
Ehab A. Mahmood
Department of Mathematics, University Putra Malaysia, Jalan Upm, 43400 Serdang, Selangor,Malaysia
LiveDNA: 964.15431
Habshah Midi
Department of Mathematics, University Putra Malaysia, Jalan Upm, 43400 Serdang, Selangor,Malaysia
Sohel Rana
Department of Applied Science, East West University, Dhaka, Bangladesh
Abdul Ghapor Hussin
Faculty of Defence Science and Technology, National Defence University of Malaysia, Jalan Upm, 43400 Serdang, Selangor, Malaysia
Asian Journal of Applied Sciences
Year: 2017 | Volume: 10 | Issue: 3 | Page No.: 126-133







ABSTRACT
Background and Objective: The existence of outliers in any type of data influences the efficiency of an estimator. Few methods for detecting outliers in a simple circular regression model have been proposed in the study but it suspected that they are not very successful in the presence of multiple outliers in a data set. This study aimed to investigate new statistic to identify multiple outliers in the response variable in a simple circular regression model. Materials and Methods: The proposed statistic is based on calculating robust circular distance between circular residuals and circular location parameter. The performance of the proposed statistic is evaluated by the proportion of detected outliers and the rate of masking and swamping. The simulation study is applied for different sample sizes at 10 and 20% ratios of contamination. Results: The results from simulated data showed that the proposed statistic has the highest proportion of outliers and the lowest rate of masking comparing with some existing methods. Conclusion: The proposed statistic is very successful in detecting outliers with negligible amount of masking and swamping rates.
PDF Abstract XML References Citation
Received: January 30, 2017;
Accepted: March 27, 2017;
Published: June 15, 2017
How to cite this article
Ehab A. Mahmood, Habshah Midi, Sohel Rana and Abdul Ghapor Hussin, 2017. Robust Circular Distance and its Application in the Identification of Outliers in the Simple Circular Regression Model. Asian Journal of Applied Sciences, 10: 126-133.
DOI: 10.3923/ajaps.2017.126.133
URL: https://scialert.net/abstract/?doi=ajaps.2017.126.133
DOI: 10.3923/ajaps.2017.126.133
URL: https://scialert.net/abstract/?doi=ajaps.2017.126.133
INTRODUCTION
The simple circular regression model is one of the circular models that is proposed to represent the relationship between two circular variables. This model can be used in many scientific fields. For example, in studying bird migration, the study is interested to observe wind direction and flight direction of the birds or in medical studies, some circular variables are recorded for the study of vector cardiograms. Sometimes, it is interested to predict one variable given other. This can be done by simple circular regression model. However, the existence of outliers can cause a huge effect of the statistical analysis and the final outcomes. In real-life applications, samples from any field might include noise or outliers. Outlier is an observation which appears inconsistent (extreme) with the other observations in the statistical data and effect on the results. There are often two problems with methods of detecting outliers: ‘Masking’ and ‘Swamping’ problems. Masking is the inability of the procedure to detect correct outliers and swamping is the identification of inliers as outliers1. It is now evident that the presence of outliers causes misleading conclusions to be drawn from the results. Thus, researchers are interested in improving the ways of detecting outliers in statistical data. Many researchers have proposed methods to identify outliers in linear regression model. However, there are only few methods in the study that develop methods of detecting outliers in a simple circular regression model.
