 3 layers of input, hidden and output with 10, 10 and 2 neurons in each, respectively. For input and hidden layers, tangent hyperbolic transfer function and for output layer, purline transfer function were used (MATLAB, 2006). The net learning function updated the weight and bias values relative to Levenberg-Marquardt optimization algorithm (Hagan and Menhaj, 1994). The net trained in 100,000 cycles of processing elements.
Cows were assigned to two groups:
Group 1: Included 1850 cows. Data of the second parity corresponding to the first period were used to design ANN and MLR for both MY and %MF. This part of data was divided into 925 training and 925 verification sets. The training set was used to obtain and modify the weights by ANN and to obtain the related regression coefficients by MLR. Verification set was used to control the size of network error during the training step and consequently to control the approximation ability of the network (Grzesiak et al., 2006).
Group 2: Thirty cows were randomly selected from 1880 cows as a simulation set. The simulation set was used to test both ANN and MLR by predicting second parity MY and %MF from first parity information and then comparing the results of ANN anticipations and the results taken from MLR regression coefficients with the observed values.
MATLAB (2006) and SAS (1997) softwares were employed to run ANN and MLR analyses, respectively. The criterions used to compare the results of ANN and MLR anticipations with the actual observed data were: (1) adjusted coefficient of determination, (2) root of mean square error, (3) SDratio, (4) Pearson`s coefficient of correlation between observed and predicted values, (5) relative mean error of prediction and (6) Theil`s inequality coefficient.
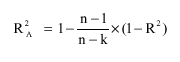 | (1) |
| R2A | = | Adjusted coefficient of determination |
| n | = | No. of records |
| k | = | No. of predictors or independent variables |
| R2 | = | Coefficient of determination |
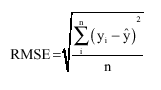 | (2) |
| Where: | ||
| RMSE | = | Root of mean square error |
| n | = | No. of records |
| yi | = | Observed value |
| í | = | Estimated value by ANN or MLR |
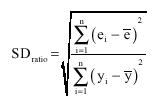 | (3) |
| Where: | ||
| Sdratio | = | Ratio of error standard deviation to the total standard deviation |
| ei | = | Individual error |
| = | Mean of error values | |
| yi | = | Observed value |
| = | Mean of observed values | |
rp = δip/δi δp | (4) |
| Where: | ||
| rp | = | Pearson`s correlation coefficient between observed and predicted values |
| δip | = | Covariance between observed and predicted values |
| δi | = | Standard deviation of observed values |
| δp | = | Standard deviation of predicted values |
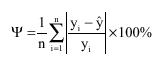 | (5) |
Where, Ψ is the relative mean error of prediction and the other symbols are as the same as for the previous formulas.
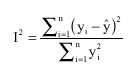 | (6) |
Where, I2 is Theil`s inequality coefficient (Theil, 1979) and the other symbols are as the same as for the previous formulas.
The above coefficient is the sum of three other model`s inequality coefficients.
I2 = I2O+ I2B+ I2E | (7) |
The components of Eq. 7 are as follows:
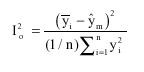 | (8) |
| Where: | ||
| I2O | = | Prediction bias |
| = | Mean of observed values | |
| ím | = | Mean of predicted values |
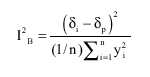 | (9) |
Where, I2B represents the error resulting from predictions` inadequate flexibility.
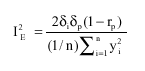 | (10) |
Where, I2E represents the error resulting from insufficient convergency between direction of changes in the observed values and changes in the predicted values.
RESULTS AND DISCUSSION
Regression coefficients estimated by MLR method for MY and %MF are shown in Table 2. These estimated regression coefficients obtained from the train set were used to make evaluations for the test set. ANN and MLR predictions were compared to the observed values by their mean differences to the mean of observed values (Table 3). Although MLR showed very low differences close to zero for train and verification data sets, finally, ANN predictions had lower differences with the observed data, may be due to the fact that MLR has no learning ability and it only finds linear relationships between data. The variability parameters (SD, CV) were also closer to those for observed data for ANN than MLR. Grzesiak et al. (2003) using test day records to estimate 305-d lactation yield, derived only 13.2 kg higher and 91.3 kg lower milk yield than the average of actual yield for ANN and MLR predictions, respectively.
