
S. K. Sarkar
Laboratory of Applied and Computational Statistics, Institute for Mathematical Research, Universiti Putra Malaysia, 43400 UPM Serdang, Selangor, Malaysia
Habshah Midi
Faculty of Science, Universiti Putra Malaysia, 43400 UPM Serdang, Selangor, Malaysia
Sohel Rana
Laboratory of Applied and Computational Statistics, Institute for Mathematical Research, Universiti Putra Malaysia, 43400 UPM Serdang, Selangor, Malaysia
Journal of Applied Sciences
Year: 2011 | Volume: 11 | Issue: 1 | Page No.: 26-35







ABSTRACT
Logistic regression is one of the most frequently used statistical methods as a standard method of data analysis in many fields over the last decade. However, analysis of residuals and identification of influential outliers are not studied so frequently to check the adequacy of the fitted logistic regression model. Detection of outliers and influential cases and corresponding treatment is very crucial task of any modeling exercise. A failure to detect influential cases can have severe distortion on the validity of the inferences drawn from such modeling. The aim of this study is to evaluate different measures of standardized residuals and diagnostic statistics by graphical methods to identify potential outliers. Evaluation of diagnostic statistics and their graphical display detected 25 cases as outliers but they did not play notable effect on parameter estimates and summary measures of fits. It is recommended to use residual analysis and note outlying cases that can frequently lead to valuable insights for strengthening the model.
PDF Abstract XML References Citation
Received: July 30, 2010;
Accepted: October 04, 2010;
Published: November 10, 2010
How to cite this article
S. K. Sarkar, Habshah Midi and Sohel Rana, 2011. Detection of Outliers and Influential Observations in Binary Logistic Regression: An Empirical Study. Journal of Applied Sciences, 11: 26-35.
DOI: 10.3923/jas.2011.26.35
URL: https://scialert.net/abstract/?doi=jas.2011.26.35
DOI: 10.3923/jas.2011.26.35
URL: https://scialert.net/abstract/?doi=jas.2011.26.35
INTRODUCTION
Often the outcome variable in the social data is in general not a continuous value instead a binary one. In such a case, binary logistic regression is a useful way of describing the relationship between one or more independent variables and a binary outcome variable, expressed as a probability scale that has only two possible values. Indeed, a generalized linear model is used for binary logistic regression. The most attractive feature of a logistic regression model is neither assumes the linearity in the relationship between the covariates and the outcome variable, nor does it require normally distributed variables. It also does not assume homoscedasticity and in general has less stringent requirements than linear regression models. Thus logistic regression is used in a wide range of applications leading to binary dependent data analysis (Hilbe, 2009; Agresti, 2002).
The vast majority of the work related to the logistic regression appears in the experimental epidemiological research but during the last decade it is evident that the technique is frequently used in observational studies. But analysis of residuals and the identification of outliers and influential cases are not studied so frequently to check the adequacy of the fitted model. Data obtained from observational studies sometimes can be considered as bad from the point of view of outlying responses. The traditional method of fitting logistic regression models with maximum likelihood, has good optimality properties in ideals settings, but is extremely sensitive to bad data obtained from observational studies (Pregibon, 1981). Frequently in logistic regression analysis applications, the real data set contains some cases that are outlier; that is the observations for these cases are well separated from the remainder of the data. These outlying cases may involve large residuals and often have dramatic effects on the fitted maximum likelihood linear predictor. It is therefore, important to study the outlying cases carefully and decide whether they should be retained or eliminated and if retained, whether their influence should be reduced in the fitting process and/ or the logistic regression model should be revised (Menard, 2002; Hosmer and Lemeshow, 2000).
For logistic regression with one or two predictor variables, it is relatively simple to identify outlying cases with respect to their X or Y values by means of scatter plots of residuals and to study whether they are influential in affecting the fitted linear predictor. When more than two predictor variables are included in the logistic regression model, however, the identification of outlying cases by simple graphical methods becomes difficult. In such a case, traditional standardized residual plots can highlight little regarding outliers and some derived statistics and their plots from basic building blocks with lowess smooth and bubble plots are potential to detect outliers and influential cases (Kutner et al., 2005; Hosmer and Lemeshow, 2000).
There are three ways that an observation can be considered as unusual, namely outlier, influence and leverage. In logistic regression, a set of observations whose values deviate from the expected range and produce extremely large residuals and may indicate a sample peculiarity is called outliers. These outliers can unduly influence the results of the analysis and lead to incorrect inferences. An observation is said to be influential if removing the observation substantially changes the estimate of coefficients. Influence can be thought of as the product of leverage and outliers. An observation with an extreme value on a predictor variable is called a point with high leverage. Leverage is a measure of how far an independent variable deviates from its mean. In fact, the leverage indicates the geometric extremeness of an observation in the multi-dimensional covariate space. These leverage points can have an unusually large effect on the estimate of logistic regression coefficients (Cook, 1998).