Jammalamadaka and Sarma2 proposed a regression model when both the response and the explanatory variables are circular. Downs and Mardia3 suggested a regression model in which both the response and the explanatory variables are circular with means β and α, respectively. Hussin et al.4 extended the previous models and suggested a simple circular regression model when both the response and the explanatory variables are circular variables. Kato et al.5 suggested another regression model in the case when both the response and the explanatory variables are circular and assumed that the angular error follows a wrapped Cauchy distribution. Hussin et al.6 extended the COVRATIO statistic, which is used to detect outliers in the linear regression model to the detection of outliers in the functional relationship model. Abuzaid et al.7 suggested using the COVRATIO statistic to detect outliers in the response variable in a simple circular regression model by using a row deletion approach. Rambli8 achieved many objectives in his studies by developing procedures for identifying outliers in circular regression models by using COVRATIO and the mean circular error statistic DMCEs that was proposed by Abuzaid9. Abuzaid et al.10 also proposed the mean circular error statistic DMCEc to identify outliers in the response variable of a simple circular regression model by using a row deletion approach. Later, Abuzaid11 compared the performance of COVRATIO statistic for a Simple Circular (SC) regression model and a Complex Linear (CL) regression model. It was found that the COVRATIO statistic performs better for the SC model than for the CL model. Hussin et al.12 proposed a complex linear regression model to fit the circular data by using the complex residuals to detect any possible outliers.
In this study, a new approach is proposed to identify outliers in the response variable in a simple circular regression model.
MATERIALS AND METHODS
Simple circular regression model: Hussin et al.4 proposed a simple circular regression model when both the response variable y and the explanatory variable x are circular variables and there is a linear relationship between them; their model is given in Eq. 1:
| (1) |
where, α and β are the parameters and ε is the circular random error, which follows the von Mises distribution with a circular mean μ and concentration parameter k. It is obvious that the angles ϑ and ϑ+2π give the same point on the circle. The von Mises distribution is called the normal distribution for the circular data. Let ϑ1, ϑ2,……, ϑn follow the von Mises distribution with mean direction μ and concentration parameter k, which can be denoted by [vM(μ,k)], then the probability density function of the von Mises distribution is given in Eq. 213:
| (2) |
where, I0 denotes the modified Bessel function of the first kind and order zero, which can be defined as:
The maximum likelihood estimates of the model parameters are given in following Eq. 3-612:
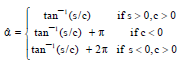 | (3) |
where,![]()
| (4) |
| (5) |
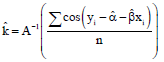 | (6) |
where, , with ![]() being the ratio of the modified Bessel function of the first kind and of order one to that of the first kind and of order zero.
being the ratio of the modified Bessel function of the first kind and of order one to that of the first kind and of order zero.
Conventional methods for the detection of outliers in a simple circular regression model
COVRATIO statistic: Abuzaid et al.7 proposed COVRATIO statistic to detect outliers in the response variable of a simple circular regression model. This statistic is based on the covariance matrix of the simple circular regression model. The COVRATIO statistic is given in Eq. 7:
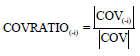 | (7) |
where, |COV| is the determinant covariance matrix of coefficients for the full data set:
and |COV(-i)| is the determinant covariance matrix of coefficients for the reduced data set formed by excluding the i-th row:
The i-th observation is identified as an outlier if |COVRATIO(-i)-1 | exceeds the cut-off point.
Mean circular error statistic: Abuzaid9 and Abuzaid et al.10 suggested two statistics, the DMCEs and DMCEc statistics, to identify outliers in the response variable y in a simple circular regression model.
DMCEs statistic: Abuzaid et al.10 proposed to use sine function as a measure of mean circular error to identify outliers, where sin is an increasing function on the interval [0, π/2]. The mean circular error is given as follows:
where, ![]() is the circular distance between yi and
is the circular distance between yi and ![]() , MCEs∈[0,1]. The existence of outliers is expected to increase the value of MCEs and the removal of outlier decreases the value of MCEs. Thus, the statistic to detect outliers is given in Eq. 8:
, MCEs∈[0,1]. The existence of outliers is expected to increase the value of MCEs and the removal of outlier decreases the value of MCEs. Thus, the statistic to detect outliers is given in Eq. 8:
| (8) |
where, MCEs(-i) is MCEs with the i-th observation removed. The cut-off point represents the maximum absolute difference between the value of the statistic for the full data and the reduced data set (formed by excluding the i-th observation) which shown in Eq. 9:
| (9) |
The i-th observation is identified as an influential observation if DMCEs(i) is greater than the cut-off point.
