
Ali Peiravi
Faculty of Engineering, Ferdowsi Mashhad University, Mashhad, Iran
Hossein Tolooei Kheibari
Faculty of Engineering, Ferdowsi Mashhad University, Mashhad, Iran
Journal of Applied Sciences
Year: 2008 | Volume: 8 | Issue: 8 | Page No.: 1462-1470







ABSTRACT
In this study, we focus on dynamic networks, where moving agents produce varying connectivity graphs in time. We use the velocity information of every agent to develop a fast algorithm to approximate the connectivity graph of dynamic networks. Also we used mean degree distribution instead of degree distribution to investigate congestion/interference of network when approximate method is used. We introduced a modification factor for connectivity distance, R in Manhattan measure to increase the accuracy in a wide range of R. The results for two random distributions of agents based on Monte Carlo simulation are compared to the present real connectivity method to show the superiority of our approach.
PDF Abstract XML References Citation
How to cite this article
Ali Peiravi and Hossein Tolooei Kheibari, 2008. Connectivity Graph Approximation Using Modified Manhattan Distance in Mobile Ad Hoc Networks. Journal of Applied Sciences, 8: 1462-1470.
DOI: 10.3923/jas.2008.1462.1470
URL: https://scialert.net/abstract/?doi=jas.2008.1462.1470
DOI: 10.3923/jas.2008.1462.1470
URL: https://scialert.net/abstract/?doi=jas.2008.1462.1470
INTRODUCTION
Different terms such as connectivity graphs, link graphs and communication graphs are used interchangeably in the literature for graphical models that capture the local limitations of sensing and communication in decentralized networked systems (Muhammad et al., 2005). Computation of connectivity graphs has developed as a key problem in various engineering branches specially in communication and control. For example, control of Unmanned Air Vehicles (UAV) based on decentralized control has developed in recent years. Decentralized control approach is a result of studying swarms of insects which offer clear examples of self-organized, emergent behavior (Guadiano and Clough, 2003). In the problem of coordinating multiple robots, a representation of the configuration space appears naturally, by using graph-theoretic models to describe the local interactions in the formation (Muhammad and Egerstedt, 2005a; Muhammad et al., 2005). In these cases, graph-based models serve as an interface between the discrete and the continuous. Notable results for these problems have been presented (Olfati Saber and Murray, 2003; Mesbahi, 2002; Jadbabaie et al., 2003; Tanner et al., 2003). In Muhammad et al. (2005), several applications of connectivity graphs and their dynamics are presented.
In simulating large mobile networks, a main problem is the high cost of storage requirements. It may even be impossible to model such networks due to the huge extent of storage requirements.
In modeling such networks, it is necessary to determine the evolving connection between nodes. In other words, we must dynamically determine who can communicate with whom. This will be called graph connectivity in the rest of the study. As the number of nodes in the network is increased, routing protocols which need to determine the connectivity graphs can grow quadratically. Guadiano and Clough (2003) and Carling et al. (2003) discuss that if the existence of a link between two agents corresponds to certain geometric relations such as the distance between them, the graphs will be dynamic in time in cases where agents are mobile. In other words when nodes move, the distances between them change. This results in the breaking of some existing links and the formation of some new ones in time. Therefore, it is necessary to compute the connectivity matrix over and over again. Thus for the simulation of large dynamic networks it is important to develop faster graph connectivity determination techniques with a reasonable degree of accuracy (Muhammad and Egerstedt, 2005b; Barrett et al., 2004).
In Muhammad and Egerstedt (2005b), the limitations in formation of connectivity graphs are discussed and topological limits are introduced and in Barrett et al. (2004) some approximate methods for determining connectivity graph are discussed.
In this study, we discuss the problem of determining connectivity graphs of dynamic networks using approximate methods and introduce a new efficient algorithm for approximating the connectivity graph. This method has a good accuracy while it requires less computation and is much faster than previous methods. Results are presented based on Monte Carlo simulation using default information about the velocity of each agent. Also we used mean degree distribution instead of degree distribution to investigate congestion/interference of network when approximate methods are used. We compared the performance of these measures for two different distributions of nodes.