Christensen (1997) suggested that if the residuals in binary logistic regression have been standardized in some fashion, then one would expect most of them to have values within ±2. Standardized residuals outside of this range are potential outliers. Thus studentized residuals less than -2 and greater than +2 definitely deserve closer inspection. In that situation, the lack of fit can be attributed to outliers and the large residuals will be easy to find in the plot. But analysts may attempt to find group of points that are not well fit by the model rather than concentrating on individual points. Techniques for judging the influence of a point on a particular aspect of the fit such as those developed by Pregibon (1981) seem more justified than outlier detection (Jennings, 1986).
Detection of outliers and influential cases and corresponding treatment is very crucial task of any modeling exercise. A failure to detect outliers and hence influential cases can have severe distortion on the validity of the inferences drawn from such modeling exercise. It would be reasonable to use diagnostics to check if the model can be improved in case of Correct Classification Rate (CCR) is smaller than 100. The main focus in this study is to detect outliers and influential cases that have a substantial impact on the fitted logistic regression model through appropriate graphical method including smoothing technique.
MATERIALS AND METHODS
The Bangladesh Demographic and Health Survey is part of the worldwide Demographic and Health Surveys program, which is designed to collect data on fertility, family planning, maternal and child health. The BDHS is a source of population and health data for policymakers and the research community. BDHS-2004 is the fourth survey conducted in Bangladesh and preparations for the survey started in mid-2003 and field work was carried out between January and May 2004. We have been using the women’s data file. A total of 11,440 eligible women were furnished their responses. But in this analysis there are only 2,212 eligible women those are able to bear and desire more children are considered. The women under sterilization, declared in fecund, divorced, widowed, having more than and less than two living children are not involved in the analysis. Those women who have two living children and able to bear and desire more children are only considered here during the period of global two children campaign.
The variable age of the respondent, fertility preference, place of residence, highest year of education, working status and expected number of children are considered in the analysis. The variable fertility preference involving responses corresponding to the question, would you like to have (a/another) child? The responses are coded 0 for no more and 1 for have another is considered as desire for children which is the binary response variable (Y) in the analysis. The age of the respondent (X1), place of residence (X2) is coded 0 for urban and 1 for rural, highest year of education (X3), working status of respondent (X4) is coded 0 for not working and 1 for working and expected number of children (X5) is coded 0 for two and 1 for more than two are considered as covariates in the logistic regression model. Several standardized residual plots, lowess smooth and diagnostic plots are used to detect influential outliers.
FORMULATION OF THE BINARY RESPONSE MODEL
The binary logistic regression model computes the probability of the selected response as a function of the values of the explanatory variables. A major problem with the linear probability model is that probabilities are bounded by 0 and 1, but linear functions are inherently unbounded. The solution is to transform the probability so that it is no longer bounded. Transforming the probability to odds removes the upper bound and natural logarithm of odds also removes the lower bound. Thus, setting the result equal to a linear function of the explanatory variables yields logit or binary response model (Allison, 1999).
Suppose in a multiple logistic regression case, a collection of k explanatory variables be denoted by the vector X' = (X1, X2,... Xk). Let the conditional probability that the outcome is present be denoted by P (Y = 1|X) = θ(X). It is evident that Sigmoidal-shape curve configuration has been found to be appropriate in many applications for which the outcome variable is binary and the corresponding model having more than one explanatory variable can be written as:
| (1) |
Where:
| (2) |
with Zi = β0+β1X1i+β2X2i +...+ βkXki = Xβ. Here Y is nx1 vector of response having yi=0 if the ith case does not possess the characteristic and yi = 1 if the case does possess the characteristic under study, X is an n x (k+1) design matrix of explanatory variables, β is a (k+1) x1 vector of parameters, ε is also an nx1 vector of unobserved random errors. The quantity θi is the probability for the ith covariate satisfying the important requirement 0≤θi≤1. Then the log-odds of having Y = 1 for given X is modeled as a linear function of the explanatory variables as:
| (3) |
The function:
is known as logistic function. The most commonly used method of estimating the parameters of a logistic regression model is the method of Maximum Likelihood (ML) instead of Ordinary Least Square (OLS) method. Mainly for this reason the ML method based on Newton-Raphson iteratively reweighted least square algorithm becomes more popular with the researchers (Ryan, 1997). The sample likelihood function is, in general defined as the joint probability function of the random variables whose realizations constitute the sample. Specifically, for a sample of size n whose observations are (y1, y2, … yn), the corresponding random variables are (Y1, Y2, ……n). Since the Yi is a Bernoulli random variable, the probability mass function of Yi is
| (4) |
Since Y’s are assumed to be independent, the log-likelihood function L (β) is defined as:
| (5) |
For convenience in multiple logistic regression models, the likelihood equations can be written in matrix notation as:
| (6) |
