
S. Abdullah
Department of Mechanical and Materials Engineering, Universiti Kebangsaan Malaysia,43600 UKM Bangi, Selangor, Malaysia
M. D. Ibrahim
Department of Mechanical and Materials Engineering, Universiti Kebangsaan Malaysia,43600 UKM Bangi, Selangor, Malaysia
Z. Mohd Nopiah
Department of Mechanical and Materials Engineering, Universiti Kebangsaan Malaysia,43600 UKM Bangi, Selangor, Malaysia
A. Zaharim
Department of Mechanical and Materials Engineering, Universiti Kebangsaan Malaysia,43600 UKM Bangi, Selangor, Malaysia
Journal of Applied Sciences
Year: 2008 | Volume: 8 | Issue: 8 | Page No.: 1590-1593







ABSTRACT
This study presents the description of fatigue damage in the context of the statistical process control paradigm. The quality control approach that was used in the analysis was needed in order meet the requirements as well as improving the fatigue damage caused by variable amplitude loading. The methodology discussed in this study is enabling to reduce variability with the specification limits at three standard deviations on both side of the mean value. This concept was used to comparing three ARIMA models that have been previously found based on potential capability value (Cp) and Mean Squared Deviation (MSD). The assumption was made when the process reached the upper and the lower control limits in term of reducing the variability that was described by a variable amplitude fatigue loading. A successive three-sigma concept was then applied and developed on to this type of loading and it purpose was to detect the variation. Finally, it is suggested that the three-sigma concept provided a good platform for analyzing the fatigue damage in the aspect of the durability assessment.
PDF Abstract XML References Citation
How to cite this article
S. Abdullah, M. D. Ibrahim, Z. Mohd Nopiah and A. Zaharim, 2008. Analysis of a Variable Amplitude Fatigue Loading Based on the Quality Statistical Approach. Journal of Applied Sciences, 8: 1590-1593.
DOI: 10.3923/jas.2008.1590.1593
URL: https://scialert.net/abstract/?doi=jas.2008.1590.1593
DOI: 10.3923/jas.2008.1590.1593
URL: https://scialert.net/abstract/?doi=jas.2008.1590.1593
INTRODUCTION
A signal is a series of number that come from measurement, typically obtained using some recording method as a function of time. In the case of fatigue research, the signal consists of a measurement of a cyclic loads, i.e. force, strain and stress against time. Fatigue life prediction is important in the design process of vehicle structural components consists a set of observations of a variable taken at equally spaced intervals of time (Anderson, 1998). Today, most of the experimental measurements, or data samples, are performed digitally. It is also known as a discrete time series data, which is formed digitally. It is also known as a discrete time series data, which is formed as a function of time. Time series data also can analysis with Statistical Process Control. Statistical Process Control is also related to the signal analysis in order to determine the occurrence of causes when it fluctuates randomly by eliminating the variation in the fatigue data (Del Castillo, 2002).
Many data mining application deal with some privacy sensitive data sets. The best means of obtaining unpredictable random numbers is by measuring physical phenomena, such as fatigue damage, radioactive decay, thermal noise in semiconductors and even digitized images of a lava lamp. However, few computers (or users) have access to the kind of specialized hardware required for these sources and they must rely on other means of obtaining random data (Newland, 1993).
The objective of this study is to observe the capability of a statistical technique called Statistical Process Control (SPC), for which it is to quickly detect the occurrence of assignable causes. This process can preserving data by randomly perturbing data associated to the underlying probabilistic properties. This has fostered the development of a class of data algorithms that were used to extract the data pattern without directly accessing the original data and guarantees that the process. A major advantage of performing this process is the ability of the modeler to select the proper model based on six-sigma from possibly large selection of the available model formulation. This approach is used to preserved data privacy from natural variability or background noise (Agrawal and Aggawal, 2001).
Many signal in nature exhibit behave in a systematic or non-systematic characteristic that provide a challenge in analysis. A systematic manner happens when all the points plot inside the control limits. This process indicates it is out of control. The non-systematic characteristics display when all the plotted points have an essentially random pattern (Agrawal and Srikant, 2000). The statistical concepts that form the basis is a control charts. The control chart is a graphical display of a quality characteristic that has been measured or computed from the sample versus the sample number or time (Kotz and Johnson, 2002). The chart contains a center line that presents the average value of the quality characteristic corresponding to the in-control state. Methods for looking for sequences or non-random patterns can be applied to control charts as an aid in detecting out-of-control conditions (Lu and Reynolds, 1999). A signal representing a random physical phenomenon cannot be described in a point by point manner by means of a deterministic mathematical equation. This characteristic is common among a fairly a large number of time series met in the real world. The actual data is illustrated by a random data set, as in Fig. 1.