DMCEc statistic: Abuzaid9 proposed to use cosine function as an alternative measure of mean circular error. This statistic is given by:
where, MCEc ∈[0,2]. If yi is an outlier then the circular distance between yi and ![]() is expected to be relatively large. Hence, the existence of outlier in a data set will increase value of MCEc. Consequently, the removal outlier will decrease the value of the statistic. The statistic to identify outlier is given in Eq. 10:
is expected to be relatively large. Hence, the existence of outlier in a data set will increase value of MCEc. Consequently, the removal outlier will decrease the value of the statistic. The statistic to identify outlier is given in Eq. 10:
| (10) |
where, MCEc(-i) is MCEc with the i-th observation removed. The cut-off point is the maximum absolute difference between the value of the statistics for the full data set and the reduced data sets as obtained in Eq. 11:
| (11) |
If DMCEc(i) is greater than the cut-off point, the i-th observation is detected as an outlier.
Proposed robust circular distance for Y, RCDy: The distance between two circular observations is completely different from the distance between two linear observations as circular data are in angular form. The maximum distance between two circular observations cannot be more than π in a circle. For example, if ϑi =350° and ϑj = 10° the difference between them is equal to 340°, but this is not the true circular distance. It can be seen from the hypothetical Fig. 1 that ϑi =350° and ϑj = 10° are not far from each other. It is obvious that their distance is equal to 20°.
It is important to mention that the von Mises distribution is symmetric around the circular mean. Jammalamadaka and SenGupta14 defined circular distance (cd) in Eq. 12:
| (12) |
where, ϑi and ϑj are circular observation. It is anticipated that any observations in which their circular residuals lie far away from their circular mean can be considered as outliers. However, the circular mean is not robust against outliers. Hence, it is proposed using circular median in this regard. This issue has motivated us to formulate a new statistic to detect outliers in simple circular regression model, by employing circular median instead of circular mean. It is called this statistic robust circular distance, denoted as RCDy.
The following steps are applied to compute the proposed robust circular distance (RCDy): First, calculate the absolute value of the estimated circular residuals:
Note that it cannot calculate the difference between yi and ![]() directly as it is done with the linear method, because of the circular geometry theory. Second, compute the robust circular distance (RCD(i))y between
directly as it is done with the linear method, because of the circular geometry theory. Second, compute the robust circular distance (RCD(i))y between ![]() and circular median of:
and circular median of:
Then any yi is suspected to be an outlier if its corresponding [RCDi]y is relatively large. This is due to the fact that if y(i) is an outlier, it affects on the value of ![]()
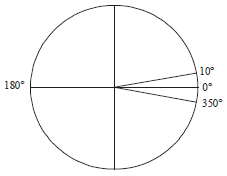 | |
| Fig. 1: | A hypothetical figure for the distance between two circular observations |
Subsequently, the circular distance between ![]() and circular median of
and circular median of ![]() is relatively large. Hence, the cut-off point should be the maximum value of the [RCD]y defined in Eq. 13:
is relatively large. Hence, the cut-off point should be the maximum value of the [RCD]y defined in Eq. 13:
| (13) |
Any circular data that [RCDi]y greater than the cut-off point is declare as an outlier.
