
Siti Roslindar Yaziz
Faculty of Industrial Sciences and Technology, Universiti Malaysia Pahang, Lebuhraya Tun Razak, 26300 Kuantan, Pahang, Malaysia
Maizah Hura Ahmad
Faculty of Science, Universiti Teknologi Malaysia, 81300 Skudai, Johor, Malaysia
Lee Chee Nian
Faculty of Science, Universiti Teknologi Malaysia, 81300 Skudai, Johor, Malaysia
Noryanti Muhammad
Faculty of Industrial Sciences and Technology, Universiti Malaysia Pahang, Lebuhraya Tun Razak, 26300 Kuantan, Pahang, Malaysia
Journal of Applied Sciences
Year: 2011 | Volume: 11 | Issue: 7 | Page No.: 1129-1135







ABSTRACT
Crude oil is an important energy commodity to mankind. The fluctuation of crude oil prices has affected many related sectors and stock market indices. Hence, forecasting the crude oil prices is essential to avoid the future prices of the non-renewable natural resources to raise sky-rocket. In this study, daily West Texas Intermediate (WTI) crude oil prices data is obtained from Energy Information Administration (EIA) from 2nd January 1986 to 30th September 2009. This study uses the Box-Jenkins methodology and Generalized Autoregressive Conditional Heteroscedasticity (GARCH) approach in analyzing the crude oil prices. ARIMA(1,2,1) and GARCH(1,1) are found to be the appropriate models under model identification, parameter estimation, diagnostic checking and forecasting future prices. In this study, the analyses are done with the aid of EViews software where the potential of this software in forecasting daily crude oil prices time series data is explored. Finally, using several measures, comparison performances between ARIMA(1, 2, 1) and GARCH(1,1) models are made. GARCH(1,1) is found to be a better model than ARIMA(1, 2, 1) model. Based on the study, it is concluded that ARIMA(1,2,1) model is able to produce good forecast based on a description of history patterns in crude oil prices. However, the GARCH(1,1) is the better model for daily crude oil prices due to its ability to capture the volatility by the non-constant of conditional variance.
PDF Abstract XML References Citation
Received: October 18, 2010;
Accepted: December 20, 2010;
Published: March 09, 2011
How to cite this article
Siti Roslindar Yaziz, Maizah Hura Ahmad, Lee Chee Nian and Noryanti Muhammad, 2011. A Comparative Study on Box-Jenkins and Garch Models in Forecasting Crude Oil Prices. Journal of Applied Sciences, 11: 1129-1135.
DOI: 10.3923/jas.2011.1129.1135
URL: https://scialert.net/abstract/?doi=jas.2011.1129.1135
DOI: 10.3923/jas.2011.1129.1135
URL: https://scialert.net/abstract/?doi=jas.2011.1129.1135
INTRODUCTION
Time series analysis and forecasting has been an area of considerable research in various fields for recent years. In agriculture, time series forecasting using artificial neural network is reasonable well used for rice yields time (Shabri et al., 2009). It is also has been used in agriculture economic such as poultry retail price (Fahimifard et al., 2009) and Cocoa Bean Price (Assis et al., 2010). In business and economics, time series forecasting is practical well used in exchange rate forecasting (Fahimifard et al., 2009).
This study is focus on forecasting of crude oil price using time series modeling. There are ample studies addressing the accuracy of crude oil volatility modeling and time series forecasting. These include Autoregressive Conditional Heteroscedasticity, ARCH-type models (Fong and See, 2002; Giot and Laurent, 2003), Asymmetric Threshold Autoregressive (TAR) model (Godby et al., 2000) and artificial based forecast methods (Fan et al., 2008), Interval Least Square (ILS) (Xu et al., 2008) Support Vector Machine (SVM) (Xie et al., 2006) Artificial Neural Networks (ANN) (Kulkarni and Haidar, 2009) Adaptive Network-based Fuzzy Inference System (ANFIS) (Ghaffari and Zare, 2009) Fuzzy Neural Network (Liu et al., 2007), Autoregressive Moving Average (ARMA) (Cabedo and Moya, 2003) and etc. However, the complexity of the model specification does not guarantee high performance on out-performed out-of-sample forecasts.