REAL AND APPROXIMATE CONNECTIVITY GRAPHS
The most realistic model of connectivity of agents which Barrett et al. (2004) label real connectivity is based on calculations using Euclidian distance between nodes and comparing the obtained results with radio distance. This model is based on two-ray ground propagation model where the received power is inversely proportional to the square of the distance up to a limiting distance and is inversely proportional to the fourth power of the distance beyond that threshold. In this model we do not consider radio interference effects. Therefore the real model inherently has some approximation. For two nodes Ni (xi, yi) and Nj (xj, yj), the Euclidian distance is as follows:
| (1) |
Radio distance R, is defined as the connectivity range for every node which is compared by Euclidian distance between a pair of nodes Ni and Nj.
| (2) |
| (3) |
In the remainder of the study we name this method as the real method and use it for comparison with our proposed algorithm. In order to save computational time, R2 is used instead of R for comparison with the square of Euclidian distance. This saves the computation of root square for computing the distance between every pair of nodes. Computationally this model includes two subtractions, two multiplications, an addition and a comparison which must be carried out for each pair of nodes. Therefore, the total amount of computational time, TE, for n nodes will be:
| (4) |
where, Ts, Tm, Ta and Tc are the computational times of a subtraction, a multiplication, an addition and a comparison, respectively.
Using the number of clock cycles required for the execution of instructions of Intel Pentium 4 processor (Intel Co., 2006) results in:
| (5) |
This is the case for an undirected network since radio range is equal for all nodes in undirected networks. Barrett et al. (2004) have investigated the performance of some approximate measures like Manhattan distance metric connectivity, k-means cluster connectivity and box connectivity for determining connectivity graphs. They have shown that the Manhattan distance is one of the best approximate measures for computing the connectivity graph of undirected networks (Barrett et al., 2004). We have based our method upon this metric and have implemented a fast algorithm which reduces the computational time in dynamic networks. The Manhattan distance for two nodes Ni and Nj is simply the sum of component-wise distances:
| (6) |
The computations for this metric include two subtractions, an addition and three comparisons being two comparisons for the absolute values and one for comparing RMij with R for each pair of nodes (Barrett et al., 2004). Therefore the total amount of computational time TM, for n nodes will be:
| (7) |
Which on a Pentium 4 Intel processor will require
| (8) |
Comparing the results of Eq. 5 and 8 shows that by using Manhattan measure instead of Euclidian measure the computational time reduces by 40%. This reduction can be appreciable when the number of nodes is very large because the computational time is proportional to the square of n.
COMPARING CONNECTIVITY GRAPHS: METRICS AND MEASURES
In order to evaluate the efficiency of our method well-established techniques for comparing radio connectivity graphs were used and the connectivity matrices (real and approximate) in both static and dynamic networks were compared. In each case after determining the connectivity matrices, they were compared with each other. Two different approaches were used for comparing the graphs. The first comparison approach which is more statistical is based on degree of nodes. In the first approach two different methods are used. In the first method degree distributions of nodes for a network are determined using real and approximate measures. Degree distribution shows the number of nodes which have different possible degrees in the network. The results are compared to investigate congestion of network when approximate methods are used. Here, two graphs are considered to be similar if they have the same degree distribution. Also mean degree of nodes is used as a measure. In this method mean degree of nodes for different connectivity distances is determined using real and approximate methods. Two graphs are considered to be similar if they have the same mean degree distribution for different connectivity distances. In the second approach the resultant connectivity matrices are compared. In other words, links are compared one by one and Hamming distance between their connectivity matrices is used. A connectivity matrix for each graph is set up where every 1 in the matrix shows the connection between the nodes corresponding to the related row and column nodes. Hamming distance from one binary vector to another is the number of corresponding elements which differ. For example H ([1101], [0110]) = 3.
Obviously the size of graphs to be compared must be the same. A deficiency of the Hamming distance is that it is not invariant with respect to graph size and one cannot draw any sound conclusions from it when comparing networks of various sizes. If we divide the Hamming distance by the number of elements of the connectivity matrix we will have a metric that is invariant with respect to the size of the graphs. Barrett et al. (2004) called this metric the percent Hamming distance and denoted it %H.
| (9) |
MONTE CARLO SIMULATION IN STATIC AND DYNAMIC CASES
Monte Carlo simulations were carried out in static and dynamic cases. In each case two spatial distributions were used for the nodes in the network-namely normal and uniform. The region occupied by the nodes is considered to be a 1 km2 for uniform spatial distribution and a circle with a radius of 2.5 km for normal spatial distribution. Normal and uniform distributions were used as representatives for uniformly and non-uniformly distributed networks. In each distribution, the mean degree (D) distribution, degree distribution and the percent Hamming (%H) measures for the real and the approximate methods were determined. In static case, the performance of Manhattan method and modified Manhattan method were experimented using Monte Carlo simulations. The acceptable performance of Manhattan measure for nodes which are distributed normally and uniformly is shown. Then a modification factor is introduced to improve the performance of the Manhattan measure and the results are used in the dynamic case to implement our algorithm.