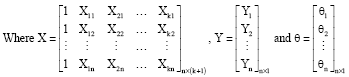 |
Now, theoretically putting:
produces ![]() , satisfying
, satisfying ![]() . In fact, the maximum likelihood estimates of β in the multiple binary logistic regression models are those values of β that maximize the log-likelihood function given in Eq. 5. No closed form solution exists for the values of
. In fact, the maximum likelihood estimates of β in the multiple binary logistic regression models are those values of β that maximize the log-likelihood function given in Eq. 5. No closed form solution exists for the values of ![]() that maximize the log-likelihood function. Computer-intensive numerical search procedures are therefore required to find the maximum likelihood estimates
that maximize the log-likelihood function. Computer-intensive numerical search procedures are therefore required to find the maximum likelihood estimates ![]() and hence
and hence ![]() , because the multiple logistic regression model computes the probability of the selected response as a function of the values of the predictor variables. There are several widely used numerical search procedures, one of these employs iteratively reweighted least squares algorithm. In this study, we shall rely on standard statistical software programs specifically designed for logistic regression to obtain the maximum likelihood estimates of parameters.
, because the multiple logistic regression model computes the probability of the selected response as a function of the values of the predictor variables. There are several widely used numerical search procedures, one of these employs iteratively reweighted least squares algorithm. In this study, we shall rely on standard statistical software programs specifically designed for logistic regression to obtain the maximum likelihood estimates of parameters.
GOODNESS-OF-FIT OF THE MODEL
In order to check the goodness-of-fit of an estimated multiple logistic regression model one should assume that the model contains those variables that should be in the model and have been entered in the correct functional form. The goodness-of-fit measures how effectively the model describes the response variable. The distribution of the goodness-of-fit statistics is obtained by letting the sample size n become large. If the number of covariate patterns increases with n then size of each covariate pattern tends to be small. Generally, the term covariate pattern is used to describe a single set of values for the covariates in the model. Distributional results obtained under the condition that only n become large are said to be based on n-asymptotic. The case most frequently encountered in practice that the model contains one or more continuous covariates. In such a situation the number of covariate patterns is approximately equal to the sample size and the current study contains two continuous covariates and the number of covariate patterns may not be an issue when the fit of the model is assessed. To assess the goodness-of-fit of the model, researcher should have some specific idea about what it means to say that a model fits. Suppose we denote the observed sample values of the response variable in vector form as Y where, Y' = (y1, y2,... yn) and the corresponding predicted or fitted values by the model as ![]() . We may conclude that the model fits if summary measures of the distance between Y and
. We may conclude that the model fits if summary measures of the distance between Y and ![]() are small and the contribution of each pair
are small and the contribution of each pair ![]() , i = 1, 2, …, n to the summary measures is unsystematic and is small relative to the error structure of the model. Thus, a complete assessment of the fitted model involves both the calculation of summary measures of the distance between Y and
, i = 1, 2, …, n to the summary measures is unsystematic and is small relative to the error structure of the model. Thus, a complete assessment of the fitted model involves both the calculation of summary measures of the distance between Y and ![]() and a thorough examination of the individual components of these measures. When model building stage has been completed, a series of logical steps should be used to assess the fit of the model. The components of proposed approach are: (1) computation and evaluation of overall summary measures of fit, (2) examination of the individual components of the summary statistics with appropriate graphics and (3) examination of other measures of the distance between the components of Y and
and a thorough examination of the individual components of these measures. When model building stage has been completed, a series of logical steps should be used to assess the fit of the model. The components of proposed approach are: (1) computation and evaluation of overall summary measures of fit, (2) examination of the individual components of the summary statistics with appropriate graphics and (3) examination of other measures of the distance between the components of Y and ![]() (Hosmer and Lemeshow, 2000). The summary measures of goodness-of-fit, as they are routinely provided as program output with any fitted model and give an overall indication of the fit of the model. The different summary measures like likelihood ratio test, (Hosmer and Lemeshow, 1980) goodness-of-fit test, (Osius and Rojek, 1992) normal approximation test, (Stukel, 1988) test and other supplementary statistics indicate that the model seems to fit quite well. It is also evident that the individual predictors in the fitted model have significant contribution to predict the response variable through likelihood ratio test as well as Wald test (Sarkar and Midi, 2010). The elaboration of these measures is beyond the scope of the study. Before concluding that the model fits, it is crucial that other measures be examined to see if fit is supported over the entire set of covariate patterns. This is accomplished through a series of specialized measures falling under the general heading of residual analysis and regression diagnostics (Cook and Weisberg, 1982).