A discussion on the Autoregressive Conditional Heteroscedasticity (ARCH) model developed by Engle (1982) will also be presented. Engle was the first to introduce the concept of conditional heteroscedasticity (Engle, 1982). The Box-Jenkins methodology and Generalized Autoregressive Conditional Heteroscedasticity (GARCH) approach of forecasting crude oil market volatility are highlighted since these are the focus of the current study.
Several world events have led to major oil disruptions in the past. Most of these disruptions were related to political or military upheavals, especially occurred in the Middle East. Since 1973, there were four crises which have caused oil prices to be volatile. These include the 1973 Arab-Israeli war, the 1978-89 Iranian revolution, the 1980 Iran-Iraq war and the 1990-91 Gulf war which have resulted in initial shortfalls of between 4.0 and 5.6 million barrels per day (Marimoutou et al., 2009). In 1999, the increase in Iraq oil production coincided with the Asian financial crises which caused the oil price to drop due to a reduced in demand.
In September 2007, West Texas Intermediate (WTI) crude crossed $80 per barrel. There were several factors causing a raise in crude oil price. One of the main factors was when OPEC announced an output increase lower than expected (OPEC Press Release, 2009). US stocks fell lower than what The experts predicted (Energy Information Administration (EIA, 2007) the changes in federal oil policies (Andrews, 2007) and six pipelines were attacked by a leftist group in Mexico (Medina, 2007). In October 2007, US light crude rose above $90 per barrel due to a combination of tensions in eastern Turkey and the reduced strength of the US dollar (BBC News, 2007).
On July 11, 2008, oil prices hit a new highest record of $147.27 per barrel following concern over recent Iranian missile tests (BBC News, 2008). The extraordinary spike in prices represented to a large extent the consequences of a brief period where global oil demand outran supply. Commentators attributed these price increase to many factors, including reports from the United States Department of Energy and others showing a decline in petroleum reserves (Cooper, 2006), worries over peak oil (Energy Bulletin, 2009), Middle East tension, and oil price speculation (Herbst, 2008). However, after all these events, oil prices started to decline. A strong contributor to this price decline was the drop in demand for oil in the US. Prices did not rebound even during the beginning of 2009.
MATERIALS AND METHODS
The crude oil prices can be estimated and forecasted by several statistical methods. However, in this study the main focus is on the Box-Jenkins method and GARCH approach to estimate from the current data and forecast for the future prices. A class of models is introduced that can produce accurate forecasts based on a description of historical patterns in the data. Autoregressive Integrated Moving Average (ARIMA) models are a class of linear models that are capable of representing stationary as well as non-stationary time series. Since crude oil prices are volatile over the time trend, a heteroscedasticity approach shall be tested for the entire data series. Hence, a GARCH model is used which is able to capture volatility clustering in crude oil prices time series. Its performance is then compared with ARIMA model.
The West Texas Intermediate (WTI) daily crude oil prices data are obtained from Energy Information Administration (EIA, 2007) time-varying from 2nd January 1986 to 30th September 2009. The data are divided into two parts. One is for models’ estimation and another is for forecasting oil prices series purposes. The first part is in-sample period varying from 2nd January 1986 to 30th June 2009. It will be used to estimate the models. Meanwhile, the second part which is called out-of-sample period, varies from 1st July to 30th September 2009.
RESULTS AND DISCUSSION
One of the objectives is to forecast the future crude oil prices with Box-Jenkins model. For instance, the series is stationary after differencing of one lagged. Now, the model that the study is looking at is ARIMA(p, 1, q).
The series correlogram which consists of Autocorrelation Functions (ACF) and Partial Autocorrelation Functions (PACF) values was compute. The patterns of the ACF and PACF were observed and then the parameter values p and q for ARIMA model can be determined. From the correlograms, the values of ACF and PACF are relatively small and lie within the confidence intervals. Therefore, no ARIMA model can be identified from the first order difference of crude oil prices series.
The process is continued until another higher order of difference that is stationary is found. For this purpose, a second order lagged difference from the original series is obtained. Augmented Dickey-Fuller (ADF) test is conducted on this series to check for stationarity. The ADF test shows that the series is stationary. The t-statistic of -27.1096 is smaller than 1% of test critical value. The p-value for ADF test is zero indicating that we have sufficient evidence to reject the null hypothesis of the series being non-stationary.