Monte carlo simulations in static case: In order to carry out the Monte Carlo simulations in static case two networks were constructed whose nodes had a spatially normal and uniform distribution, respectively. In each network, the mean degree of nodes for every R was calculated from which the mean degree distribution of nodes was determined. For degree calculation, we used three different methods: precise method using Euclidean distance, approximate method using Manhattan distance measure and Manhattan measure using modified connectivity range. We used a zero mean unity variance normal distribution in which more than 99% of nodes are located in a circle with a radius of 2.5 km. We calculated real and approximate measures for a range of R from 0.01 to 1.4 km (diagonal of 1 km2) for uniform and 5 km for normal distribution with 0.01 km increments. Circular and square regions are representatives for two different regions of nodes in two dimensional space. We used averaging of results to minimize changes. For every R, computations were repeated 10 times and averaged, yielding an rms error of less than 5%.
The degree distribution should be calculated for a specific R. For R = 0.25 km the degree distributions are shown in Fig. 1. The networks include 1000 nodes. Obviously in both distributions real and approximate results have many differences. Using approximate Manhattan measure the maximum frequency of occurrence of a node with a degree specified on the horizontal axis increases and generally the degree of nodes decreases according to real measure.
The mean degree distribution using real and approximate methods are shown in Fig. 2. Both normally and uniformly distributed networks have the same pattern of mean degree distribution versus R distance, but with different scales. Obviously when R is increased, the mean degree of nodes is increased because the maximum radio range is increased and more nodes can communicate together. In the normally distributed network, mean degree distribution reaches its maximum at R~5 km, but in a uniformly distributed network, it reaches its maximum at R~1.4 km. As can be seen from Fig. 2, real mean D distribution is bigger than or equal to the approximate mean D distribution for the same R. Also Fig. 2 shows that approximate results are less than real results for similar R and both curves are incremental.
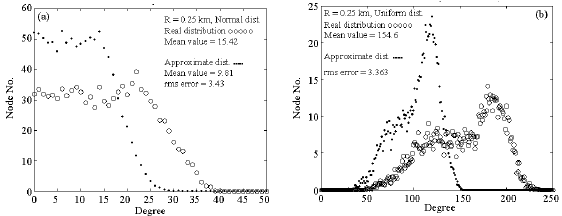 | |
| Fig. 1: | Degree distribution for (a) normal and (b) uniform spatial distribution of nodes resulted from approximate Manhattan and real method |
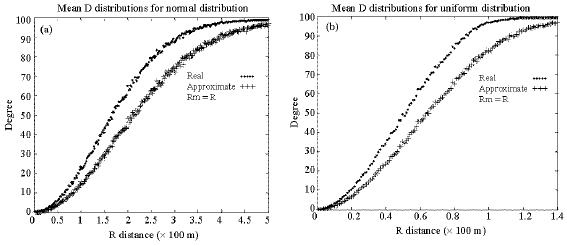 | |
| Fig. 2: | Mean D distribution for (a) normal and (b) uniform spatial distribution of nodes resulted from approximate Manhattan and real method |
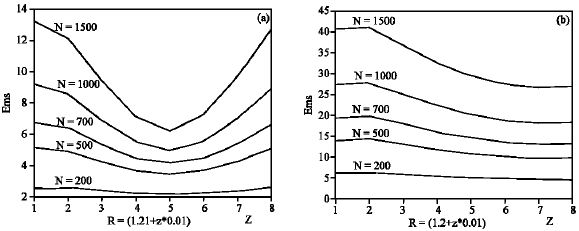 | |
| Fig. 3: | RMS error variations versus modification factor for different N for (a) normal and (b) uniform spatial distribution of nodes |
So we can use bigger R in approximate calculations to decrease error. We tried to find the best modification coefficient m to minimize rms error. The average rms error for different values of m was calculated in each distribution. The results were averaged for different values of R. Figure 3 shows the results for different number of nodes. In Fig. 3a, minimum rms error for different N is for z = 5 and so m = 1.26 and in uniform case (Fig. 3b), it is satisfied for z = 7 and so m = 1.27.