(Hosmer and Lemeshow, 2000). The summary measures of goodness-of-fit, as they are routinely provided as program output with any fitted model and give an overall indication of the fit of the model. The different summary measures like likelihood ratio test, (Hosmer and Lemeshow, 1980) goodness-of-fit test, (Osius and Rojek, 1992) normal approximation test, (Stukel, 1988) test and other supplementary statistics indicate that the model seems to fit quite well. It is also evident that the individual predictors in the fitted model have significant contribution to predict the response variable through likelihood ratio test as well as Wald test (Sarkar and Midi, 2010). The elaboration of these measures is beyond the scope of the study. Before concluding that the model fits, it is crucial that other measures be examined to see if fit is supported over the entire set of covariate patterns. This is accomplished through a series of specialized measures falling under the general heading of residual analysis and regression diagnostics (Cook and Weisberg, 1982).
RESIDUAL ANALYSIS AND RESIDUAL PLOTS
Residual analysis for logistic regression is more difficult than the linear regression models because the responses take on only the values 0 and 1. Thus the ith ordinary residual will assume one of the two values as:
| (7) |
The ordinary residuals will not be normally distributed and, indeed their distribution under the assumption that the fitted model is correct is unknown. Plots of ordinary residuals against fitted values will generally be uninformative. In linear regression a key assumption is that the error variance does not depend on the conditional mean E (Y|X). However, in logistic regression, there are binomial errors and, as a result, the error variance is a function of the conditional mean as V (Y|X) = θ (1-θ). Hence, the ordinary residual can be made more comparable by dividing them by the estimated standard error of Yi which is known as Pearson residual denoted by pri and defined as:
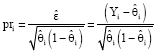 | (8) |
The Pearson residuals are directly related to the Pearson chi-square goodness-of-fit statistic. The square of Pearson residual measures the contribution of each binary response to the Pearson chi-square test statistic but the test statistic does not follow an approximate chi-square distribution for binary data without replicates. The Pearson residuals do not have unit variance since no allowance has been made for the inherent variation in the fitted value ![]() . A better procedure is to further standardize the ordinary residuals by their estimated standard deviation that is called studentized Pearson residuals. The standard deviation is approximated by:
. A better procedure is to further standardize the ordinary residuals by their estimated standard deviation that is called studentized Pearson residuals. The standard deviation is approximated by:
where:
hii is the ith diagonal element of the nxn estimated hat matrix H, whereby in logistic regression it is called hat diagonal or Pregibon leverage and measures the leverage of an observation. More clearly leverage is a measure of the importance of an observation to the fit of the model. Here, ![]() is the nxn diagonal matrix with elements
is the nxn diagonal matrix with elements ![]() , X is the nx (k+1) design matrix defined earlier. The hat matrix for logistic regression satisfies approximately the expression
, X is the nx (k+1) design matrix defined earlier. The hat matrix for logistic regression satisfies approximately the expression ![]() where,
where, ![]() is the nx1 vector of linear predictors. Then studentized Pearson residuals spri are defined as:
is the nx1 vector of linear predictors. Then studentized Pearson residuals spri are defined as:
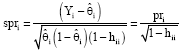 | (9) |
Studentized Pearson residuals are primarily helpful in identifying influential observations and those build in information about the influence of a case, whereas Pearson residuals do not. More influential cases with high leverages result in high studentized Pearson residuals. Studentized Pearson residuals approximately follow the standard normal distribution for large (n≥30) sample and it can be used as an approximate chi-square distribution.
Deviance residual is another type of residual. It measures the disagreement between any component of the log likelihood of the fitted model and the corresponding component of the log likelihood that would result if each point were fitted exactly. Since, the logistic regression uses the maximum likelihood principle, the goal in logistic regression is to minimize the sum of the deviance residuals. Deviance residuals can also be useful for identifying potential outliers or misspecified cases in the model. The deviance residual for the ith case is defined as the signed square root of the contribution of that case to the sum for the model deviance as:
| (10) |
McCullagh and Nelder (1989) expressed a preference for the deviance residuals because they are closer to being normally distributed than are the Pearson residuals. Approximate normality is certainly a desirable property of residuals, but it is also desirable to use some type of residual that will detect influential cases for necessary modifications to a logistic regression model so as to improve CCR. Like Pearson residual the square of each deviance residual measures the contribution of each binary response to the deviance good ness-of-fit statistic. Studentized Pearson residuals, deviance residuals and Pregibon leverage are considered to be the three basic building blocks for logistic regression diagnostics in detection of influential outliers and shown in Table 1.