From the correlogram of the second difference series, the ACF dies out after lag 1 and PACF dies out slowly after lag 1. Thus, the p and q values for the ARIMA(p,2,q) model are set at 1, respectively. So, for temporarily the ARIMA model is set to be ARIMA(1, 2, 1).
The parameter estimation of the model is conducted using the EViews software. Table 1 tabulates the results. From the t-statistics for the coefficient variables AR(p) and MA(q) in Table 1, the null hypotheses that the coefficients are equal to zero are rejected. The estimated parameter coefficients by ARIMA(1, 2, 1) model gives δ = 4.84x10-1, φ1 = –0.0608 and θ1 = –0.9975. The value for R2 = 0.5291, which implies that the dependency on the estimated value by the series is not strong. The Durbin-Watson (DW) statistic is approximately 2 due to the the existence of a positive serial correlation in the residuals. Thus, the model equation can be formed as:
| (1) |
| Table 1: | Estimation equation of ARIMA (1, 2, 1) |
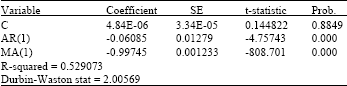 | |
The residuals of the ACF and the PACF are both relatively small or approximately equal to zero by diagnosing checking ARIMA(1, 2, 1) Model. The Q-statistic shows that the model is adequate.
An alternative test to Q-statistics for testing serial correlation is Breusch-Godfrey LM test. This test is on the null hypothesis of the Lagrange Multiplier (LM) test claiming that there is no serial correlation up to lag order p. The result of the Breusch-Godfrey LM test is tabulated in Appendix (Table 1).
From Appendix (Table 1), the F-statistic and Breusch-Godfrey LM test statistic are 16.4884 and 16.4517, respectively. Both of the p-values of F-statistic and Obs*R-squared are approximately zero indicate that there are significantly rejected the null hypothesis of no serial correlation up to lag p. Once again, the model was justified as adequate.
The residuals plot was plotted then for second order difference series data. Since the residuals are also changing with time, thus a volatile series is obtained. From the plotting, it can be seen some spiky residuals in high volatile periods such as the Gulf war in 1990-91 and during global economic crisis in 2008. The residuals plots are quite similar to the one for difference series. However, the dependent variable axis range is narrower.
The histogram and normality test are plotted. The mean value of the residuals is -0.0007 and the standard deviation is 1.0164 which is standard normal distributed N(0,1). Jarque-Bera test shows that the residuals series do not reject the null hypothesis of normally distributed at 5% significance level.
The duration of forecasts is from 1st July 2009 to 30th September 2009. In the Fig. 1 the solid line represents the forecast value of crude oil prices from 1st July 2009 to 30th September 2009. Meanwhile, the dotted lines which are above or below the forecasted daily crude oil prices show the forecast prices with ±2 of standard errors.
Figure 2 shows the plot of actual prices against forecast prices by using the model ARIMA(1, 2, 1). It can be seen that the forecast series follow the actual series closely.
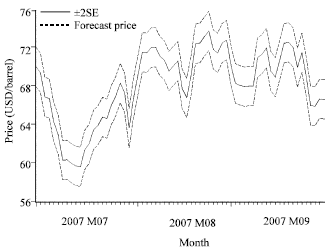 | |
| Fig. 1: | Forecast crude oil prices by ARIMA(1, 2, 1) |
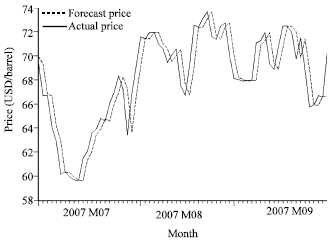 | |
| Fig. 2: | The plot of actual prices against forecast prices by ARIMA(1, 2, 1) |
There is a heteroscedasticity test developed by Engle (1982) called ARCH Lagrange Multiplier (LM) test. This test is used to determine the occurrence of ARCH effect in the residuals. The test has been compute and the test statistic for ARCH-LM distributed with χ2. The F-statistic value of 1235.601 is taken from the test equation for residuals squared. The p-value indicates that the F-statistic is significantly ARCH effects in the models. The ARCH-LM test statistic of 1028.464 also gives the same result for F-statistic as the one under χ2 (1).