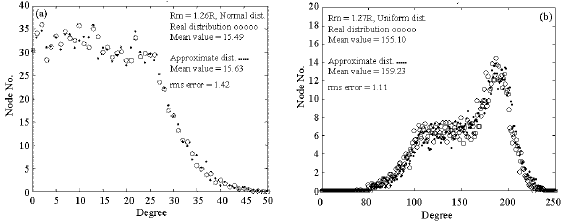 | |
| Fig. 4: | Degree distribution for (a) normal and (b) uniform spatial distribution of nodes resulted from modified approximate Manhattan and real methods |
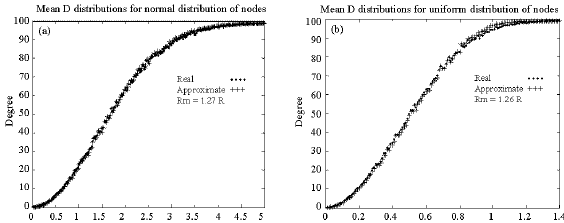 | |
| Fig. 5: | Mean D distribution for (a) normal and (b) uniform spatial distribution of nodes using modified approximate and real methods |
For Rm = 1.27R in uniform distribution the best similarities are seen between real and approximate results because the rms error is minimum. In normal distribution for Rm = 1.26R minimum rms error results.
The degree distribution curves using modified R in approximate Manhattan measure are shown in Fig. 4 which seem very similar to real one in both spatial distributions of nodes. Therefore modified approximate measure has negligible effect on congestion/interference characteristics of network.
Figure 5 shows the mean degree distribution curves using modified R which decreases rms error appreciably in both distributions. Modified approximate measure has negligible effect on congestion/interference characteristics of network as shown in Fig. 5. Similar results from Fig. 1, 4 and Fig. 2, 5 show that mean degree distribution versus R can be used as a interference/congestion measure instead of degree distribution.
In Fig. 6, maximum rms error and rms error curve limited area are compared for traditional and modified R. In normal distribution rms error curve limited area decreases by 7.17 times and in uniform distribution it decreases by 5.94 times, as shown in Fig. 6a and b. Also maximum error is decreased by 5.43 and 7.16 times for uniform and normal distributions of nodes, respectively.
We determined the connectivity matrices for every R by real and approximate measures and compared them using the graph difference metric, %H. In Fig. 7, curves of %H using traditional and modified R for both distributions are shown. It can be seen that the maximum dissimilarity in the performance of the approximate method using traditional R is about 17.5% in normal distribution of nodes, while it is only 3.6% when using our modification factor for connectivity range, Rm = 1.26R. Also for uniform distribution of nodes as shown in Fig. 7b, maximum dissimilarity for traditional R is about 17%, while it is only 3.5% when using our modified measure for Rm = 1.27R.
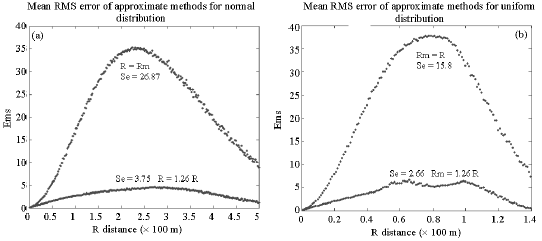 | |
| Fig. 6: | Mean D distribution rms Error comparison of the best modified R and traditional R for (a) normal and (b) uniform spatial distribution of nodes |
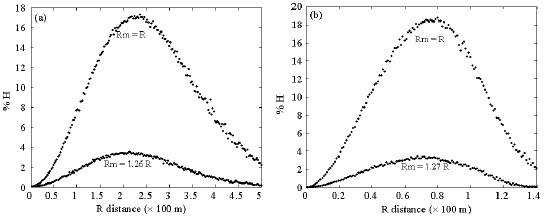 | |
| Fig. 7: | %H distribution versus R using traditional R and modified R for (a) normal and (b) uniform spatial distribution of nodes |
This shows that using our modified Manhattan measure, maximum dissimilarity reduces by 4.87 times in uniform distribution and by 4.61 times in normal distribution of nodes.