| Table 1: | Binary logistic regression residuals and hat matrix diagonal elements for BDHS-2004 |
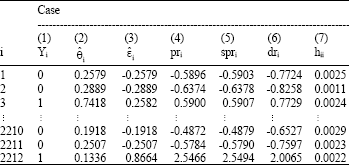 | |
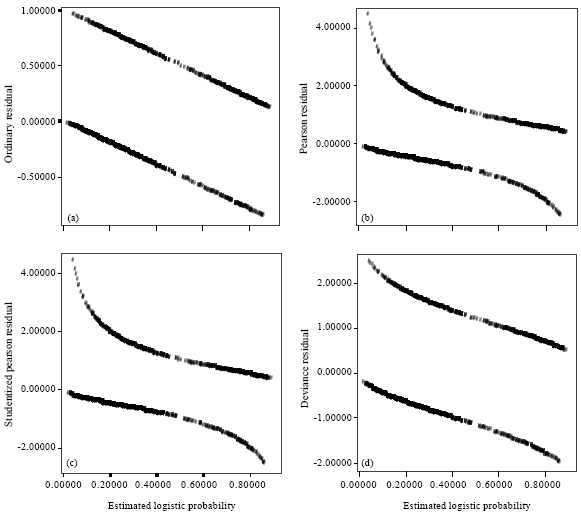
A good way of looking at the impact of various residuals is to graph them against either the predicted probabilities or simply case numbers. Since the sample size of the current study is large enough, the various residuals are plotted against the predicted mean response or estimated logistic probability instead of case numbers in Fig. 1. Different residual plots exhibited in Fig. 1a-d indicate two trends of decreasing residuals with slope-1. These two linear trends result from the fact that the residuals take on just one of two values at a point Xi, ![]() or
or ![]() . Plotting these values against estimated logistic probability will always produce two linear trends with slope -1. The remaining plots lead to similar patterns. It is visualized from Fig. 1c and d, a few residuals appear with magnitude less than -2 and greater than +2 and beyond of this range definitely deserve closer inspection because standardized residuals outside of this range are potential outliers. If the logistic regression model were in fact true, one would expect to observe a horizontal band with most of the residuals falling within ±2 (Christensen, 1997). Under the existing 2-σ rule, the standardized residuals outside of ±2 may be considered as potential outliers and those are clearly visualized in Fig. 1c and d.
. Plotting these values against estimated logistic probability will always produce two linear trends with slope -1. The remaining plots lead to similar patterns. It is visualized from Fig. 1c and d, a few residuals appear with magnitude less than -2 and greater than +2 and beyond of this range definitely deserve closer inspection because standardized residuals outside of this range are potential outliers. If the logistic regression model were in fact true, one would expect to observe a horizontal band with most of the residuals falling within ±2 (Christensen, 1997). Under the existing 2-σ rule, the standardized residuals outside of ±2 may be considered as potential outliers and those are clearly visualized in Fig. 1c and d.
It is well known phenomena that in ordinary linear regression, residual plots are useful for diagnosing model inadequacy, non constant variance and the presence of potential outliers in response as well as in covariate space. Non constant variance is always present in the logistic regression setting and response outliers are difficult to diagnose. So, the current study focused on the detection of model inadequacy and potential outliers in the covariate space only. If the logistic regression model is correct, then E (Yi) = θi and it follows asymptotically that ![]() .
.
This suggests that if the model is correct and no significant incorporation of potential outliers, a lowess smooth of the plot of the residuals against the estimated logistic probability or linear predictor should result approximately in a horizontal line with zero intercept. Any significant departure from this suggests that the model may be inadequate and potential outliers may have dramatic impact on the fit of the model.
 | |
| Fig. 1: | Selected Residuals plotted against Estimated Logistic Probability for BDHS-2004 Data |
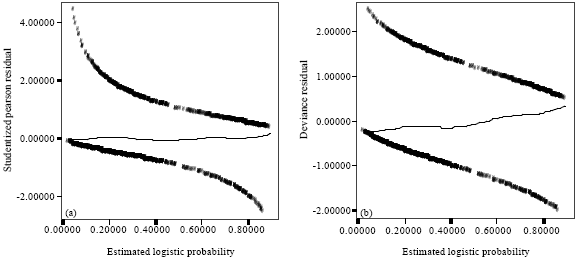 | |
| Fig. 2: | Standardized Residual Plots with lowess Smooth for BDHS-2004 Data |
The lowess smooth of the studentized Pearson residuals and deviance residuals are demonstrated in Fig. 2. In Fig. 2a and b, the studentized Pearson residuals and deviance residuals are plotted against the estimated logistic probability respectively and in both case, the lowess smooth approximates a line having zero slope and intercept. Hence, it can be concluded that no significant model inadequacy and presence of influential outliers are observed in the covariate space. Thus the existing outliers detected by the residual plots are not so influential.