Another important criterion to determine whether a series contains heteroscedastic is by checking the correlogram of the residual squared. At this point, it is also need to observe the patterns in the ACF and PACF of residuals squared for ARIMA(1, 2, 1) model. To check the ARCH effects, the ACF and PACF of residuals squared for ARIMA(1, 2, 1) model are plotted and it shows that there are spikes at the first lag for both ACF and PACF of residuals. This indicates that the ARCH effect does occur in the residuals for the ARIMA(1, 2, 1) model.
In ARIMA model, it was determined that ARCH effect occurred in the data series for ARIMA(1, 2, 1) model. This is due to the presence of volatility in crude oil prices data. The stationary first order difference series is used for testing the GARCH model.
GARCH(1,1) model is selected because crude oil prices data have the characteristics of volatility clustering and leptokurtosis. Sadorsky (2006) has suggested that GARCH(1,1) model is superior among prominent GARCH-type models for giving the best out-sample period forecasts.
The method to estimate the parameters is done by EViews software. The maximum likelihood estimator will find the parameter coefficients for conditional mean and conditional variance equations. Using EViews, the parameter coefficients on the dependent variable of the first order difference for daily crude oil prices are obtained and shown in Table 2.
From Table 3 for the conditional mean equation, the parameter found is μ = 0.0016. The standard normal distribution Z-test has rejected the parameter coefficients equal to zero, while the conditional variance equation gives α0 = 0.0012, α1 = 0.0978 and β1 = 0.9091. A high value of β1 means that volatility is persistent and it takes a long time to change. A high value of α1 means that volatility is spiky and quick to react to market movements (Dowd, 2002). Somehow, R2 gives a negative value in the estimation equation. In reality, the measure of R2 in GARCH model is not important because it is only used to test the ARCH effect of residuals. The Durbin-Watson (DW) test in GARCH(1, 1) model estimation is significant since it exceeds 2.
The GARCH(1, 1) model can be written into conditional mean and conditional variance Equations as:
| (2) |
| (3) |
After estimated the parameters, diagnostic checking on the adequacy for GARCH(1, 1) model has been computed. It can be done by checking the correlogram of standardized residuals squared which consists of autocorrelation and partial autocorrelation. From the results, ACF and PACF of residuals are approximately zero. The insignificant Ljung-Box Q-statistic also provides the same evidence with p-value that GARCH(1, 1) model is adequate.
| Table 2: | Estimation equation of GARCH (1,1) |
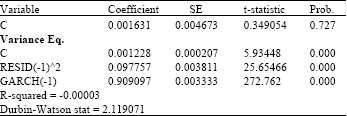 | |
| Table 3: | Comparison between ARIMA(1,2,1) and GARCH(1,1) models in estimation stage |
In diagnostic checking stage, a test for presenting of conditional heteroscedasticity in the data with ARCH-LM test on the residuals. There is computed one lag difference from the residuals squared in the ARCH-LM test. The test is tabulated in Appendix (Table 2).
The ARCH-LM for one lag difference of residuals squared is 0.0519 under . But, the null hypothesis is not rejected since the p-value is 0.8198 where it has greater than 5% of significance level. On the other hand, F-statistic for the test is 0.0519 also not rejected the null hypothesis at the same condition. The ARCH-LM test on the residuals of this model indicates that the conditional heteroscedasticity is no longer present in the data.
Apart from forecasting the conditional variance, the forecast of the conditional mean is done at the same time. Here, the daily forecast crude oil prices are the conditional mean from the original series. Figure 3 shows the forecast value for crude oil prices using GARCH(1, 1) model. In Fig. 3 the solid line presents the forecasted prices whereas the dotted lines are forecast prices with ±2 standard errors. The forecast crude oil prices fluctuate between $59 and $73 in 3-month out-sample period.
The forecast of conditional variance is plotted in Fig. 4. As shown in Fig. 4 the forecast of conditional variance is not constant. Since conditional heteroscedasticity searches for the non-constant variance that exists in time series data, then its trend is non-linear.