Some quality parameters are shown for ANN and MLR for both MY and %MF by Table 4. SDratio was lower and R2A was higher for ANN relative to MLR. Also for ANN, SDratio deceased and R2A increased in the test step. These findings show the relative advantage of ANN to MLR. Better quality parameters for ANN relative to MLR have been also reported by Grzesiak et al. (2003, 2006). Regardless of the method of evaluation, SDratio and %RMSE were lower and R2A was higher for %MF relative to MY, which show that the input variables may better justified the changes in %MF than MY. Due to training and verification abilities of ANN, its quality of prediction drastically improved in the test step. However, it was not expected from MLR to show any considerable improvement in the test step relative to the previous steps. SDratio value less than 0.4 shows a good quality of the model, whereas values lower than 0.1 mean that the model would be close to ideal (Grzesiak et al., 2006). In this study, low R2A values were derived for MLR, which showed that the chosen independent variables alone, could not explain well the changes in the dependent variable by MLR method. R2A = 0.70 implies a very good fitness for the model. While, R2A< 0.40 shows a non-appropriate model (Olori et al., 1999). Although, R2A was low in the verification set, the final predictions by ANN for the test data set had a high R2A.
| Table 2: | Estimated regression coefficients using MLR method |
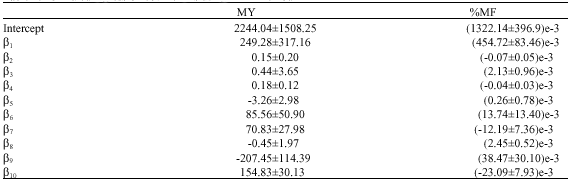 | |
| MY: Milk Yield; %MF: Milk Fat Percentage, Correlation coefficients (β) are in the same sequence as the input variables represented in Table 1 | |
| Table 3: | Descriptive parameters for the observed and predicted (by ANN and MLR) data |
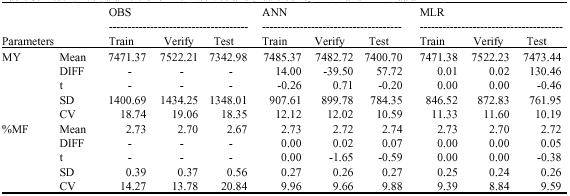 | |
| MY: Milk yield; %MF: Milk fat percentage; OBS: Observed value; ANN: Artificial neural network prediction; MLR: Multiple linear regression prediction; DIFF: Difference from the mean of observed values; t: All DIFF`s have no significant difference from zero (p>0.05) | |
| Table 4: | Quality parameters for ANN and MLR methods |
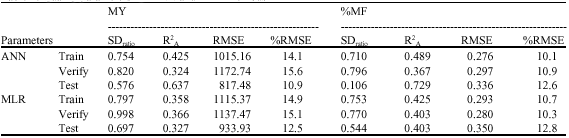 | |
MY: Milk yield; %MF: Milk fat percentage; SDratio: The ratio of error standard deviation to the total standard deviation; R2A: Adjusted coefficient of determination; RMSE: Root of mean square error; %RMSE: RMSE divided by the mean of performance | |
In other studies which have used partial records to predict full lactation records, higher R2A values were estimated, including R2A = 0.79 by Wood (1967) and R2A = 0.94 by Olori et al. (1999). Grzesiak et al. (2003) reported RMSEs equal to 501.7 and 544.76 kg milk yield in the test step for ANN and MLR, respectively. Also, Salehi et al. (1998) estimated RMSE values ranging from 445 to 554 kg depending on the network system and the average of herd milk production. The reason for the differences between the results of these studies and the results of the current study refers to different data structures used to train ANN. For example, they have used test day records to calculate 305 day milk production with more or less extended data from other regions with more input variables.
| Table 5: | Predictive measures for ANN and MLR |
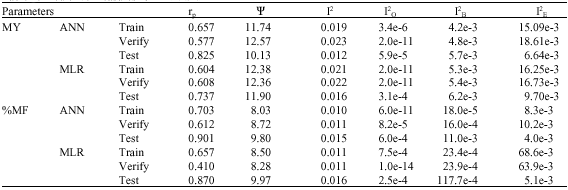 | |
| MY: Milk yield; %MF: Milk fat percentage; rp: Correlation coefficient with the observed data (p<0.001); Ψ: Relative mean error of prediction; I2: Theil`s inequality coefficient; I2O: Prediction bias; I2B: Prediction inflexibility; I2E: Insufficient convergency between direction of changes in the observed and predicted values | |
Table 5 shows some parameters related to predictive ability of ANN and MLR for both MY and %MF. As shown in this table, on average, rp values were higher and Ψ and I2 values were lower for ANN relative to MLR, which were in favor of ANN. These values showed a same situation for %MF, which support the results of Table 4 regarding better fitness of both ANN and MLR for %MF relative to MY. For both ANN and MLR, rp increased for the test data set. Both Ψ and I2 decreased in the test step for MY, while they increased for %MF.