In a normal practice, the global signal statistical values are frequently used to classify random signals. The most commonly used are the mean and the standard deviation values. For a signal with a number n of data points, the mean value of ![]()
| (1) |
On the other hand, the Standard Deviation (SD) is mathematically defined as:
| (2) |
for a measurement of the central tendency and dispersion of the sample. The standard deviation value measures the spread of the data about the mean value. Furthermore, the probability is 1–α that any sample mean will fall between
| (3) |
and
| (4) |
Therefore, if μ and σ are known, Eq. 3 and 4 could be used as upper and lower control limits on a control chart for sample means. It is customary to replace Zα/2 by 3, so that three-sigma limits are employed.
Control chart is one of the primary techniques of the SPC approach. The control chart has a Centre Line (CL) and upper and lower control limits where w be a sample statistic that measures some quality characteristic of interest. It is suppose that involved the mean of w is μw.
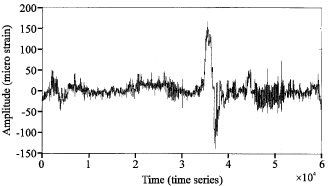 | |
| Fig. 1: | A variable amplitude fatigue strain loading data plotted in the time domain distribution |
Then the center line, the Upper Specification Limit (USL) and the Lower Specification Limit (LSL) are defined as the following relationship:
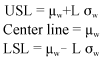 | (5) |
where, L is the distance of the control limits from the center line, expressed in standard deviation units (Runger and Testik, 2003). The general theory of charts was developed according to this principle is often called Shewhart control charts (Matrangelo et al., 1996). Shewhart control chart are commonly used by X-bar and S-control charts. The X-bar control chart provides a framework for monitoring the changes of the selected feature means and for identifying observation points that are inconsistent with the past data set. The S-control chart monitors the process variance in a similar way as the X-bar control chart.
The three-sigma concept was initially developed, an assumption that was made when the process reached the three-sigma quality level, the process mean was still subject to disturbances that could cause by standard deviation (Walker and Wright, 2002). However, no process or system is ever truly stable and even in the best of situations, disturbances occur. The concept of a three-sigma process is one way to model this behavior. It has proven to be a useful way to think about process performance (Wadsworth et al., 2002).
In an automobile industry, a designation of automotive component such as an exhaust manifold experiencing thermal and mechanical loads with the possibility of cracking by fatigue damage mechanism. It is desirable to be designed into a component rather than for failures to be managed away during manufacturing.
To meet these challenges, many manufacturers have adopted the three-sigma approach to total quality management whereby all aspects of component design and manufacture are examined to reduce failure rates to as near zero are sensibly possible.
MATERIALS AND METHODS
The quality control method had been applied to the fatigue data in order to determine the best model based on two criteria. The criteria based on potential capability (Cp) and Mean Squared Deviation (MSD).
The quality control that has applied can provide information about performance or capability of the process in the fatigue damage. The process capability ratio in the analysis based on Cp. Firstly Cp, which for a quality characteristic with the upper and lower specification limits, or also notated as USL and LSL respectively. The Cp value is mathematically defined as the following equation:
| (6) |
The Mean Squared Deviation (MSD) is a number that representing an average deviation of the results from the target (or the average, in absence of a target). It is strictly as a function of the average and the standard deviation. It is independent of the specification limits, as it does not make use of them. For comparison purposes, a set of data with a lower MSD is preferable. The MSD value is defined as the following equation:
| (7) |
where, n is the number of observations in the series and y is a number of observation.
The techniques of statistical inference can be classified into two broad categories that are parameter estimation and hypothesis testing. The parameter that was used for the analysis is Mean Squared Error (MSE). It is a measure of an accuracy computed by squaring the individual error for each item in a data set and then to find the average or mean value of the sum of those squares (Boyles, 1991). The MSE value gives greater weight to the large errors than to the small errors. It is because of the errors are squared before being summed. The MSE value is mathematically defined as the following expression:
| (8) |
where, n is the number of observations in the series and e is a error terms. Based on result, it showed that model ARIMA (1,1,1) give a lower MSE that is 1125431 (Shahrum et al., 2007). That means the model ARIMA (1,1,1) is the best than model ARIMA (0,1,0) and ARIMA (0,1,1).
RESULTS AND DISCUSSION
The data which was shown in Fig. 1, was collected in North Wales, United Kingdom. This fatigue signal, having a variable amplitude pattern in the strain format, was measured on the front left lower suspension arm of an automobile which was traveling on public road surface (a mixture of smooth and irregular asphalt). It was sampled at 200 Hz for 45,000 data points. The length of this time series is 300 sec. This data produced mean value of 2.34 microstrains and the standard deviation value of 25.47 microstrains.