Monte carlo simulations in dynamic case: In previous section a modification factor for R was introduced to improve the accuracy of approximate Manhattan measure. We name this method as modified Manhattan in the remainder of the study. In order to carry out the Monte Carlo simulations in dynamic case our experiments were set up with nodes with specification (x, y, v, θ) in which v is the velocity and θ is the angle of movement. Velocity v is the distance by which a node moves in θ direction in every step of the calculations. Parameters v and θ are determined based on uniform distribution because only the number (or percentage) of low speed nodes is important. In other words the time consumption of our algorithm is based on the number of low speed agents and the type of their distribution does not affect the results. In order to generate θ, the random number ![]() which is limited between [0, 1], is multiplied by 2π. Also in order to limit the velocity of each node,
which is limited between [0, 1], is multiplied by 2π. Also in order to limit the velocity of each node, ![]() which is similar to
which is similar to ![]() is multiplied by a velocity coefficient, Cv which is less than one. This means that the velocity, v, of every node is the result of multiplication of
is multiplied by a velocity coefficient, Cv which is less than one. This means that the velocity, v, of every node is the result of multiplication of ![]() , Cv and the size of the square region in which the nodes are distributed. In every step, nodes move to a new location based on their velocity and direction and their positions are considered to be fixed during the calculations. To speed up the calculations low speed nodes are considered to be stationary. Therefore, the calculations are not repeated for them in every step. The position information for the nodes must be refreshed in every so many steps based on their speed and acceptable error.
, Cv and the size of the square region in which the nodes are distributed. In every step, nodes move to a new location based on their velocity and direction and their positions are considered to be fixed during the calculations. To speed up the calculations low speed nodes are considered to be stationary. Therefore, the calculations are not repeated for them in every step. The position information for the nodes must be refreshed in every so many steps based on their speed and acceptable error.
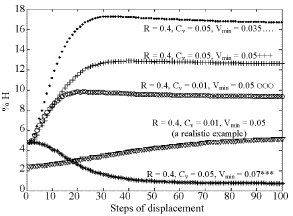 | |
| Fig. 8: | %H distribution for different conditions for uniform distribution of nodes |
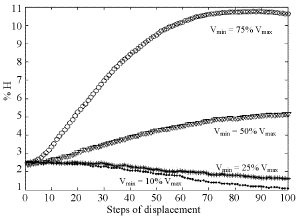 | |
| Fig. 9: | %H distribution calculated by velocity based method using modified Manhattan measure for R = 0.25 km, Vmax = 0.01 km per step and four values of Vmin |
We examined the results by changing R and Cv and determined Hamming measure using real and approximate methods. In Fig. 8, %H curves for uniform distribution of nodes are shown for various conditions as shown on the figure. As shown, based on the conditions, different curves are obtained but our discussion is based on realistic conditions.
As a realistic example, maximum v (or Cv) was considered 0.01 km per step of calculations and R = 0.25 km as considered by Barrett et al. (2004). Minimum velocity for nodes which are considered non-stationary in our algorithm was selected as 0.001, 0.0025, 0.005 and 0.0075 km per step of calculation. Our velocity based method was implemented using modified R Manhattan method for the above chosen velocities of Vmin to show the low level of dissimilarity. In each case the connectivity matrix was determined and compared with the real case. The dissimilarity between two connectivity matrices being represented by %H is shown in Fig. 9.
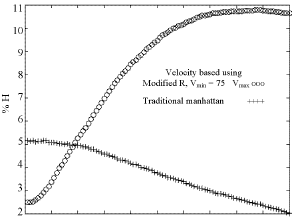 | |
| Fig. 10: | Comparison of %H distribution for traditional Manhattan method and a worst case of velocity based using modified Manhattan method |
We can see as shown in Fig. 9 that dissimilarity increases as we increase the minimum velocity as expected. The speed of calculations also increases.
As shown, dissimilarity or error for Vmin less than 50%Vmax is no more than 5% during 100 steps of calculations. As Vmin increases, the speed of calculations increases but its error decreases. For Vmin = 75% Vmax a worst case is considered because the motion of 75% of nodes is neglected and so the error maximizes. In this case maximum dissimilarity is less than 11% for 90 steps. Figure 10 shows %H for traditional Manhattan method and this worst case of velocity based method using modified Manhattan measure. As shown, before 20th step, the accuracy of the worst case of our algorithm is better than traditional Manhattan method while dissimilarity in the next steps can be acceptable for some applications.
According to acceptable error and speed requirements for an application, refresh interval can be selected. For example if we need less than 5% dissimilarity, refresh interval can be selected 18 steps for Vmin = 75% Vmax or 80 steps for Vmin = 50% Vmax.
RESULTS AND DISCUSSION
In this study, a new approximate but fast method for computing connectivity graphs for dynamic networks has been presented. Connectivity graph computations for a normally distributed and a uniformly distributed network each with 1000 nodes have been compared. Three different methods were used for approximating connectivity: real method using Euclidean distance, traditional approximate method using Manhattan measure and our modified Manhattan measure using modified connectivity range, R. The results were compared with the real method to show the effectiveness of our proposed modification factor for Manhattan measure to reduce the approximation error.