Considering final predictions obtained in the test step (Table 5), except I2O for %MF, all of the three criterions of I2O, I2B and I2E were lower in both MY and %MF for ANN relative to MLR, which shows that ANN predictions are less bias and more flexible and the direction of changes in the observed and predicted data are more in convergence for ANN than MLR.
The most important part of Theil`s coefficient (I2) was related to I2E, which represents an error resulting from a lack of full convergency in the direction of changes between the observed and predicted values, particularly for the neural network. This result was in agreement with the results obtained by Grzesiak et al. (2006).
The major use of any predictive process is to support accurate decisions which are dependent on a prior knowledge to make possible outcome(s). The results of this study showed that both MLR and ANN can be used to predict second parity production from first parity information. MLR models are simple to design and define parameters. However, the results showed that ANN systems have the ability to predict second parity 305 day milk yield and fat percentage with a higher accuracy. Correlations between the observed values and predictions, together with the other quality parameters and predictive measures had better situations for ANN relative to MLR. Also, ANN predictions showed lower deviations from the observed data, but this difference between ANN and MLR was slight and can be negligible. Adding new data requires a new statistical model, whereas a neural network system can update itself with new data. Finally, ANN can be improved with more additional input variables and training with more actual data to get more accurate predictions.
ACKNOWLEDGMENT
The authors would like to acknowledge Isfahan University of Technology for supporting financially P. Hosseinia`s M.Sc. Thesis.
REFERENCES
- Adamczyk, K., K. Molenda, J. Szarek and G. Skrzynski, 2005. Prediction of bulls slaughter from growth data using artificial neural network. J. Cent. Eur. Agric., 6: 133-142.
Direct Link - Brethour, J.R., 1994. Estimating marbling score in live cattle from ultrasound images using pattern recognition and neural network procedures. J. Anim. Sci., 72: 1425-1432.
PubMed - Grzesiak, W., P. Blaszczyk and R. Lacroix, 2006. Methods of predicting milk yield in dairy cows-predictive capabilities of wood's lactation curve and Artificial Neural Networks (ANNS). Comput. Elect. Agric., 54: 69-83.
CrossRef - Korthals, R.L., G.L. Hahn and J.A. Nienaber, 1994. Evaluation of neural networks as a tool for management of swine environments. Trans. ASAE, 37: 1295-1299.
Direct Link - Lacroix, R., K.M. Wade, R. Kok and J.F. Hayes, 1995. Prediction of cow performance with a connectionist model. Trans. ASAE, 38: 1573-1579.
Direct Link - Lopez-Benavides, M.G., S. Samarasinghe and J.G.H. Hickford, 2003. The use of artificial neural networks to diagnose mastitis in dairy cattle. Proceedings of the International Joint Conference on Neural Networks, July 20-24, 2003, IEEE Computer Society, USA., pp: 582-586.
Direct Link - Md Saad, M.H., M.J. Mohd Nor, F.R.A. Bustami and R. Ngadiran, 2007. Classification of heart abnormalities using artificial neural network. J. Applied Sci., 7: 820-825.
CrossRefDirect Link - Olori, V.E., S. Brotherstone, W.G. Hill and B.J. McGuirk, 1999. Fit of standard models of the lactation curve to weekly records of milk production of cows in a single herd. Livestock Prod. Sci., 58: 55-63.
CrossRef - Salehi, F., R. Lacroix and K.M. Wade, 1998. Effects of learning parameters and data presentation on the performance of back-propagation networks for milk yield prediction. Trans. ASAE, 41: 253-259.
Direct Link - SAS, 1997. SAS User's Guide: Statistics. Version 6. 12th Edn., SAS Institute Inc., Cary, NC.
Direct Link - Yang, X.Z., R. Lacroix and K.M. Wade, 1999. Neural detection of mastitis from dairy herd improvement records. Trans. ASAE, 42: 1063-1072.
Direct Link - Hagan, M.T. and M.B. Menhaj, 1994. Training feedforward networks with the Marquardt algorithm. IEEE Trans. Neural Networks, 5: 989-993.
CrossRef