The actual and forecast daily crude oil prices by GARCH(1, 1) model are being plotted. From Fig. 5 it can be concluded that the trend of forecast prices follows the actual crude oil prices for 3 months out-sample period, closely.
One of the objectives of this study is to compare the forecast performances by two univariates time series models, namely Box-Jenkins and GARCH models. The comparison of the ARIMA(1, 2, 1) and GARCH(1, 1) models are made in terms of their Akaike Information Criterion (AIC) and Schwarz Information Criterion (SIC) values in the estimation stage and forecast performances in the forecasting stage.
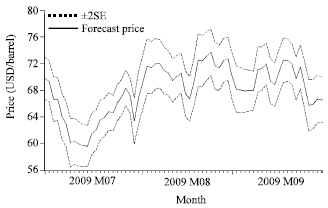 | |
| Fig. 3: | Forecast crude oil prices by GARCH(1,1) |
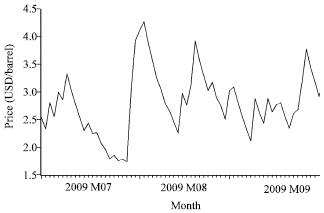 | |
| Fig. 4: | Conditional variance forecast By GARCH(1,1) |
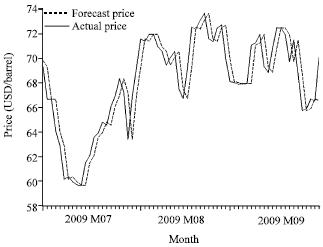 | |
| Fig. 5: | The plot of actual prices against forecast prices by GARCH(1, 1) |
In the model estimation step, the AIC and SIC values from ARIMA(1, 2, 1) and GARCH(1, 1) models are compared. In this context, the model with smaller AIC and SIC values are concluded to be the better estimation model. In Table 3, AIC and SIC values are obtained from equation estimation from both ARIMA(1, 2, 1) and GARCH(1, 1) models using EViews.
| Table 4: | Comparison between ARIMA(1,2,1) and Garch(1,1) models in forecasting performances |
 | |
It can be concluded that both the AIC and SIC values from GARCH(1, 1) model are smaller than that from ARIMA(1, 2, 1) model. Therefore, it shows that GARCH(1, 1) is a better model than ARIMA(1, 2, 1) for estimating daily crude oil prices.
In the forecasting stage, Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), Theil Inequality Coefficient (Theil-U) and Mean Squared Forecast Error (MSFE) values for ARIMA(1, 2, 1) and GARCH(1,1) models are determined. These are tabulated in Table 4. If the actual values and forecast values are closer to each other, a small forecast error will be obtained. Thus, smaller RMSE, MAE, MAPE, Theil-U and MSFE values are preferred.
From Table 4, it can be concluded that all forecast errors from GARCH(1,1) model is smaller than that from ARIMA(1, 2, 1) model. Therefore, we can conclude that GARCH(1, 1) model performs better than ARIMA(1, 2, 1). In other words, GARCH(1, 1) is a better forecast model for daily crude oil prices than ARIMA(1, 2, 1) model.
The analyses on daily crude oil have been conducted using two models. The ARIMA(1, 2, 1) model is able to produce forecasts based on the history patterns in the data. The GARCH(1, 1) model on the other hand, gives a better estimate when there are volatility clustering in the data series. This is due to the GARCH model’s ability to capture the volatility by the conditional variance of being non-constant throughout the time.
CONCLUSION
This study was undertaken to obtain a suitable GARCH and Box-Jenkins models for forecasting crude oil prices. ARIMA is a popular forecasting method. It is a general class of Box-Jenkins model for stationary time series. In the current study, the model that has been selected for forecasting crude oil prices is ARIMA(1, 2 ,1). This model gives reasonable and acceptable forecasts. However, despite the fact that this approach has been used extensively in various fields such as economics, agriculture and business, it does not perform very well when there exists volatility in the data series. To handle volatility, the current study uses the GARCH model. Most of the time, GARCH models can accommodate volatility clustering and leptokurtosis very easily. Dowd (2002) stated that GARCH are tailor-made for volatility clustering and it produces returns with fatter than normal tails even if the innovations and the random shocks are normally distributed. GARCH approach involves model identification, model estimation and forecasting. In the current study, the model that has been selected for forecasting crude oil prices is GARCH(1,1). The model performs better than ARIMA(1, 2, 1) because of its ability to capture the volatility by the conditional variance of being non-constant throughout the time. In this study, GARCH(1, 1) was concluded to be a better model than ARIMA (1, 2, 1) in forecasting crude oil prices because the values for RMSE, MAE, MAPE, Theil-U and MSFE calculated using this model were smaller than those calculated using ARIMA(1, 2, 1) model.