DIAGNOSTIC STATISTICS AND DIAGNOSTIC PLOTS
In case of more than two covariates in the logistic regression setting, the standardized residual plots can highlight little regarding influential outliers. In such a situation, some derived diagnostic statistics like change in Pearson chi-square, change in deviance, change in parameter estimates from basic building blocks and their plots including proportional influence or bubble plots are potential to detect outliers and influential cases. Several measures of influence for logistic regression have been suggested. These measures have been developed for the purpose of identifying observations, which are influential relative to the estimation of the logistic regression coefficients (Midi et al., 2009). Such a useful diagnostic statistic is one that examines the effect of deleting single subject on the value of the estimated coefficients (β) and the overall summary measures of fit, like Pearson chi-square (χ2) statistic and deviance (D) statistic. Let, χ2 denotes the Pearson chi-square statistic based on full data set and χ2(-i) denotes that statistic when case i is deleted. Using one-step linear approximations given by Pregibon (1981), it can be shown that the decrease in the value of the Pearson chi-square statistic due to deletion of the ith subject is:
| (11) |
The one-step linear approximation for change in deviance when the ith case is deleted is as:
| (12) |
The change in the value of the estimated coefficients is analogous to the measure proposed by Cook (1977) for linear regression. It is obtained as the standardized difference between ![]() and
and ![]() , where these represent the maximum likelihood estimates based on full data set and excluding the ith case respectively and standardizing via the estimated covariance matrix of
, where these represent the maximum likelihood estimates based on full data set and excluding the ith case respectively and standardizing via the estimated covariance matrix of ![]() . Thus, one step linear approximation is given as:
. Thus, one step linear approximation is given as:
| (13) |
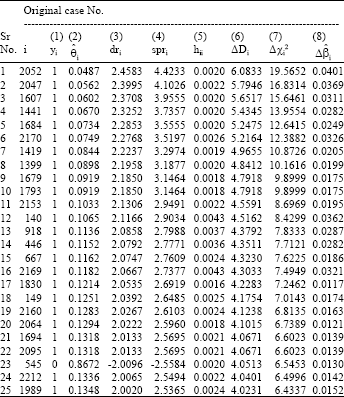
| Table 2: | Pearson residuals, studentized residuals, hat diagonals, deviance residuals, delta chi-aquare, delta deviance and delta beta statistics for the BDHS-2004 data |
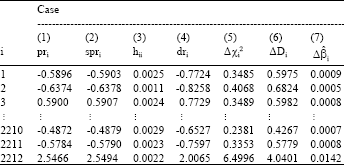 | |
The derived influence statistics are listed in Table 2. These diagnostic statistics are conceptually quite appealing, as they allow us to identify those cases that are poorly fit (large values of Δχi2 and ΔDi) and those that have a great deal of influence on the values of the estimated parameters (large values of ![]() ).
).
A number of different types of diagnostic plots have been suggested to detect outliers and influential cases. It is impractical to consider all possible suggested plots, so we restrict our attention to a few of the more easily obtained ones that are meaningful in logistic regression analysis. These consist of plotting Δχi2, ΔDi and ![]() against the estimated logistic probability and plotting ΔDi versus estimated logistic probability where the size of the plotting symbol is proportional to the size of
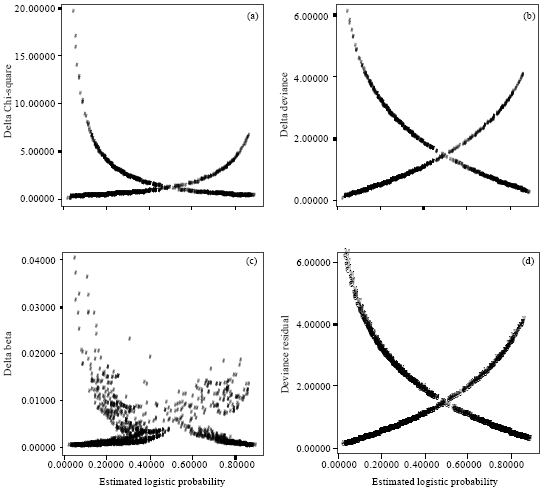
against the estimated logistic probability and plotting ΔDi versus estimated logistic probability where the size of the plotting symbol is proportional to the size of ![]() , where it is usually called proportional influence plot or bubble plot. The derived diagnostic statistics Δχ2 and ΔD plotted against estimated logistic probability are shown in Fig. 3a and b, respectively.