The potential capability (Cp) in Eq. 6 has useful practical interpretation, the percentage of the specification band used up by the process. Based on the Cp value have been found from the related analysis, it implies the natural tolerance limits in the process (three-sigma above and below the mean) which is inside the lower and upper specification limit.
Mean squared deviation is strictly a function and the standard deviation. The MSD in Eq. 7 has useful practical interpretation, the average deviation of the specification band used up by the process. Based MSD values have been found from the related analysis, it implies that the natural tolerance limits in the process (three-sigma above and below the mean) which is inside the lower and upper specification limit.
Table 1 shows the descriptive statistical values based on three ARIMA models which was calculated using the SPSS, MatLab and Minitab software packages. Based on standard deviation values, the result showed that the model ARIMA (1,1,1) gave smaller variability compared to other model. On the average the data from 3 models gives around 2.33 microstrains. That means a trend of model ARIMA (0,1,0) and ARIMA (0,1,1).
The Cp values showed that ARIMA (1,1,1) produced the value which is 35.54, higher than ARIMA (0,1,1) and ARIMA (0,1,0). It means that the data of ARIMA (1,1,1) is more capable in the process which a variation is lower than both model.
| Table 1: | Global statistical parameter obtained for the analysed time series |
 | |
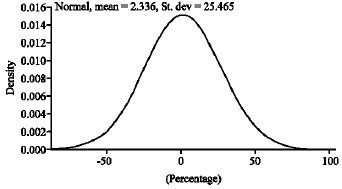 | |
| Fig. 2: | Probability distribution plot |
Beside that, the MSD values showed that model ARIMA (1,1,1) produced the value which is 7.90, lowest than model ARIMA (0,1,1) and ARIMA (0,1,0). It means that the data of ARIMA (1,1,1) is more consistently close to the process which an average variability is lower than both model. It can described by a standard deviation value where ARIMA (1,1,1) is 25.21 lower than both model.
Figure 2 shows the probability distribution plot. It is used to view areas under distribution curves corresponding to either probabilities or data values. The probability distribution plot for model ARIMA (0,1,0), ARIMA (0,1,1) and ARIMA (1,1,1) are similar where the skewness value are close with one another. The skewness value for the 3 model ARIMA are shown in Table 1. Finally, the distribution of model ARIMA (0,1,0), ARIMA (0,1,1) and ARIMA (1,1,1) are exhibit skewed to the right.
CONCLUSION
The fatigue damage of statistical control paradigm has meet requirement in improving fatigue damage caused by variable amplitude loading. The quality control that generated by potential capability (Cp) and MSD value that described in this study has proven to be relatively portable across different systems. In addition, it provides a good source of practically strong random data on most systems and can be set up to function independently of special hardware or the need for user or programmer input, which is often not available. The conclusion from analysis shows that ARIMA (1,1,1) is the best model because it gives a higher potential capability (Cp) value and lowest Mean Squared Deviation (MSD). The study suggested that the model can give a better statistical technique, by means of the quality control approach in analyzing variable amplitude fatigue loading. However, a conclusive study on this aspect should also be performed in order to know a better situation between ARIMA and fatigue damage characteristics.
ACKNOWLEDGMENTS
The authors would like to express their gratitude to Universiti Kebangsaan Malaysia and Ministry of Higher Education, Malaysia through the FGRS fund of UKM-KK-02-FRGS0016 for representing these research activities.
REFERENCES
- Agrawal, D. and C.C. Aggawal, 2001. On the design and quantify of privacy preserving data mining algorithms. Proceedings of the 20th ACM SIMOD Symposium on Principles of Database Systems, May 21-23, 2001, ACM, New York, pp: 247-255.
Direct Link - Agrawal, R. and R. Srikant, 2000. Privacy-preserving data mining. Proceedings of the 2000 ACM SIGMOD Conference on Management of Data, May 14-19, 2000, ACM, Dallas, TX., pp: 439-450.
CrossRefDirect Link - Andersen, M.R., 1996. Fatigue damage analysis by use of cyclic strain approach. Ship Technol. Res., 43: 155-174.
Direct Link - Mastrangelo, G.C. Runger and D.C. Montgomery, 1996. Statistical process monitoring with principal components. Qual. Reliab. Eng. Int., 12: 203-210.
CrossRefDirect Link - Runger, G.C. and M.C. Testik, 2003. Control charts for monitoring fault signatures: Cuscore versus GLR. Qual. Reliability Eng. Int., 19: 387-396.
Direct Link