Percentage Hamming distance (%H), degree distribution and mean degree distribution versus R are used as graph comparison metric and measures. Also computational time and accuracy of methods are used to compare the performance of methods.
In each network, degree distribution for a fixed R (R = 250 m), the mean degree of nodes for a range of R and connectivity matrices (graph) for every R were calculated using different approximating connectivity measures.
Static case: Performance of Manhattan measure is a function of R. In our experiment for R~0.75 km in uniform distribution and R~2.25 km in normal distribution, maximum dissimilarity exists between real and approximate Manhattan methods. Using modified approximate measure, maximum dissimilarity is for R ~ 2.1 km and R ~ 0.7 km in normal and uniform distributions, respectively.
Maximum dissimilarities using both approximate methods are nearly the same for both distributions and the performance for the modified Manhattan measure is much better as shown in Fig. 7. The results are summarized in Table 1. Dissimilarities of approximate methods are shown as %H. The results obtained show an appreciable improvement in accuracy using our modified Manhattan measure.
Also the rms error for our modified Manhattan method is decreased. This is shown by comparing max. rms error and rms error curve limited area of methods. Max. rms error is decreased by 5.43 and 7.16 times for uniform and normal distribution of nodes, respectively as shown in Fig. 6 and summarized in Table 2.
Table 3 shows rms error curve limited area of methods. The rms error curve limited area in using Manhattan measure with modified R, is reduced by 7.17 and 5.94 times for normal and uniform distributions, respectively as shown in Table 3. This measure requires less calculations with respect to Euclidean measure while it shows better accuracy with respect to traditional Manhattan method.
Dynamic case: In the dynamic case where nodes move based on their velocity, our velocity based method has acceptable accuracy as shown in Fig. 9. Less than 5% dissimilarity during 100 steps of calculations for Vmin = 50% Vmax is acceptable accuracy while computational time is decreased appreciably. Calculation time for determining connectivity matrices using different methods for 1000 nodes was measured. Table 4 and 5 show the comparison of computational time for three methods for different repetition intervals between refreshes. Different repetition intervals can be chosen according to acceptable error and time limitations. The results shown in Table 4 and 5 show that our method can reduce the computational time required according to low speed population of nodes and repetition interval up to 14.64 times.
| Table 1: | Comparison of %H for different methods |
 | |
| Table 2: | Comparison of max. rms error for different methods |
 | |
| Table 3: | Comparison of rms error curve limited for different methods |
 | |
| Table 4: | Computational time of different methods for 100 steps of calculations |
 | |
| Table 5: | Computational time of different methods for 50 steps of calculations |
 | |
The results reported here have been obtained using Turbo C++ programming on an Intel Pentium D 3.00 GHz PC. Our method shows an increased accuracy (Table 1-3) and an appreciable saving in time consumption (Table 4, 5).
REFERENCES
- Barrett, C.L., M.V. Marathe, D.C. Engelhart and A. Sivasubramaniam, 2004. Approximating the connectivity between nodes when simulating large-scale mobile ad hoc radio networks. J. Syst. Software, 73: 63-74.
Direct Link - Guadiano, P. and B.T. Clough, 2003. Swarm intelligence: A new C2 paradigm with an application to control of swarms of UAVs. Proceedings of the 8th ICCTRS Command and Control Research and Technology Symposium, June 17-19, 2003, National Defence University, New York, USA., pp: 1-12.
Direct Link - Jadbabaie, A., L. Jie and A.S. Morse, 2003. Coordination of groups of mobile autonomous agents using nearest neighbor rules. IEEE Trans. Automat. Control, 48: 988-1001.
CrossRefDirect Link - Mesbahi, M., 2002. On a dynamic extension of the theory of graphs. Proceedings of the American Control Conference, May 8-10, 2002, Alaska, USA., pp: 1234-1239.
Direct Link - Muhammad, A., M. Ji and M. Egerstedt, 2006. Applications of connectivity graph processes in networked sensing and control. Lecture Notes Control Inform. Sci., 331: 69-82.
Direct Link - Muhammad, A. and M. Egerstedt, 2005. Connectivity graphs as models of local interactions. Applied Math. Comput., 168: 243-269.
Direct Link - Tanner, A., A. Jadbabaie and G. Pappas, 2003. Flocking in teams of nonholonomic agents. Lecture Notes Control Inform. Sci., 309: 229-239.
Direct Link