, where it is usually called proportional influence plot or bubble plot. The derived diagnostic statistics Δχ2 and ΔD plotted against estimated logistic probability are shown in Fig. 3a and b, respectively.
The shapes of the plots are similar and show quadratic like curves. Cases that are poorly fit will generally be represented by points falling in the top left or top right corners of the plots. Assessment of this distance is partly based on numerical value and partly based on visual impression. Since, the current fitted model contains two continuous covariates, the number of covariate patterns is of the same order as sample size. Under n-asymptotic the value of upper ninety-fifth percentile of chi-square distribution with 1 degree of freedom is 3.84 and may provide some guidance as to whether an observation is an outlier or influential point. Thus the cases having numerical values larger than this cut-off point which is based on Δχ2 or ΔD can be considered as outlying observations. It can be observed from Table 3 that 25 observations are detected as outliers and these points fell at the top left corner of the plots displayed in Fig. 3. The range of Δχ2 is much larger than ΔD. This is a property of Pearson versus deviance residuals. Figure 3c shows the plot of the derived influence statistic ![]() against the estimated logistic probability.
against the estimated logistic probability.
 | |
| Fig. 3: | Delta Chi-square, delta deviance, delta beta and proportional influence plots |
| Table 3: | Outlying cases and their impact on influence statistics for BDHS-2004 data |
 | |
This plot is known as influence plot. We observe that few points lie somewhat away from the rest of the data. The values themselves are not large enough, as all are less than 0.040. The value of such influence statistic for an individual case must be larger than 1 to have an effect on the estimated coefficients. The largest values of ![]() are most likely to occur when both Δχ2 and leverage are at least moderately large. However large values can also occur when either component is large. This is the case in influence plot.
are most likely to occur when both Δχ2 and leverage are at least moderately large. However large values can also occur when either component is large. This is the case in influence plot.
The proportional influence plot or bubble plot is exhibited in Fig. 3d. The actual influence of each case on the estimated coefficient can be shown in this plot. This plot allows us to ascertain the contributions of residual and leverage to ![]() . The large circles in the top left corner correspond to the largest value of ΔD. No such large circles are visualized within 0.1≤
. The large circles in the top left corner correspond to the largest value of ΔD. No such large circles are visualized within 0.1≤ ![]() ≤0.9 which indicates insignificant contribution of leverage on the estimates, because within the said range of estimated probability leverage gives a value that may be thought of distance.
≤0.9 which indicates insignificant contribution of leverage on the estimates, because within the said range of estimated probability leverage gives a value that may be thought of distance.
DISCUSSION AND CONCLUSION
Logistic regression is a special case of generalized linear modeling, where the usual approach to outlier detection is based on large sample normal approximations for the deviance and studentized Pearson residuals. It is important to note that deviance residuals are valuable tool for identifying cases that are outlying with respect to covariate space. Global tests of model adequacy use the corresponding chi-squared approximations for the deviance and Pearson Statistics. Although normal approximations to the deviance and studentized Pearson residuals are often reasonable they are questionable for logistic regression with sparse data and with small sample (Hosmer and Lemeshow, 2000). Under the normality assumption with sufficiently large sample, deviance residuals or studentized Pearson residuals follow the chi-square distribution with single degree of freedom. Thus, the upper ninety-fifth percentile value of chi-square distribution which is approximately 4 may be considered as crude cut-off point to detect outlying cases. Crude in the sense, that the distribution of the delta statistics is unknown except under certain restrictive assumptions. Examination of Fig. 3 and numerical values of column 6 and (7) presented in Table 3 identifies 25 ill-fitted cases with outlying values on the basis of diagnostics statistics ΔD and Δχ2. These cases contribute heavily to the disagreement between the data and the predicted values of the fitted model on the basis of observed response yi and estimated logistic probability ![]() shown at column 1 and 2 in Table 3. Detected outlying cases are one type of observations that has a large value of ΔD and Δχ2 correspond to the misclassified observations. The fitted model predicts that it is unlikely for the subjects to respond when in fact they do (
shown at column 1 and 2 in Table 3. Detected outlying cases are one type of observations that has a large value of ΔD and Δχ2 correspond to the misclassified observations. The fitted model predicts that it is unlikely for the subjects to respond when in fact they do (![]() is small and yi = 1), while the opposite type of poor fit (
is small and yi = 1), while the opposite type of poor fit (![]() is large and yi = 0) also present in the model.
is large and yi = 0) also present in the model.