RESULTS AND DISCUSSION
Simulated cut-off point of the RCDy statistic: A simulation study is designed to determine the cut-off points (percentage points) of the null hypothesis for the distribution of no outliers in circular data of the proposed statistic. The same procedure has been used by Pearson and Hartley15 and Collett16 to determine cut off points in their studies. For any data set of sample size n and concentration parameter k, it will be rejected the null hypothesis if the value of computed statistic is larger than the cut-off points, which suggested that there is an outlier in the data set. In this simulation study, first, it is considered 20 different sample sizes of n = 10, 20, 30, …, 200 and 9 values of concentration parameter k = 2, 3, 5, 6, 8, 10, 12, 15, 20. Second, generate a set of explanatory variables X of size n, such that:
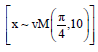 |
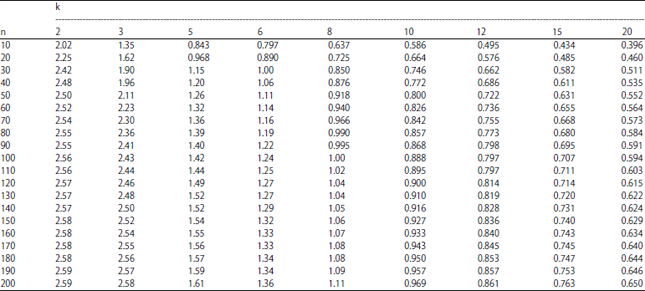
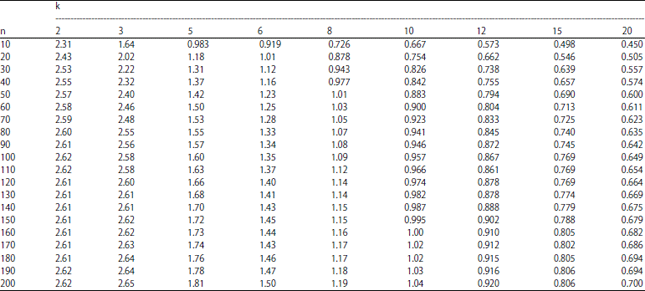
Third, generate a set of circular random errors, such that [e~νM(0, k)] for each sample size n and concentration parameter k. Next, fix the initial values of the parameters in the model at α = 0, β = 1. Then, calculate the values of the response variable Y and fit the generated circular data. The RCDy statistic is then computed and its maximum value is determined. These processes are replicated 5000 times for each combination of sample size n and concentration parameter k. The 10 and 5% upper percentile values of the maximum RCDy are determined as shown in Table 1 and 2, respectively. The priority is to calculating these values that they can be used as cut-off points of the RCDy statistic to identify outliers of the simple circular regression model according to the sample sizes and values of the concentration parameter.
It is noticeable from Table 1 and 2 that the cut-off point is an increasing function of the sample size n for any value of the concentration parameter k. This is reasonable, because when sample size is increased, the data will be more spread out. Consequently, the circular distance between them and the circular mean increases. Moreover, the cut-off point is a decreasing function of the concentration parameter k for any sample size n. This is because increasing the concentration parameter causes the concentration of the circular data around the circular mean to increase.
Performance of the RCDy statistic: The performance of the RCDy, COVRATIO, DMCEs and DMCEc statistics are examined by using Monte Carlo simulations.
| Table 1: | Cut-off points of RCDy with 10% upper percentile |
 | |
| Table 2: | Cut-off points of RCDy with 5% upper percentile |
 | |
Four different sample sizes are used, namely n =10, 50, 100 and 150 and six concentration parameters, k = 2, 3, 5, 6, 8 and 10. The data are contaminated in the response variable Y according to the following formula in Eq. 14:
| (14) |
where, λ is the degree of contamination, such that (0<λ<1). If λ = 0, there is no contamination. If λ = 1, the circular observation is located at the anti-mode of its initial location.