Future studies in this area can also use a hybrid method, which combines the Box-Jenkins with GARCH. The hybrid model is an alternative to forecast crude oil prices because it contains both qualities of Box-Jenkins and GARCH methods. Other GARCH-type models that should be investigated to forecast crude oil prices data are Integrated GARCH (IGARCH) and Exponential GARCH (EGARCH).
ACKNOWLEDGMENTS
This study was supported by Universiti Malaysia Pahang (UMP), under the University Research Grant (RDU090307).
APPENDIX
| Table 1: | Serial correlation Breusch-Godfrey LM test for ARIMA (1,2,1) |
| Table 2: | ARCH-LM test for GARCH (1,1) |
REFERENCES
- Cabedo, J.D. and I. Moya, 2003. Estimating oil price value at risk using the historical simulation approach. Energy Econ., 25: 239-253.
Direct Link - Fan, Y., Q. Liang and Y.M. Wei, 2008. A generalized pattern matching approach for multi-step prediction of crude oil price. Energy Econ., 30: 889-904.
Direct Link - Fong, W.M. and K.H. See, 2002. A markov switching model of the conditional volatility of crude oil price. Energy Econ., 24: 71-95.
Direct Link - Ghaffari, A. and S. Zare, 2009. A novel algorithm for prediction of crude oil price variation based on soft computing. Energy Econ., 31: 531-536.
Direct Link - Giot, P. and S. Laurent, 2003. Market risk in commodity markets: A VaR approach. Energy Econ., 25: 435-457.
CrossRef - Godby, R., A.M. Lintner, T. Stengos and B. Wandschneider, 2000. Testing for asymmetric pricing in the canadian retail gasoline market. Energy Econ., 22: 349-368.
Direct Link - Assis, K., A. Amran, Y. Remali and H. Affendy, 2010. A comparison of univariate time series methods for forecasting cocoa bean prices. Trends Agric. Econ., 3: 207-215.
CrossRefDirect Link - Kulkarni, S. and I. Haidar, 2009. Forecasting model for crude oil price using artificial neural networks and commodity futures prices. Int. J. Comput. Sci. Inform. Security, 2: 1-8.
Direct Link - Liu, J., Y. Bai and B. Li, 2007. A new approach to forecast crude oil price based on fuzzy neural network. Int. Conf. Fuzzy Syst. Knowledge Discovery, 3: 273-277.
CrossRef - Marimoutou, V., B. Raggad and A. Trabelsi, 2009. Extreme value theory and value at risk: Application to oil market. Energy Econ., 31: 519-530.
CrossRef - Shabri, A., R. Samsudin and Z. Ismail, 2009. Forecasting of the rice yields time series forecasting using artificial neural network and statistical model. J. Applied Sci., 9: 4168-4173.
CrossRefDirect Link - Sadorsky, P., 2006. Modeling and forecasting petroleum futures volatility. Energy Econ., 28: 467-488.
CrossRef - Fahimifard, S.M., M. Homayounifar, M. Sabouhi and A.R. Moghaddamnia, 2009. Comparison of ANFIS, ANN, GARCH and ARIMA techniques to exchange rate forecasting. J. Applied Sci., 9: 3641-3651.
CrossRefDirect Link - Xie, W., L. Yu, S. Xu and S. Wang, 2006. A new method for crude oil price forecasting based on support vector machines. Lecture Notes Comput. Sci., 3994: 444-451.
Direct Link - Xu, S., X. Chen and A. Han, 2008. Interval forecasting of crude oil price. Adv. Soft Comput., 46: 353-363.
CrossRef - Engle, R.F., 1982. Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica, 50: 987-1007.
CrossRefDirect Link