On the other hand, high leverage values are bad. The leverage value varies from 0 to 1. A leverage value of 1 means, the model is being forced or levered to fit the corresponding case exactly. Thus the leverage can be used to detect influential outliers. The leverage of any given case may be compared to the average leverage which equals (k+1)/n, where k is the number of covariates in the model and n is the sample size. The average leverage is inversely proportional to the size of the sample. If the sample is sufficiently large, the leverage value hii tends to be smaller. Cases are declared influential having hii>2(k+1)/n (Belsley et al., 1980; Bagheri et al., 2010). Two times of the average leverage of current study is approximately 0.0054. The leverage hii values listed at column 5 in Table 3 corresponding to the outlying cases is smaller than that cut-off point. Thus, it may be concluded that the outlying cases are not so influential due to sufficiently large sample.
The effect on the set of parameter estimates when any specific observation is excluded can be computed with the derived statistic based on the distance known as Cook’s distance proposed by Cook (1977) in linear regression. The analogous to the measure of one step linear approximation proposed by Pregibon (1981) is ![]() in logistic regression. Since an observation is called influential if it has notable effect on parameter estimates, Cook (1977) proposed that the influence diagnostic must be larger than 1 for an individual case to have an effect on the estimated coefficients. Influence diagnostic
in logistic regression. Since an observation is called influential if it has notable effect on parameter estimates, Cook (1977) proposed that the influence diagnostic must be larger than 1 for an individual case to have an effect on the estimated coefficients. Influence diagnostic ![]() corresponding to the outlying cases is tabulated in column (8) of Table 3. The values themselves are not especially large with respect to 1 and suggest that none of the outlying cases are influential in the fitting process. One problem with the influence diagnostic
corresponding to the outlying cases is tabulated in column (8) of Table 3. The values themselves are not especially large with respect to 1 and suggest that none of the outlying cases are influential in the fitting process. One problem with the influence diagnostic ![]() is that it is a summary measure of change over all coefficients in the model simultaneously. For this reason it is important to examine the changes in the individual coefficients due to specific cases identified as influential. In this regard, change in individual coefficients can be obtained under the option DfBeta and observed that all the changes are very small relative to 1 (Sarkar et al., 2010).
is that it is a summary measure of change over all coefficients in the model simultaneously. For this reason it is important to examine the changes in the individual coefficients due to specific cases identified as influential. In this regard, change in individual coefficients can be obtained under the option DfBeta and observed that all the changes are very small relative to 1 (Sarkar et al., 2010).
Generally, deleting cases with the largest residuals or more extreme values almost always improves the fit of the model. Since the outlying cases are not influential, it is justified that there were no substantial changes in the model fit or estimated parameters when we delete each cases. The collective effect is also not substantial. So, we decided the outlying cases should be retained in the analysis.
In summary, scientists frequently have primary interest in the outlying cases because they deviate from the currently accepted model. Examination of these outlying cases may provide important clues as to how the model needs to be modified. Outlying cases may also lead to the finding of other types of model inadequacies such as the omission of an important variable or the choice of an incorrect functional form. The analysis of outlying cases can frequently lead to valuable insights for strengthening the model such that the outlying case is no longer an outlier but is accounted for by the model. Finally, it may be concluded that incase of small sample the influential outliers can be detected easily by the leverage value but as sample size increases, the detected outliers do not play any significant influence on the parameter estimates.
REFERENCES
- Allison, P.D., 1999. Comparing logit and probit coefficients across groups. Socio. Meth. Res., 28: 186-208.
CrossRefDirect Link - Bagheri, A., H. Midi and A.H.M.R. Imon, 2010. The effect of collinearity-influential observations on collinear data set: A monte carlo simulation study. J. Applied Sci., 10: 2086-2093.
CrossRefDirect Link - Cook, R.D., 1977. Detection of influential observations in linear regression. Technometrics, 19: 15-18.
Direct Link - Hosmer, D.W. and S. Lemeshow, 1980. A goodness-of-fit test for the multiple logistic regression model. Commun. Statistics, 9: 1043-1069.
CrossRefDirect Link - Jennings, D.E., 1986. Outliers and residual distribution in logistic regression. J. Am. Stat. Assoc., 81: 987-990.
Direct Link - Midi, H., S. Rana and A.H.M.R. Imon, 2009. Estimation of parameters in heteroscedastic multiple regression model using leverage based near-neighbors. J. Applied Sci., 9: 4013-4019.
CrossRefDirect Link - Osius, G. and D. Rojek, 1992. Normal goodness-of-fit tests for multinomial models with large degrees-of-freedom. J. Am. Statistical Assoc., 87: 1145-1152.
Direct Link - Sarkar, S.K. and H. Midi, 2010. Importance of assessing the model adequacy of binary logistic regression. J. Applied Sci., 10: 479-486.
CrossRefDirect Link