For all combinations of sample sizes and concentration parameters, it is generated 10 and 20% contaminated data with λ = 0.8. To evaluate the performance of all the statistics, three measures are considered namely, the proportion of outliers detected, the masking and the swamping rates. The processes are replicated 5000 times for each combination of sample size n and concentration parameter k. In each time of replication, it is observed that the number of detected true outliers (generated). Then the proportion of outliers are calculated as follows:
where, P is percentage of contamination. Similarly, to calculate the rate of masking and the rate of swamping, it is observed that the number of generated outliers detected as inlier (clean observation) and the number of inlier detected as outlier, respectively as follows:
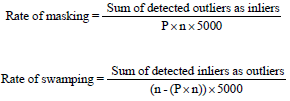 |
A good method is one that has the highest detection rate for the outliers and low masking and swamping rates. Figure 2 and 3 exhibit the proportion of outliers detected and the rate of masking and swamping with 5% upper percentile for n = 50 and 100. The results of Fig. 2 and 3 showed that the rates of swamping are zero or close to zero for all statistics. However, the rates of masking of COVRATIO statistic are very high and the proportions of outliers detected are very low, for all combinations of sample sizes, concentration parameters and percentage of outliers. It was noticed that the proportion of outliers detected of the MCEs statistic is low when the concentration parameter is less than 6 with 10% contamination and this proportion significantly decrease with 20 % contamination.
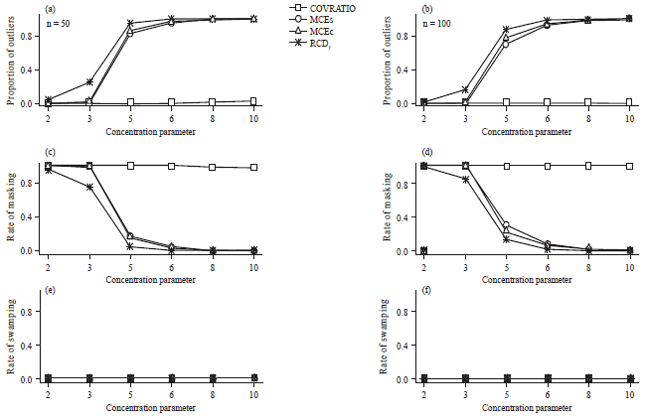 | |
| Fig. 2(a-f): | Proportion of outliers detected and rate of masking and swamping with 5% cut-off points and 10% contamination |
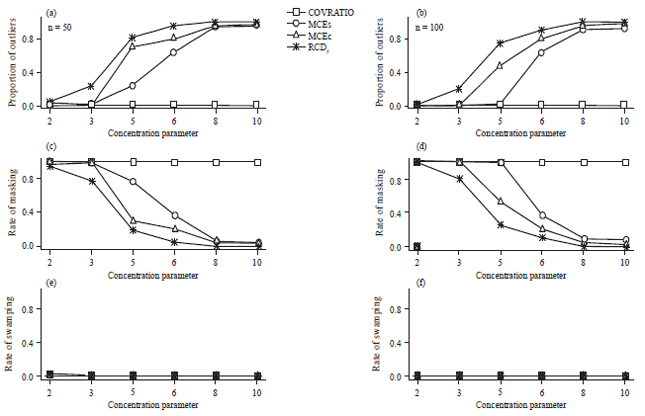 | |
| Fig. 3(a-f): | Proportion of outliers detected and rate of masking and swamping with 5% cut-off points and 20% contamination |
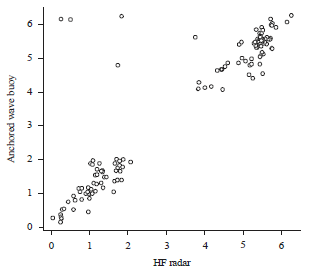 | |
| Fig. 4: | Scatter plot of the wind direction data |
Consequently, it has high rate of masking. The MCEc statistic relatively has a higher proportion of outliers detected than the MCEs statistic and the proportion increases with the concentration parameter but it is low at 20% contaminated. The proportion of outliers detected of the proposed RCDy statistic is relatively low for small value of k. This is acceptable because the circular data will be more spread around the circumference of the circle when the concentration parameter is low. Consequently, it is very difficult to identify outliers in this case16. As expected, the RCDy statistic gives a greater proportion of outliers detected than the other statistics. The proportion is an increasing function of the concentration parameter and increases to 100% for values of the concentration parameter greater than 5. Therefore, the rate of masking is very low and is a decreasing function of the concentration parameter, decreasing down to 0%.
In general, the proposed RCDy statistic is very successful in the detection of outliers because the circular median is one of the robust location parameter in a circular data. For these reasons, the RCDy statistic is the best when compared to the other three measures. It has the highest proportion of outliers detected and the lowest rates of both masking and swamping. Due to space constraints, the results for n = 10 and 50 are not shown. However, the results are consistent.
Practical example: The wind direction data that is studied by Abuzaid et al.7 is considered. The data represent measurements by using an HF radar system and an anchored wave buoy with sample size (n = 129). Figure 4 showed the scatter plot of the wind direction data, where X are the circular observations measured by the HF radar and Y are the circular observations measured by the anchored wave buoy. The estimated concentration parameter is ![]() . By referring to Table 2 with 5% upper percentile, the cut-off point is equal to 1.28. The RCDy statistic is calculated and the results are plotted in Fig. 5.
. By referring to Table 2 with 5% upper percentile, the cut-off point is equal to 1.28. The RCDy statistic is calculated and the results are plotted in Fig. 5.
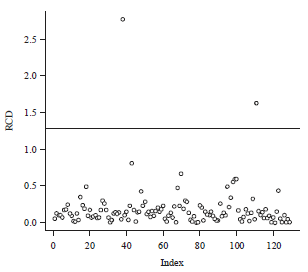 | |
| Fig. 5: | [RCDi]y statistic of the wind direction data |
It can be seen that the observations numbered 38 and 111 exceed the cut-off point. Therefore, they are considered as outliers. These results are in agreement with the results of Abuzaid et al.7. Abuzaid et al.7pointed out that the two points at the left top of the plot in Fig. 4 are not outliers. They are consistent with the rest of the observations at the right top or left bottom because of the closed range property of the circular variable.
CONCLUSION
A new statistic is proposed to detect outliers in Y in a simple circular regression model. Proportion of detection outliers and rate of masking and swamping are used to evaluate performance of the proposed method. The results showed that the proposed RCDy statistic is very successful in identifying genuine outliers for different sample sizes and with very low rates of masking and swamping.
REFERENCES
- Hussin, A.G., N.R.J. Fieller and E.C. Stillman, 2004. Linear regression model for circular variables with application to directional data. J. Applied Sci. Technol., 9: 1-6.
CrossRefDirect Link - Kato, S., K. Shimizu and G.S. Shieh, 2008. A circular-circular regression model. Statistica Sinica, 18: 633-645.
Direct Link - Hussin, A.G., A. Abu Zaid and I. Mohamed, 2009. Detection of outliers in the unreplicated linear circular functional relationship model via functional form. Proceedings of the International Conference on Nonparametric Methods for Measurement Error Models and Related Topics, May 3-5, 2009, Ottawa, Canada.
- Abuzaid, A., I. Mohamed, A.G. Hussin and A. Rambli, 2011. COVRATIO statistic for simple circular regression model. Chiang Mai J. Sci., 38: 321-330.
Direct Link - Abuzaid, A.H., A.G. Hussin and I.B. Mohamed, 2013. Detection of outliers in simple circular regression models using the mean circular error statistic. J. Stat. Comput. Simul., 83: 269-277.
CrossRefDirect Link - Abuzaid, A.H., 2013. On the influential points in the functional circular relationship models. Pak. J. Stat. Operat. Res., 9: 333-342.
CrossRefDirect Link - Hussin, A.G., A.H. Abuzaid, A.I.N. Ibrahim and A. Rambli, 2013. Detection of outliers in the complex linear regression model. Sains Malaysiana, 42: 869-874.
Direct Link - Collett, D., 1980. Outliers in circular data. J. Royal Stat. Soc. Ser. C (Applied Stat.), 1: 50-57.
CrossRefDirect Link